{"title":"名义变量和序数变量非对称对应分析的变体","authors":"Riya R. Jain, Kirtee K. Kamalja","doi":"10.1007/s42952-023-00253-0","DOIUrl":null,"url":null,"abstract":"<p>Non-symmetric correspondence analysis (NSCA) is a multivariate data analysis technique that has gained increasing attention in recent years. NSCA is an extension of traditional correspondence analysis that allows for the analysis of asymmetric association between two or more categorical variables. NSCA involves graphically depicting the one-way relationship between variables cross classified in a contingency table through a biplot. This paper provides a comprehensive overview of the popular approaches of NSCA developed over the years. Some fundamental variations in the family of NSCA such as Simple NSCA, Doubly Ordered NSCA, Singly Ordered NSCA, Three-way Nominal NSCA, Triply Ordered NSCA etc. are discussed thoroughly. A systematic step-by-step algorithms for each variant of NSCA and their demonstrations are neatly presented. Further a summary of NSCA variants in literature, the concise tabular presentation of R-packages developed for variants of CA/NSCA and a collection of variety of datasets where NSCA is performed are the key features of the paper. Moreover, we compare and contrast the method of NSCA with multinomial logistic regression (MNLR) to discuss some disparities between both the approaches. The paper aims to provide the theoretical, practical and computational issues of NSCA in structured manner and to highlight the further challenges with reference to NSCA.</p>","PeriodicalId":49992,"journal":{"name":"Journal of the Korean Statistical Society","volume":"160 1","pages":""},"PeriodicalIF":0.8000,"publicationDate":"2024-03-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Variants of non-symmetric correspondence analysis for nominal and ordinal variables\",\"authors\":\"Riya R. Jain, Kirtee K. Kamalja\",\"doi\":\"10.1007/s42952-023-00253-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Non-symmetric correspondence analysis (NSCA) is a multivariate data analysis technique that has gained increasing attention in recent years. NSCA is an extension of traditional correspondence analysis that allows for the analysis of asymmetric association between two or more categorical variables. NSCA involves graphically depicting the one-way relationship between variables cross classified in a contingency table through a biplot. This paper provides a comprehensive overview of the popular approaches of NSCA developed over the years. Some fundamental variations in the family of NSCA such as Simple NSCA, Doubly Ordered NSCA, Singly Ordered NSCA, Three-way Nominal NSCA, Triply Ordered NSCA etc. are discussed thoroughly. A systematic step-by-step algorithms for each variant of NSCA and their demonstrations are neatly presented. Further a summary of NSCA variants in literature, the concise tabular presentation of R-packages developed for variants of CA/NSCA and a collection of variety of datasets where NSCA is performed are the key features of the paper. Moreover, we compare and contrast the method of NSCA with multinomial logistic regression (MNLR) to discuss some disparities between both the approaches. The paper aims to provide the theoretical, practical and computational issues of NSCA in structured manner and to highlight the further challenges with reference to NSCA.</p>\",\"PeriodicalId\":49992,\"journal\":{\"name\":\"Journal of the Korean Statistical Society\",\"volume\":\"160 1\",\"pages\":\"\"},\"PeriodicalIF\":0.8000,\"publicationDate\":\"2024-03-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of the Korean Statistical Society\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://doi.org/10.1007/s42952-023-00253-0\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the Korean Statistical Society","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1007/s42952-023-00253-0","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
Variants of non-symmetric correspondence analysis for nominal and ordinal variables
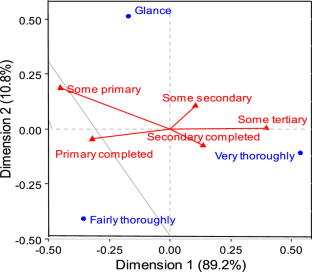
Non-symmetric correspondence analysis (NSCA) is a multivariate data analysis technique that has gained increasing attention in recent years. NSCA is an extension of traditional correspondence analysis that allows for the analysis of asymmetric association between two or more categorical variables. NSCA involves graphically depicting the one-way relationship between variables cross classified in a contingency table through a biplot. This paper provides a comprehensive overview of the popular approaches of NSCA developed over the years. Some fundamental variations in the family of NSCA such as Simple NSCA, Doubly Ordered NSCA, Singly Ordered NSCA, Three-way Nominal NSCA, Triply Ordered NSCA etc. are discussed thoroughly. A systematic step-by-step algorithms for each variant of NSCA and their demonstrations are neatly presented. Further a summary of NSCA variants in literature, the concise tabular presentation of R-packages developed for variants of CA/NSCA and a collection of variety of datasets where NSCA is performed are the key features of the paper. Moreover, we compare and contrast the method of NSCA with multinomial logistic regression (MNLR) to discuss some disparities between both the approaches. The paper aims to provide the theoretical, practical and computational issues of NSCA in structured manner and to highlight the further challenges with reference to NSCA.
期刊介绍:
The Journal of the Korean Statistical Society publishes research articles that make original contributions to the theory and methodology of statistics and probability. It also welcomes papers on innovative applications of statistical methodology, as well as papers that give an overview of current topic of statistical research with judgements about promising directions for future work. The journal welcomes contributions from all countries.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
