{"title":"通过相关性对齐和熵最小化实现无监督域适应的子域适应","authors":"Obsa Gilo, Jimson Mathew, Samrat Mondal, Rakesh Kumar Sandoniya","doi":"10.1007/s10044-024-01232-9","DOIUrl":null,"url":null,"abstract":"<p>Unsupervised domain adaptation (UDA) is a well-explored domain in transfer learning, finding applications across various real-world scenarios. The central challenge in UDA lies in addressing the domain shift between training (source) and testing (target) data distributions. This study focuses on image classification tasks within UDA, where label spaces are shared, but the target domain lacks labeled samples. Our primary objective revolves around mitigating the domain discrepancies between the source and target domains, ultimately facilitating robust generalization in the target domains. Domain adaptation techniques have traditionally concentrated on the global feature distribution to minimize disparities. However, these methods often need to pay more attention to crucial, domain-specific subdomain information within identical classification categories, challenging achieving the desired performance without fine-grained data. To tackle these challenges, we propose a unified framework, Subdomain Adaptation via Correlation Alignment with Entropy Minimization, for unsupervised domain adaptation. Our approach incorporates three advanced techniques: (1) Local Maximum Mean Discrepancy, which aligns the means of local feature subsets, capturing intrinsic subdomain alignments often missed by global alignment, (2) correlation alignment aimed at minimizing the correlation between domain distributions, and (3) entropy regularization applied to target domains to encourage low-density separation between categories. We validate our proposed methods through rigorous experimental evaluations and ablation studies on standard benchmark datasets. The results consistently demonstrate the superior performance of our approaches compared to existing state-of-the-art domain adaptation methods.</p>","PeriodicalId":54639,"journal":{"name":"Pattern Analysis and Applications","volume":"253 1","pages":""},"PeriodicalIF":2.0000,"publicationDate":"2024-02-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Subdomain adaptation via correlation alignment with entropy minimization for unsupervised domain adaptation\",\"authors\":\"Obsa Gilo, Jimson Mathew, Samrat Mondal, Rakesh Kumar Sandoniya\",\"doi\":\"10.1007/s10044-024-01232-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Unsupervised domain adaptation (UDA) is a well-explored domain in transfer learning, finding applications across various real-world scenarios. The central challenge in UDA lies in addressing the domain shift between training (source) and testing (target) data distributions. This study focuses on image classification tasks within UDA, where label spaces are shared, but the target domain lacks labeled samples. Our primary objective revolves around mitigating the domain discrepancies between the source and target domains, ultimately facilitating robust generalization in the target domains. Domain adaptation techniques have traditionally concentrated on the global feature distribution to minimize disparities. However, these methods often need to pay more attention to crucial, domain-specific subdomain information within identical classification categories, challenging achieving the desired performance without fine-grained data. To tackle these challenges, we propose a unified framework, Subdomain Adaptation via Correlation Alignment with Entropy Minimization, for unsupervised domain adaptation. Our approach incorporates three advanced techniques: (1) Local Maximum Mean Discrepancy, which aligns the means of local feature subsets, capturing intrinsic subdomain alignments often missed by global alignment, (2) correlation alignment aimed at minimizing the correlation between domain distributions, and (3) entropy regularization applied to target domains to encourage low-density separation between categories. We validate our proposed methods through rigorous experimental evaluations and ablation studies on standard benchmark datasets. The results consistently demonstrate the superior performance of our approaches compared to existing state-of-the-art domain adaptation methods.</p>\",\"PeriodicalId\":54639,\"journal\":{\"name\":\"Pattern Analysis and Applications\",\"volume\":\"253 1\",\"pages\":\"\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2024-02-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Pattern Analysis and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10044-024-01232-9\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pattern Analysis and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10044-024-01232-9","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
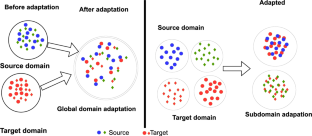
无监督领域适应(UDA)是迁移学习中一个被广泛探索的领域,在现实世界的各种场景中都有应用。UDA 的核心挑战在于解决训练(源)和测试(目标)数据分布之间的领域转换问题。本研究的重点是 UDA 中的图像分类任务,在这种任务中,标签空间是共享的,但目标域缺乏有标签的样本。我们的主要目标是减少源域和目标域之间的差异,最终促进目标域的稳健泛化。领域适应技术传统上集中在全局特征分布上,以尽量减少差异。然而,这些方法往往需要更多地关注相同分类类别中关键的、特定域的子域信息,这就对在没有细粒度数据的情况下实现理想性能提出了挑战。为了应对这些挑战,我们提出了一个统一的框架,即通过相关性对齐与熵最小化实现子域适应,用于无监督域适应。我们的方法融合了三种先进技术:(1) 局部最大均值差异(Local Maximum Mean Discrepancy),它对局部特征子集的均值进行对齐,捕捉全局对齐经常忽略的内在子域对齐;(2) 相关性对齐(Correlation Alignment),旨在最小化域分布之间的相关性;(3) 熵正则化(entropy regularization),应用于目标域,鼓励类别之间的低密度分离。我们在标准基准数据集上进行了严格的实验评估和消融研究,验证了我们提出的方法。结果一致表明,与现有的最先进的域适应方法相比,我们的方法具有卓越的性能。
Subdomain adaptation via correlation alignment with entropy minimization for unsupervised domain adaptation
Unsupervised domain adaptation (UDA) is a well-explored domain in transfer learning, finding applications across various real-world scenarios. The central challenge in UDA lies in addressing the domain shift between training (source) and testing (target) data distributions. This study focuses on image classification tasks within UDA, where label spaces are shared, but the target domain lacks labeled samples. Our primary objective revolves around mitigating the domain discrepancies between the source and target domains, ultimately facilitating robust generalization in the target domains. Domain adaptation techniques have traditionally concentrated on the global feature distribution to minimize disparities. However, these methods often need to pay more attention to crucial, domain-specific subdomain information within identical classification categories, challenging achieving the desired performance without fine-grained data. To tackle these challenges, we propose a unified framework, Subdomain Adaptation via Correlation Alignment with Entropy Minimization, for unsupervised domain adaptation. Our approach incorporates three advanced techniques: (1) Local Maximum Mean Discrepancy, which aligns the means of local feature subsets, capturing intrinsic subdomain alignments often missed by global alignment, (2) correlation alignment aimed at minimizing the correlation between domain distributions, and (3) entropy regularization applied to target domains to encourage low-density separation between categories. We validate our proposed methods through rigorous experimental evaluations and ablation studies on standard benchmark datasets. The results consistently demonstrate the superior performance of our approaches compared to existing state-of-the-art domain adaptation methods.
期刊介绍:
The journal publishes high quality articles in areas of fundamental research in intelligent pattern analysis and applications in computer science and engineering. It aims to provide a forum for original research which describes novel pattern analysis techniques and industrial applications of the current technology. In addition, the journal will also publish articles on pattern analysis applications in medical imaging. The journal solicits articles that detail new technology and methods for pattern recognition and analysis in applied domains including, but not limited to, computer vision and image processing, speech analysis, robotics, multimedia, document analysis, character recognition, knowledge engineering for pattern recognition, fractal analysis, and intelligent control. The journal publishes articles on the use of advanced pattern recognition and analysis methods including statistical techniques, neural networks, genetic algorithms, fuzzy pattern recognition, machine learning, and hardware implementations which are either relevant to the development of pattern analysis as a research area or detail novel pattern analysis applications. Papers proposing new classifier systems or their development, pattern analysis systems for real-time applications, fuzzy and temporal pattern recognition and uncertainty management in applied pattern recognition are particularly solicited.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
