Bingli Zhang, Yixin Wang, Chengbiao Zhang, Junzhao Jiang, Zehao Pan, Jin Cheng, Yangyang Zhang, Xinyu Wang, Chenglei Yang, Yanhui Wang
{"title":"AFMCT:基于跨模态变换块的自适应融合模块,用于三维物体检测","authors":"Bingli Zhang, Yixin Wang, Chengbiao Zhang, Junzhao Jiang, Zehao Pan, Jin Cheng, Yangyang Zhang, Xinyu Wang, Chenglei Yang, Yanhui Wang","doi":"10.1007/s00138-024-01509-3","DOIUrl":null,"url":null,"abstract":"<p>Lidar and camera are essential sensors for environment perception in autonomous driving. However, fully fusing heterogeneous data from multiple sources remains a non-trivial challenge. As a result, 3D object detection based on multi-modal sensor fusion are often inferior to single-modal methods only based on Lidar, which indicates that multi-sensor machine vision still needs development. In this paper, we propose an adaptive fusion module based on cross-modal transformer block(AFMCT) for 3D object detection by utilizing a bidirectional enhancing strategy. Specifically, we first enhance image feature by extracting an attention-based point feature based on a cross-modal transformer block and linking them in a concatenation fashion, followed by another cross-modal transformer block acting on the enhanced image feature to strengthen the point feature with image semantic information. Extensive experiments operated on the 3D detection benchmark of the KITTI dataset reveal that our proposed structure can significantly improve the detection accuracy of Lidar-only methods and outperform the existing advanced multi-sensor fusion modules by at least 0.45%, which indicates that our method might be a feasible solution to improving 3D object detection based on multi-sensor fusion.</p>","PeriodicalId":51116,"journal":{"name":"Machine Vision and Applications","volume":"30 1","pages":""},"PeriodicalIF":2.4000,"publicationDate":"2024-03-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"AFMCT: adaptive fusion module based on cross-modal transformer block for 3D object detection\",\"authors\":\"Bingli Zhang, Yixin Wang, Chengbiao Zhang, Junzhao Jiang, Zehao Pan, Jin Cheng, Yangyang Zhang, Xinyu Wang, Chenglei Yang, Yanhui Wang\",\"doi\":\"10.1007/s00138-024-01509-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Lidar and camera are essential sensors for environment perception in autonomous driving. However, fully fusing heterogeneous data from multiple sources remains a non-trivial challenge. As a result, 3D object detection based on multi-modal sensor fusion are often inferior to single-modal methods only based on Lidar, which indicates that multi-sensor machine vision still needs development. In this paper, we propose an adaptive fusion module based on cross-modal transformer block(AFMCT) for 3D object detection by utilizing a bidirectional enhancing strategy. Specifically, we first enhance image feature by extracting an attention-based point feature based on a cross-modal transformer block and linking them in a concatenation fashion, followed by another cross-modal transformer block acting on the enhanced image feature to strengthen the point feature with image semantic information. Extensive experiments operated on the 3D detection benchmark of the KITTI dataset reveal that our proposed structure can significantly improve the detection accuracy of Lidar-only methods and outperform the existing advanced multi-sensor fusion modules by at least 0.45%, which indicates that our method might be a feasible solution to improving 3D object detection based on multi-sensor fusion.</p>\",\"PeriodicalId\":51116,\"journal\":{\"name\":\"Machine Vision and Applications\",\"volume\":\"30 1\",\"pages\":\"\"},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2024-03-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Machine Vision and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00138-024-01509-3\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Machine Vision and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00138-024-01509-3","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
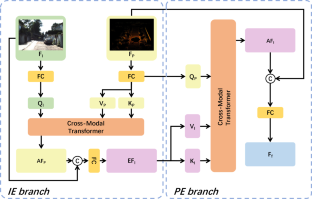
激光雷达和摄像头是自动驾驶环境感知的重要传感器。然而,如何充分融合来自多个来源的异构数据仍是一项艰巨的挑战。因此,基于多模态传感器融合的 3D 物体检测往往不如仅基于激光雷达的单模态方法,这表明多传感器机器视觉仍有待发展。本文提出了一种基于跨模态变换块(AFMCT)的自适应融合模块,利用双向增强策略进行三维物体检测。具体来说,我们首先通过提取基于跨模态变换块的注意力点特征来增强图像特征,并以串联的方式将它们连接起来;然后,另一个跨模态变换块作用于增强后的图像特征,以图像语义信息来强化点特征。在 KITTI 数据集的三维检测基准上进行的大量实验表明,我们提出的结构可以显著提高纯激光雷达方法的检测精度,比现有的先进多传感器融合模块至少高出 0.45%,这表明我们的方法可能是基于多传感器融合改进三维物体检测的可行解决方案。
AFMCT: adaptive fusion module based on cross-modal transformer block for 3D object detection
Lidar and camera are essential sensors for environment perception in autonomous driving. However, fully fusing heterogeneous data from multiple sources remains a non-trivial challenge. As a result, 3D object detection based on multi-modal sensor fusion are often inferior to single-modal methods only based on Lidar, which indicates that multi-sensor machine vision still needs development. In this paper, we propose an adaptive fusion module based on cross-modal transformer block(AFMCT) for 3D object detection by utilizing a bidirectional enhancing strategy. Specifically, we first enhance image feature by extracting an attention-based point feature based on a cross-modal transformer block and linking them in a concatenation fashion, followed by another cross-modal transformer block acting on the enhanced image feature to strengthen the point feature with image semantic information. Extensive experiments operated on the 3D detection benchmark of the KITTI dataset reveal that our proposed structure can significantly improve the detection accuracy of Lidar-only methods and outperform the existing advanced multi-sensor fusion modules by at least 0.45%, which indicates that our method might be a feasible solution to improving 3D object detection based on multi-sensor fusion.
期刊介绍:
Machine Vision and Applications publishes high-quality technical contributions in machine vision research and development. Specifically, the editors encourage submittals in all applications and engineering aspects of image-related computing. In particular, original contributions dealing with scientific, commercial, industrial, military, and biomedical applications of machine vision, are all within the scope of the journal.
Particular emphasis is placed on engineering and technology aspects of image processing and computer vision.
The following aspects of machine vision applications are of interest: algorithms, architectures, VLSI implementations, AI techniques and expert systems for machine vision, front-end sensing, multidimensional and multisensor machine vision, real-time techniques, image databases, virtual reality and visualization. Papers must include a significant experimental validation component.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
