{"title":"智能算法下英语文本语义特征的提取与分析","authors":"Shuangshuang Yu","doi":"10.3103/S0146411624010115","DOIUrl":null,"url":null,"abstract":"<p>Accurate identification and analysis of semantics is beneficial for processing English texts effectively. This article briefly introduced Word2vec, which was used to extract semantic feature vectors from English texts, and the long short-term memory (LSTM) algorithm, which was used for semantic recognition of English texts. The relevant English comment texts were crawled from the Amazon movie database and used in a simulation experiment. The simulation experiment compared three algorithms: back propagation, recurrent neural network (RNN), and LSTM. The results showed that the LSTM algorithm’s recognition results for the part-of-speech and sentiment inclination of English texts were consistent with the label results. As the length of the English text increased, the recognition accuracy of all three algorithms decreased, and the LSTM algorithm had the smallest decrease. For the same length of English text, the LSTM algorithm had the highest accuracy in identifying part-of-speech and sentiment inclination, followed by the RNN algorithm, and the BP algorithm had the lowest. In terms of recognition time, the LSTM algorithm was the least.</p>","PeriodicalId":46238,"journal":{"name":"AUTOMATIC CONTROL AND COMPUTER SCIENCES","volume":"58 1","pages":"109 - 115"},"PeriodicalIF":0.5000,"publicationDate":"2024-03-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Extraction and Analysis of Semantic Features of English Texts under Intelligent Algorithms\",\"authors\":\"Shuangshuang Yu\",\"doi\":\"10.3103/S0146411624010115\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Accurate identification and analysis of semantics is beneficial for processing English texts effectively. This article briefly introduced Word2vec, which was used to extract semantic feature vectors from English texts, and the long short-term memory (LSTM) algorithm, which was used for semantic recognition of English texts. The relevant English comment texts were crawled from the Amazon movie database and used in a simulation experiment. The simulation experiment compared three algorithms: back propagation, recurrent neural network (RNN), and LSTM. The results showed that the LSTM algorithm’s recognition results for the part-of-speech and sentiment inclination of English texts were consistent with the label results. As the length of the English text increased, the recognition accuracy of all three algorithms decreased, and the LSTM algorithm had the smallest decrease. For the same length of English text, the LSTM algorithm had the highest accuracy in identifying part-of-speech and sentiment inclination, followed by the RNN algorithm, and the BP algorithm had the lowest. In terms of recognition time, the LSTM algorithm was the least.</p>\",\"PeriodicalId\":46238,\"journal\":{\"name\":\"AUTOMATIC CONTROL AND COMPUTER SCIENCES\",\"volume\":\"58 1\",\"pages\":\"109 - 115\"},\"PeriodicalIF\":0.5000,\"publicationDate\":\"2024-03-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"AUTOMATIC CONTROL AND COMPUTER SCIENCES\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://link.springer.com/article/10.3103/S0146411624010115\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"AUTOMATION & CONTROL SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"AUTOMATIC CONTROL AND COMPUTER SCIENCES","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.3103/S0146411624010115","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
Extraction and Analysis of Semantic Features of English Texts under Intelligent Algorithms
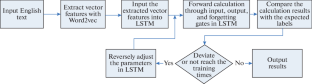
Accurate identification and analysis of semantics is beneficial for processing English texts effectively. This article briefly introduced Word2vec, which was used to extract semantic feature vectors from English texts, and the long short-term memory (LSTM) algorithm, which was used for semantic recognition of English texts. The relevant English comment texts were crawled from the Amazon movie database and used in a simulation experiment. The simulation experiment compared three algorithms: back propagation, recurrent neural network (RNN), and LSTM. The results showed that the LSTM algorithm’s recognition results for the part-of-speech and sentiment inclination of English texts were consistent with the label results. As the length of the English text increased, the recognition accuracy of all three algorithms decreased, and the LSTM algorithm had the smallest decrease. For the same length of English text, the LSTM algorithm had the highest accuracy in identifying part-of-speech and sentiment inclination, followed by the RNN algorithm, and the BP algorithm had the lowest. In terms of recognition time, the LSTM algorithm was the least.
期刊介绍:
Automatic Control and Computer Sciences is a peer reviewed journal that publishes articles on• Control systems, cyber-physical system, real-time systems, robotics, smart sensors, embedded intelligence • Network information technologies, information security, statistical methods of data processing, distributed artificial intelligence, complex systems modeling, knowledge representation, processing and management • Signal and image processing, machine learning, machine perception, computer vision





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
