{"title":"CoRT:基于变换器的代码表示法,通过预测保留字进行自我监督,用于代码气味检测","authors":"Amal Alazba, Hamoud Aljamaan, Mohammad Alshayeb","doi":"10.1007/s10664-024-10445-9","DOIUrl":null,"url":null,"abstract":"<h3 data-test=\"abstract-sub-heading\">Context</h3><p>Code smell detection is the process of identifying poorly designed and implemented code pieces. Machine learning-based approaches require enormous amounts of manually labeled data, which are costly and difficult to scale. Unsupervised semantic feature learning, or learning without manual annotation, is vital for effectively harvesting an enormous amount of available data.</p><h3 data-test=\"abstract-sub-heading\">Objective</h3><p>The objective of this study is to propose a new code smell detection approach that utilizes self-supervised learning to learn intermediate representations without the need for labels and then fine-tune these representations on multiple tasks.</p><h3 data-test=\"abstract-sub-heading\">Method</h3><p>We propose a Code Representation with Transformers (CoRT) to learn the semantic and structural features of the source code by training transformers to recognize masked reserved words that are applied to the code given as input. We empirically demonstrated that the defined proxy task provides a powerful method for learning semantic and structural features. We exhaustively evaluated our approach on four downstream tasks: detection of the Data Class, God Class, Feature Envy, and Long Method code smells. Moreover, we compare our results with those of two paradigms: supervised learning and a feature-based approach. Finally, we conducted a cross-project experiment to evaluate the generalizability of our method to unseen labeled data.</p><h3 data-test=\"abstract-sub-heading\">Results</h3><p>The results indicate that the proposed method has a high detection performance for code smells. For instance, the detection performance of CoRT on Data Class achieved a score of F1 between 88.08–99.4, Area Under Curve (AUC) between 89.62–99.88, and Matthews Correlation Coefficient (MCC) between 75.28–98.8, while God Class achieved a value of F1 ranges from 86.32–99.03, AUC of 92.1–99.85, and MCC of 76.15–98.09. Compared with the baseline model and feature-based approach, CoRT achieved better detection performance and had a high capability to detect code smells in unseen datasets.</p><h3 data-test=\"abstract-sub-heading\">Conclusions</h3><p>The proposed method has been shown to be effective in detecting class-level, and method-level code smells.</p>","PeriodicalId":11525,"journal":{"name":"Empirical Software Engineering","volume":"48 1","pages":""},"PeriodicalIF":3.6000,"publicationDate":"2024-04-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"CoRT: Transformer-based code representations with self-supervision by predicting reserved words for code smell detection\",\"authors\":\"Amal Alazba, Hamoud Aljamaan, Mohammad Alshayeb\",\"doi\":\"10.1007/s10664-024-10445-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<h3 data-test=\\\"abstract-sub-heading\\\">Context</h3><p>Code smell detection is the process of identifying poorly designed and implemented code pieces. Machine learning-based approaches require enormous amounts of manually labeled data, which are costly and difficult to scale. Unsupervised semantic feature learning, or learning without manual annotation, is vital for effectively harvesting an enormous amount of available data.</p><h3 data-test=\\\"abstract-sub-heading\\\">Objective</h3><p>The objective of this study is to propose a new code smell detection approach that utilizes self-supervised learning to learn intermediate representations without the need for labels and then fine-tune these representations on multiple tasks.</p><h3 data-test=\\\"abstract-sub-heading\\\">Method</h3><p>We propose a Code Representation with Transformers (CoRT) to learn the semantic and structural features of the source code by training transformers to recognize masked reserved words that are applied to the code given as input. We empirically demonstrated that the defined proxy task provides a powerful method for learning semantic and structural features. We exhaustively evaluated our approach on four downstream tasks: detection of the Data Class, God Class, Feature Envy, and Long Method code smells. Moreover, we compare our results with those of two paradigms: supervised learning and a feature-based approach. Finally, we conducted a cross-project experiment to evaluate the generalizability of our method to unseen labeled data.</p><h3 data-test=\\\"abstract-sub-heading\\\">Results</h3><p>The results indicate that the proposed method has a high detection performance for code smells. For instance, the detection performance of CoRT on Data Class achieved a score of F1 between 88.08–99.4, Area Under Curve (AUC) between 89.62–99.88, and Matthews Correlation Coefficient (MCC) between 75.28–98.8, while God Class achieved a value of F1 ranges from 86.32–99.03, AUC of 92.1–99.85, and MCC of 76.15–98.09. Compared with the baseline model and feature-based approach, CoRT achieved better detection performance and had a high capability to detect code smells in unseen datasets.</p><h3 data-test=\\\"abstract-sub-heading\\\">Conclusions</h3><p>The proposed method has been shown to be effective in detecting class-level, and method-level code smells.</p>\",\"PeriodicalId\":11525,\"journal\":{\"name\":\"Empirical Software Engineering\",\"volume\":\"48 1\",\"pages\":\"\"},\"PeriodicalIF\":3.6000,\"publicationDate\":\"2024-04-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Empirical Software Engineering\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10664-024-10445-9\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Empirical Software Engineering","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10664-024-10445-9","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
摘要
ContextCode smell detection 是识别设计和实施不当的代码片段的过程。基于机器学习的方法需要大量人工标注的数据,成本高昂且难以扩展。本研究的目的是提出一种新的代码气味检测方法,该方法利用自我监督学习来学习中间表征,而无需标签,然后在多个任务中对这些表征进行微调。方法我们提出了一种带转换器的代码表征(Code Representation with Transformers,CoRT),通过训练转换器来学习源代码的语义和结构特征,从而识别作为输入应用于代码的屏蔽保留字。我们通过经验证明,定义的代理任务为学习语义和结构特征提供了一种强大的方法。我们在四个下游任务中对我们的方法进行了详尽的评估:检测数据类、上帝类、特征嫉妒和长方法代码气味。此外,我们还将我们的结果与两种范例进行了比较:监督学习和基于特征的方法。最后,我们进行了一次跨项目实验,以评估我们的方法对未见标注数据的普适性。结果结果表明,所提出的方法对代码气味具有很高的检测性能。例如,CoRT 对数据类的检测性能达到了 88.08-99.4 之间的 F1 值、89.62-99.88 之间的曲线下面积(AUC)和 75.28-98.8 之间的马修斯相关系数(MCC),而对上帝类的检测性能达到了 86.32-99.03 之间的 F1 值、92.1-99.85 之间的 AUC 值和 76.15-98.09 之间的 MCC 值。与基线模型和基于特征的方法相比,CoRT 取得了更好的检测性能,在未见过的数据集中具有很高的代码气味检测能力。
CoRT: Transformer-based code representations with self-supervision by predicting reserved words for code smell detection
Context
Code smell detection is the process of identifying poorly designed and implemented code pieces. Machine learning-based approaches require enormous amounts of manually labeled data, which are costly and difficult to scale. Unsupervised semantic feature learning, or learning without manual annotation, is vital for effectively harvesting an enormous amount of available data.
Objective
The objective of this study is to propose a new code smell detection approach that utilizes self-supervised learning to learn intermediate representations without the need for labels and then fine-tune these representations on multiple tasks.
Method
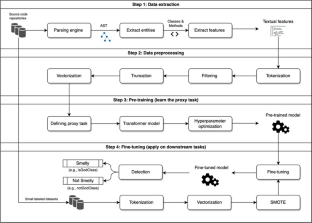
We propose a Code Representation with Transformers (CoRT) to learn the semantic and structural features of the source code by training transformers to recognize masked reserved words that are applied to the code given as input. We empirically demonstrated that the defined proxy task provides a powerful method for learning semantic and structural features. We exhaustively evaluated our approach on four downstream tasks: detection of the Data Class, God Class, Feature Envy, and Long Method code smells. Moreover, we compare our results with those of two paradigms: supervised learning and a feature-based approach. Finally, we conducted a cross-project experiment to evaluate the generalizability of our method to unseen labeled data.
Results
The results indicate that the proposed method has a high detection performance for code smells. For instance, the detection performance of CoRT on Data Class achieved a score of F1 between 88.08–99.4, Area Under Curve (AUC) between 89.62–99.88, and Matthews Correlation Coefficient (MCC) between 75.28–98.8, while God Class achieved a value of F1 ranges from 86.32–99.03, AUC of 92.1–99.85, and MCC of 76.15–98.09. Compared with the baseline model and feature-based approach, CoRT achieved better detection performance and had a high capability to detect code smells in unseen datasets.
Conclusions
The proposed method has been shown to be effective in detecting class-level, and method-level code smells.
期刊介绍:
Empirical Software Engineering provides a forum for applied software engineering research with a strong empirical component, and a venue for publishing empirical results relevant to both researchers and practitioners. Empirical studies presented here usually involve the collection and analysis of data and experience that can be used to characterize, evaluate and reveal relationships between software development deliverables, practices, and technologies. Over time, it is expected that such empirical results will form a body of knowledge leading to widely accepted and well-formed theories.
The journal also offers industrial experience reports detailing the application of software technologies - processes, methods, or tools - and their effectiveness in industrial settings.
Empirical Software Engineering promotes the publication of industry-relevant research, to address the significant gap between research and practice.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
