{"title":"半监督行动建议生成时态教师与遮蔽变换器","authors":"Selen Pehlivan, Jorma Laaksonen","doi":"10.1007/s00138-024-01521-7","DOIUrl":null,"url":null,"abstract":"<p>By conditioning on unit-level predictions, anchor-free models for action proposal generation have displayed impressive capabilities, such as having a lightweight architecture. However, task performance depends significantly on the quality of data used in training, and most effective models have relied on human-annotated data. Semi-supervised learning, i.e., jointly training deep neural networks with a labeled dataset as well as an unlabeled dataset, has made significant progress recently. Existing works have either primarily focused on classification tasks, which may require less annotation effort, or considered anchor-based detection models. Inspired by recent advances in semi-supervised methods on anchor-free object detectors, we propose a teacher-student framework for a two-stage action detection pipeline, named Temporal Teacher with Masked Transformers (TTMT), to generate high-quality action proposals based on an anchor-free transformer model. Leveraging consistency learning as one self-training technique, the model jointly trains an anchor-free student model and a gradually progressing teacher counterpart in a mutually beneficial manner. As the core model, we design a Transformer-based anchor-free model to improve effectiveness for temporal evaluation. We integrate bi-directional masks and devise encoder-only Masked Transformers for sequences. Jointly training on boundary locations and various local snippet-based features, our model predicts via the proposed scoring function for generating proposal candidates. Experiments on the THUMOS14 and ActivityNet-1.3 benchmarks demonstrate the effectiveness of our model for temporal proposal generation task.</p>","PeriodicalId":51116,"journal":{"name":"Machine Vision and Applications","volume":"67 1","pages":""},"PeriodicalIF":2.3000,"publicationDate":"2024-03-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Temporal teacher with masked transformers for semi-supervised action proposal generation\",\"authors\":\"Selen Pehlivan, Jorma Laaksonen\",\"doi\":\"10.1007/s00138-024-01521-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>By conditioning on unit-level predictions, anchor-free models for action proposal generation have displayed impressive capabilities, such as having a lightweight architecture. However, task performance depends significantly on the quality of data used in training, and most effective models have relied on human-annotated data. Semi-supervised learning, i.e., jointly training deep neural networks with a labeled dataset as well as an unlabeled dataset, has made significant progress recently. Existing works have either primarily focused on classification tasks, which may require less annotation effort, or considered anchor-based detection models. Inspired by recent advances in semi-supervised methods on anchor-free object detectors, we propose a teacher-student framework for a two-stage action detection pipeline, named Temporal Teacher with Masked Transformers (TTMT), to generate high-quality action proposals based on an anchor-free transformer model. Leveraging consistency learning as one self-training technique, the model jointly trains an anchor-free student model and a gradually progressing teacher counterpart in a mutually beneficial manner. As the core model, we design a Transformer-based anchor-free model to improve effectiveness for temporal evaluation. We integrate bi-directional masks and devise encoder-only Masked Transformers for sequences. Jointly training on boundary locations and various local snippet-based features, our model predicts via the proposed scoring function for generating proposal candidates. Experiments on the THUMOS14 and ActivityNet-1.3 benchmarks demonstrate the effectiveness of our model for temporal proposal generation task.</p>\",\"PeriodicalId\":51116,\"journal\":{\"name\":\"Machine Vision and Applications\",\"volume\":\"67 1\",\"pages\":\"\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2024-03-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Machine Vision and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00138-024-01521-7\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Machine Vision and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00138-024-01521-7","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Temporal teacher with masked transformers for semi-supervised action proposal generation
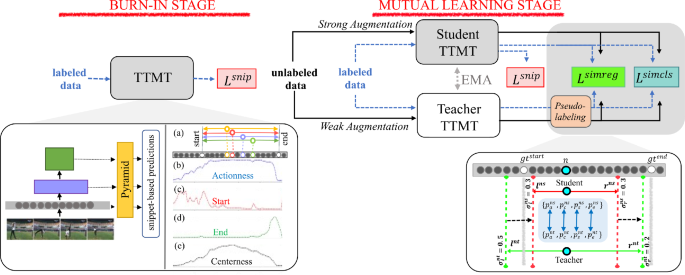
By conditioning on unit-level predictions, anchor-free models for action proposal generation have displayed impressive capabilities, such as having a lightweight architecture. However, task performance depends significantly on the quality of data used in training, and most effective models have relied on human-annotated data. Semi-supervised learning, i.e., jointly training deep neural networks with a labeled dataset as well as an unlabeled dataset, has made significant progress recently. Existing works have either primarily focused on classification tasks, which may require less annotation effort, or considered anchor-based detection models. Inspired by recent advances in semi-supervised methods on anchor-free object detectors, we propose a teacher-student framework for a two-stage action detection pipeline, named Temporal Teacher with Masked Transformers (TTMT), to generate high-quality action proposals based on an anchor-free transformer model. Leveraging consistency learning as one self-training technique, the model jointly trains an anchor-free student model and a gradually progressing teacher counterpart in a mutually beneficial manner. As the core model, we design a Transformer-based anchor-free model to improve effectiveness for temporal evaluation. We integrate bi-directional masks and devise encoder-only Masked Transformers for sequences. Jointly training on boundary locations and various local snippet-based features, our model predicts via the proposed scoring function for generating proposal candidates. Experiments on the THUMOS14 and ActivityNet-1.3 benchmarks demonstrate the effectiveness of our model for temporal proposal generation task.
期刊介绍:
Machine Vision and Applications publishes high-quality technical contributions in machine vision research and development. Specifically, the editors encourage submittals in all applications and engineering aspects of image-related computing. In particular, original contributions dealing with scientific, commercial, industrial, military, and biomedical applications of machine vision, are all within the scope of the journal.
Particular emphasis is placed on engineering and technology aspects of image processing and computer vision.
The following aspects of machine vision applications are of interest: algorithms, architectures, VLSI implementations, AI techniques and expert systems for machine vision, front-end sensing, multidimensional and multisensor machine vision, real-time techniques, image databases, virtual reality and visualization. Papers must include a significant experimental validation component.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
