{"title":"评估 Twitter 对低可信度内容的算法放大:一项观察研究","authors":"Giulio Corsi","doi":"10.1140/epjds/s13688-024-00456-3","DOIUrl":null,"url":null,"abstract":"<p>Artificial intelligence (AI)-powered recommender systems play a crucial role in determining the content that users are exposed to on social media platforms. However, the behavioural patterns of these systems are often opaque, complicating the evaluation of their impact on the dissemination and consumption of disinformation and misinformation. To begin addressing this evidence gap, this study presents a measurement approach that uses observed digital traces to infer the status of algorithmic amplification of low-credibility content on Twitter over a 14-day period in January 2023. Using an original dataset of ≈ 2.7 million posts on COVID-19 and climate change published on the platform, this study identifies tweets sharing information from low-credibility domains, and uses a bootstrapping model with two stratifications, a tweet’s engagement level and a user’s followers level, to compare any differences in impressions generated between low-credibility and high-credibility samples. Additional stratification variables of toxicity, political bias, and verified status are also examined. This analysis provides valuable observational evidence on whether the Twitter algorithm favours the visibility of low-credibility content, with results indicating that, on aggregate, tweets containing low-credibility URL domains perform better than tweets that do not across both datasets. However, this effect is largely attributable to a difference in high-engagement, high-followers tweets, which are very impactful in terms of impressions generation, and are more likely receive amplified visibility when containing low-credibility content. Furthermore, high toxicity tweets and those with right-leaning bias see heightened amplification, as do low-credibility tweets from verified accounts. Ultimately, this suggests that Twitter’s recommender system may have facilitated the diffusion of false content by amplifying the visibility of low-credibility content with high-engagement generated by very influential users.</p>","PeriodicalId":11887,"journal":{"name":"EPJ Data Science","volume":"27 1","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2024-03-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Evaluating Twitter’s algorithmic amplification of low-credibility content: an observational study\",\"authors\":\"Giulio Corsi\",\"doi\":\"10.1140/epjds/s13688-024-00456-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Artificial intelligence (AI)-powered recommender systems play a crucial role in determining the content that users are exposed to on social media platforms. However, the behavioural patterns of these systems are often opaque, complicating the evaluation of their impact on the dissemination and consumption of disinformation and misinformation. To begin addressing this evidence gap, this study presents a measurement approach that uses observed digital traces to infer the status of algorithmic amplification of low-credibility content on Twitter over a 14-day period in January 2023. Using an original dataset of ≈ 2.7 million posts on COVID-19 and climate change published on the platform, this study identifies tweets sharing information from low-credibility domains, and uses a bootstrapping model with two stratifications, a tweet’s engagement level and a user’s followers level, to compare any differences in impressions generated between low-credibility and high-credibility samples. Additional stratification variables of toxicity, political bias, and verified status are also examined. This analysis provides valuable observational evidence on whether the Twitter algorithm favours the visibility of low-credibility content, with results indicating that, on aggregate, tweets containing low-credibility URL domains perform better than tweets that do not across both datasets. However, this effect is largely attributable to a difference in high-engagement, high-followers tweets, which are very impactful in terms of impressions generation, and are more likely receive amplified visibility when containing low-credibility content. Furthermore, high toxicity tweets and those with right-leaning bias see heightened amplification, as do low-credibility tweets from verified accounts. Ultimately, this suggests that Twitter’s recommender system may have facilitated the diffusion of false content by amplifying the visibility of low-credibility content with high-engagement generated by very influential users.</p>\",\"PeriodicalId\":11887,\"journal\":{\"name\":\"EPJ Data Science\",\"volume\":\"27 1\",\"pages\":\"\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2024-03-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"EPJ Data Science\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1140/epjds/s13688-024-00456-3\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"EPJ Data Science","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1140/epjds/s13688-024-00456-3","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Evaluating Twitter’s algorithmic amplification of low-credibility content: an observational study
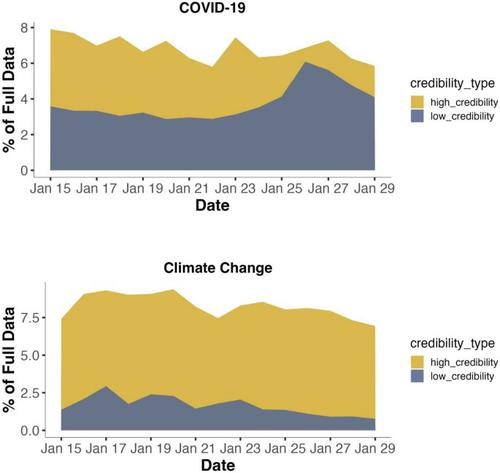
Artificial intelligence (AI)-powered recommender systems play a crucial role in determining the content that users are exposed to on social media platforms. However, the behavioural patterns of these systems are often opaque, complicating the evaluation of their impact on the dissemination and consumption of disinformation and misinformation. To begin addressing this evidence gap, this study presents a measurement approach that uses observed digital traces to infer the status of algorithmic amplification of low-credibility content on Twitter over a 14-day period in January 2023. Using an original dataset of ≈ 2.7 million posts on COVID-19 and climate change published on the platform, this study identifies tweets sharing information from low-credibility domains, and uses a bootstrapping model with two stratifications, a tweet’s engagement level and a user’s followers level, to compare any differences in impressions generated between low-credibility and high-credibility samples. Additional stratification variables of toxicity, political bias, and verified status are also examined. This analysis provides valuable observational evidence on whether the Twitter algorithm favours the visibility of low-credibility content, with results indicating that, on aggregate, tweets containing low-credibility URL domains perform better than tweets that do not across both datasets. However, this effect is largely attributable to a difference in high-engagement, high-followers tweets, which are very impactful in terms of impressions generation, and are more likely receive amplified visibility when containing low-credibility content. Furthermore, high toxicity tweets and those with right-leaning bias see heightened amplification, as do low-credibility tweets from verified accounts. Ultimately, this suggests that Twitter’s recommender system may have facilitated the diffusion of false content by amplifying the visibility of low-credibility content with high-engagement generated by very influential users.
期刊介绍:
EPJ Data Science covers a broad range of research areas and applications and particularly encourages contributions from techno-socio-economic systems, where it comprises those research lines that now regard the digital “tracks” of human beings as first-order objects for scientific investigation. Topics include, but are not limited to, human behavior, social interaction (including animal societies), economic and financial systems, management and business networks, socio-technical infrastructure, health and environmental systems, the science of science, as well as general risk and crisis scenario forecasting up to and including policy advice.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
