Dario Malchiodi, Davide Raimondi, Giacomo Fumagalli, Raffaele Giancarlo, Marco Frasca
{"title":"分类器和数据复杂性在学习型布鲁姆过滤器中的作用:见解和建议","authors":"Dario Malchiodi, Davide Raimondi, Giacomo Fumagalli, Raffaele Giancarlo, Marco Frasca","doi":"10.1186/s40537-024-00906-9","DOIUrl":null,"url":null,"abstract":"<p>Bloom filters, since their introduction over 50 years ago, have become a pillar to handle membership queries in small space, with relevant application in Big Data Mining and Stream Processing. Further improvements have been recently proposed with the use of Machine Learning techniques: learned Bloom filters. Those latter make considerably more complicated the proper parameter setting of this multi-criteria data structure, in particular in regard to the choice of one of its key components (the classifier) and accounting for the classification complexity of the input dataset. Given this State of the Art, our contributions are as follows. (1) A novel methodology, supported by software, for designing, analyzing and implementing learned Bloom filters that account for their own multi-criteria nature, in particular concerning classifier type choice and data classification complexity. Extensive experiments show the validity of the proposed methodology and, being our software public, we offer a valid tool to the practitioners interested in using learned Bloom filters. (2) Further contributions to the advancement of the State of the Art that are of great practical relevance are the following: (a) the classifier inference time should not be taken as a proxy for the filter reject time; (b) of the many classifiers we have considered, only two offer good performance; this result is in agreement with and further strengthens early findings in the literature; (c) Sandwiched Bloom filter, which is already known as being one of the references of this area, is further shown here to have the remarkable property of robustness to data complexity and classifier performance variability.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"5 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-03-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"The role of classifiers and data complexity in learned Bloom filters: insights and recommendations\",\"authors\":\"Dario Malchiodi, Davide Raimondi, Giacomo Fumagalli, Raffaele Giancarlo, Marco Frasca\",\"doi\":\"10.1186/s40537-024-00906-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Bloom filters, since their introduction over 50 years ago, have become a pillar to handle membership queries in small space, with relevant application in Big Data Mining and Stream Processing. Further improvements have been recently proposed with the use of Machine Learning techniques: learned Bloom filters. Those latter make considerably more complicated the proper parameter setting of this multi-criteria data structure, in particular in regard to the choice of one of its key components (the classifier) and accounting for the classification complexity of the input dataset. Given this State of the Art, our contributions are as follows. (1) A novel methodology, supported by software, for designing, analyzing and implementing learned Bloom filters that account for their own multi-criteria nature, in particular concerning classifier type choice and data classification complexity. Extensive experiments show the validity of the proposed methodology and, being our software public, we offer a valid tool to the practitioners interested in using learned Bloom filters. (2) Further contributions to the advancement of the State of the Art that are of great practical relevance are the following: (a) the classifier inference time should not be taken as a proxy for the filter reject time; (b) of the many classifiers we have considered, only two offer good performance; this result is in agreement with and further strengthens early findings in the literature; (c) Sandwiched Bloom filter, which is already known as being one of the references of this area, is further shown here to have the remarkable property of robustness to data complexity and classifier performance variability.</p>\",\"PeriodicalId\":15158,\"journal\":{\"name\":\"Journal of Big Data\",\"volume\":\"5 1\",\"pages\":\"\"},\"PeriodicalIF\":6.4000,\"publicationDate\":\"2024-03-27\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Big Data\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s40537-024-00906-9\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-024-00906-9","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
The role of classifiers and data complexity in learned Bloom filters: insights and recommendations
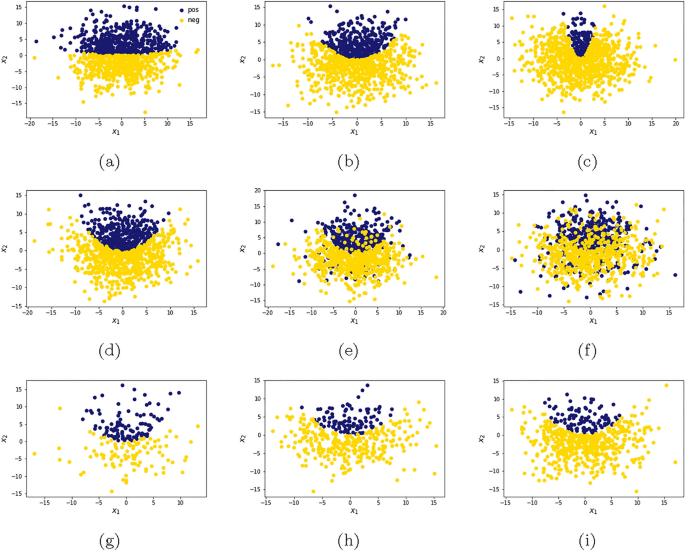
Bloom filters, since their introduction over 50 years ago, have become a pillar to handle membership queries in small space, with relevant application in Big Data Mining and Stream Processing. Further improvements have been recently proposed with the use of Machine Learning techniques: learned Bloom filters. Those latter make considerably more complicated the proper parameter setting of this multi-criteria data structure, in particular in regard to the choice of one of its key components (the classifier) and accounting for the classification complexity of the input dataset. Given this State of the Art, our contributions are as follows. (1) A novel methodology, supported by software, for designing, analyzing and implementing learned Bloom filters that account for their own multi-criteria nature, in particular concerning classifier type choice and data classification complexity. Extensive experiments show the validity of the proposed methodology and, being our software public, we offer a valid tool to the practitioners interested in using learned Bloom filters. (2) Further contributions to the advancement of the State of the Art that are of great practical relevance are the following: (a) the classifier inference time should not be taken as a proxy for the filter reject time; (b) of the many classifiers we have considered, only two offer good performance; this result is in agreement with and further strengthens early findings in the literature; (c) Sandwiched Bloom filter, which is already known as being one of the references of this area, is further shown here to have the remarkable property of robustness to data complexity and classifier performance variability.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
