Angela T. Chen MA, Richard S. Kuzma MPP, Ari B. Friedman MD, PhD
{"title":"用机器学习方法识别急诊科低危就诊者:低危急值就诊算法(LAVA)。","authors":"Angela T. Chen MA, Richard S. Kuzma MPP, Ari B. Friedman MD, PhD","doi":"10.1111/1475-6773.14305","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Objective</h3>\n \n <p>To improve the performance of International Classification of Disease (ICD) code rule-based algorithms for identifying low acuity Emergency Department (ED) visits by using machine learning methods and additional covariates.</p>\n </section>\n \n <section>\n \n <h3> Data Sources</h3>\n \n <p>We used secondary data on ED visits from the National Hospital Ambulatory Medical Survey (NHAMCS), from 2016 to 2020.</p>\n </section>\n \n <section>\n \n <h3> Study Design</h3>\n \n <p>We established baseline performance metrics with seven published algorithms consisting of International Classification of Disease, Tenth Revision codes used to identify low acuity ED visits. We then trained logistic regression, random forest, and gradient boosting (XGBoost) models to predict low acuity ED visits. Each model was trained on five different covariate sets of demographic and clinical data. Model performance was compared using a separate validation dataset. The primary performance metric was the probability that a visit identified by an algorithm as low acuity did not experience significant testing, treatment, or disposition (positive predictive value, PPV). Subgroup analyses assessed model performance across age, sex, and race/ethnicity.</p>\n </section>\n \n <section>\n \n <h3> Data Collection</h3>\n \n <p>We used 2016–2019 NHAMCS data as the training set and 2020 NHAMCS data for validation.</p>\n </section>\n \n <section>\n \n <h3> Principal Findings</h3>\n \n <p>The training and validation data consisted of 53,074 and 9542 observations, respectively. Among seven rule-based algorithms, the highest-performing had a PPV of 0.35 (95% CI [0.33, 0.36]). All model-based algorithms outperformed existing algorithms, with the least effective—random forest using only age and sex—improving PPV by 26% (up to 0.44; 95% CI [0.40, 0.48]). Logistic regression and XGBoost trained on all variables improved PPV by 83% (to 0.64; 95% CI [0.62, 0.66]). Multivariable models also demonstrated higher PPV across all three demographic subgroups.</p>\n </section>\n \n <section>\n \n <h3> Conclusions</h3>\n \n <p>Machine learning models substantially outperform existing algorithms based on ICD codes in predicting low acuity ED visits. Variations in model performance across demographic groups highlight the need for further research to ensure their applicability and fairness across diverse populations.</p>\n </section>\n </div>","PeriodicalId":55065,"journal":{"name":"Health Services Research","volume":"59 4","pages":""},"PeriodicalIF":3.2000,"publicationDate":"2024-03-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/1475-6773.14305","citationCount":"0","resultStr":"{\"title\":\"Identifying low acuity Emergency Department visits with a machine learning approach: The low acuity visit algorithms (LAVA)\",\"authors\":\"Angela T. Chen MA, Richard S. Kuzma MPP, Ari B. Friedman MD, PhD\",\"doi\":\"10.1111/1475-6773.14305\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Objective</h3>\\n \\n <p>To improve the performance of International Classification of Disease (ICD) code rule-based algorithms for identifying low acuity Emergency Department (ED) visits by using machine learning methods and additional covariates.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Data Sources</h3>\\n \\n <p>We used secondary data on ED visits from the National Hospital Ambulatory Medical Survey (NHAMCS), from 2016 to 2020.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Study Design</h3>\\n \\n <p>We established baseline performance metrics with seven published algorithms consisting of International Classification of Disease, Tenth Revision codes used to identify low acuity ED visits. We then trained logistic regression, random forest, and gradient boosting (XGBoost) models to predict low acuity ED visits. Each model was trained on five different covariate sets of demographic and clinical data. Model performance was compared using a separate validation dataset. The primary performance metric was the probability that a visit identified by an algorithm as low acuity did not experience significant testing, treatment, or disposition (positive predictive value, PPV). Subgroup analyses assessed model performance across age, sex, and race/ethnicity.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Data Collection</h3>\\n \\n <p>We used 2016–2019 NHAMCS data as the training set and 2020 NHAMCS data for validation.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Principal Findings</h3>\\n \\n <p>The training and validation data consisted of 53,074 and 9542 observations, respectively. Among seven rule-based algorithms, the highest-performing had a PPV of 0.35 (95% CI [0.33, 0.36]). All model-based algorithms outperformed existing algorithms, with the least effective—random forest using only age and sex—improving PPV by 26% (up to 0.44; 95% CI [0.40, 0.48]). Logistic regression and XGBoost trained on all variables improved PPV by 83% (to 0.64; 95% CI [0.62, 0.66]). Multivariable models also demonstrated higher PPV across all three demographic subgroups.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Conclusions</h3>\\n \\n <p>Machine learning models substantially outperform existing algorithms based on ICD codes in predicting low acuity ED visits. Variations in model performance across demographic groups highlight the need for further research to ensure their applicability and fairness across diverse populations.</p>\\n </section>\\n </div>\",\"PeriodicalId\":55065,\"journal\":{\"name\":\"Health Services Research\",\"volume\":\"59 4\",\"pages\":\"\"},\"PeriodicalIF\":3.2000,\"publicationDate\":\"2024-03-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/1475-6773.14305\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Health Services Research\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/1475-6773.14305\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Health Services Research","FirstCategoryId":"3","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/1475-6773.14305","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
摘要
目的通过使用机器学习方法和额外的协变量,提高基于国际疾病分类(ICD)代码规则的算法的性能,以识别急诊科(ED)就诊率低的情况:研究设计:我们使用七种已发布的算法建立了基线性能指标,这些算法由《国际疾病分类》第十版代码组成,用于识别急诊室就诊的低敏锐度患者。然后,我们训练了逻辑回归、随机森林和梯度提升 (XGBoost) 模型来预测低敏锐度急诊就诊情况。每个模型都是根据人口统计学和临床数据的五个不同协变量集进行训练的。使用单独的验证数据集对模型性能进行了比较。主要性能指标是被算法识别为低敏锐度的就诊者未接受重要检查、治疗或处置的概率(阳性预测值,PPV)。分组分析评估了不同年龄、性别和种族/民族的模型性能:我们使用2016-2019年NHAMCS数据作为训练集,2020年NHAMCS数据作为验证集:训练数据和验证数据分别包含 53074 个和 9542 个观测值。在七种基于规则的算法中,表现最好的算法的PPV为0.35(95% CI [0.33,0.36])。所有基于模型的算法都优于现有算法,其中效果最差的算法--仅使用年龄和性别的随机森林--将 PPV 提高了 26%(高达 0.44;95% CI [0.40,0.48])。根据所有变量训练的逻辑回归和 XGBoost 使 PPV 提高了 83%(达到 0.64;95% CI [0.62,0.66])。多变量模型在所有三个人口统计亚组中也显示出更高的 PPV:结论:机器学习模型在预测急诊室低急诊就诊率方面大大优于基于 ICD 代码的现有算法。模型在不同人群中的表现差异凸显了进一步研究的必要性,以确保其在不同人群中的适用性和公平性。
Identifying low acuity Emergency Department visits with a machine learning approach: The low acuity visit algorithms (LAVA)
Objective
To improve the performance of International Classification of Disease (ICD) code rule-based algorithms for identifying low acuity Emergency Department (ED) visits by using machine learning methods and additional covariates.
Data Sources
We used secondary data on ED visits from the National Hospital Ambulatory Medical Survey (NHAMCS), from 2016 to 2020.
Study Design
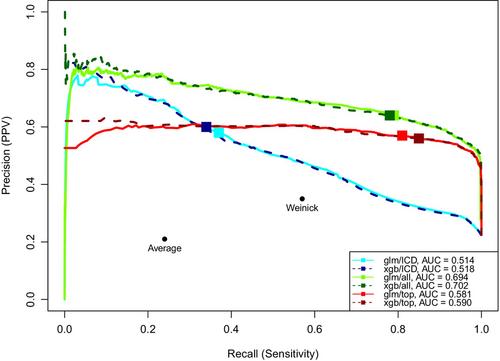
We established baseline performance metrics with seven published algorithms consisting of International Classification of Disease, Tenth Revision codes used to identify low acuity ED visits. We then trained logistic regression, random forest, and gradient boosting (XGBoost) models to predict low acuity ED visits. Each model was trained on five different covariate sets of demographic and clinical data. Model performance was compared using a separate validation dataset. The primary performance metric was the probability that a visit identified by an algorithm as low acuity did not experience significant testing, treatment, or disposition (positive predictive value, PPV). Subgroup analyses assessed model performance across age, sex, and race/ethnicity.
Data Collection
We used 2016–2019 NHAMCS data as the training set and 2020 NHAMCS data for validation.
Principal Findings
The training and validation data consisted of 53,074 and 9542 observations, respectively. Among seven rule-based algorithms, the highest-performing had a PPV of 0.35 (95% CI [0.33, 0.36]). All model-based algorithms outperformed existing algorithms, with the least effective—random forest using only age and sex—improving PPV by 26% (up to 0.44; 95% CI [0.40, 0.48]). Logistic regression and XGBoost trained on all variables improved PPV by 83% (to 0.64; 95% CI [0.62, 0.66]). Multivariable models also demonstrated higher PPV across all three demographic subgroups.
Conclusions
Machine learning models substantially outperform existing algorithms based on ICD codes in predicting low acuity ED visits. Variations in model performance across demographic groups highlight the need for further research to ensure their applicability and fairness across diverse populations.
期刊介绍:
Health Services Research (HSR) is a peer-reviewed scholarly journal that provides researchers and public and private policymakers with the latest research findings, methods, and concepts related to the financing, organization, delivery, evaluation, and outcomes of health services. Rated as one of the top journals in the fields of health policy and services and health care administration, HSR publishes outstanding articles reporting the findings of original investigations that expand knowledge and understanding of the wide-ranging field of health care and that will help to improve the health of individuals and communities.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
