{"title":"乳腺癌人工智能模型开发的公共数据同质化","authors":"Vassilis Kilintzis, Varvara Kalokyri, Haridimos Kondylakis, Smriti Joshi, Katerina Nikiforaki, Oliver Díaz, Karim Lekadir, Manolis Tsiknakis, Kostas Marias","doi":"10.1186/s41747-024-00442-4","DOIUrl":null,"url":null,"abstract":"<h3 data-test=\"abstract-sub-heading\">Background</h3><p>Developing trustworthy artificial intelligence (AI) models for clinical applications requires access to clinical and imaging data cohorts. Reusing of publicly available datasets has the potential to fill this gap. Specifically in the domain of breast cancer, a large archive of publicly accessible medical images along with the corresponding clinical data is available at The Cancer Imaging Archive (TCIA). However, existing datasets cannot be directly used as they are heterogeneous and cannot be effectively filtered for selecting specific image types required to develop AI models. This work focuses on the development of a homogenized dataset in the domain of breast cancer including clinical and imaging data.</p><h3 data-test=\"abstract-sub-heading\">Methods</h3><p>Five datasets were acquired from the TCIA and were harmonized. For the clinical data harmonization, a common data model was developed and a repeatable, documented “extract-transform-load” process was defined and executed for their homogenization. Further, Digital Imaging and COmmunications in Medicine (DICOM) information was extracted from magnetic resonance imaging (MRI) data and made accessible and searchable.</p><h3 data-test=\"abstract-sub-heading\">Results</h3><p>The resulting harmonized dataset includes information about 2,035 subjects with breast cancer. Further, a platform named RV-Cherry-Picker enables search over both the clinical and diagnostic imaging datasets, providing unified access, facilitating the downloading of all study imaging that correspond to specific series’ characteristics (<i>e.g.</i>, dynamic contrast-enhanced series), and reducing the burden of acquiring the appropriate set of images for the respective AI model scenario.</p><h3 data-test=\"abstract-sub-heading\">Conclusions</h3><p>RV-Cherry-Picker provides access to the largest, publicly available, homogenized, imaging/clinical dataset for breast cancer to develop AI models on top.</p><h3 data-test=\"abstract-sub-heading\">Relevance statement</h3><p>We present a solution for creating merged public datasets supporting AI model development, using as an example the breast cancer domain and magnetic resonance imaging images.</p><h3 data-test=\"abstract-sub-heading\">Key points</h3><p>• The proposed platform allows unified access to the largest, homogenized public imaging dataset for breast cancer.</p><p>• A methodology for the semantically enriched homogenization of public clinical data is presented.</p><p>• The platform is able to make a detailed selection of breast MRI data for the development of AI models.</p><h3 data-test=\"abstract-sub-heading\">Graphical Abstract</h3>\n","PeriodicalId":36926,"journal":{"name":"European Radiology Experimental","volume":"50 1","pages":""},"PeriodicalIF":3.6000,"publicationDate":"2024-04-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Public data homogenization for AI model development in breast cancer\",\"authors\":\"Vassilis Kilintzis, Varvara Kalokyri, Haridimos Kondylakis, Smriti Joshi, Katerina Nikiforaki, Oliver Díaz, Karim Lekadir, Manolis Tsiknakis, Kostas Marias\",\"doi\":\"10.1186/s41747-024-00442-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<h3 data-test=\\\"abstract-sub-heading\\\">Background</h3><p>Developing trustworthy artificial intelligence (AI) models for clinical applications requires access to clinical and imaging data cohorts. Reusing of publicly available datasets has the potential to fill this gap. Specifically in the domain of breast cancer, a large archive of publicly accessible medical images along with the corresponding clinical data is available at The Cancer Imaging Archive (TCIA). However, existing datasets cannot be directly used as they are heterogeneous and cannot be effectively filtered for selecting specific image types required to develop AI models. This work focuses on the development of a homogenized dataset in the domain of breast cancer including clinical and imaging data.</p><h3 data-test=\\\"abstract-sub-heading\\\">Methods</h3><p>Five datasets were acquired from the TCIA and were harmonized. For the clinical data harmonization, a common data model was developed and a repeatable, documented “extract-transform-load” process was defined and executed for their homogenization. Further, Digital Imaging and COmmunications in Medicine (DICOM) information was extracted from magnetic resonance imaging (MRI) data and made accessible and searchable.</p><h3 data-test=\\\"abstract-sub-heading\\\">Results</h3><p>The resulting harmonized dataset includes information about 2,035 subjects with breast cancer. Further, a platform named RV-Cherry-Picker enables search over both the clinical and diagnostic imaging datasets, providing unified access, facilitating the downloading of all study imaging that correspond to specific series’ characteristics (<i>e.g.</i>, dynamic contrast-enhanced series), and reducing the burden of acquiring the appropriate set of images for the respective AI model scenario.</p><h3 data-test=\\\"abstract-sub-heading\\\">Conclusions</h3><p>RV-Cherry-Picker provides access to the largest, publicly available, homogenized, imaging/clinical dataset for breast cancer to develop AI models on top.</p><h3 data-test=\\\"abstract-sub-heading\\\">Relevance statement</h3><p>We present a solution for creating merged public datasets supporting AI model development, using as an example the breast cancer domain and magnetic resonance imaging images.</p><h3 data-test=\\\"abstract-sub-heading\\\">Key points</h3><p>• The proposed platform allows unified access to the largest, homogenized public imaging dataset for breast cancer.</p><p>• A methodology for the semantically enriched homogenization of public clinical data is presented.</p><p>• The platform is able to make a detailed selection of breast MRI data for the development of AI models.</p><h3 data-test=\\\"abstract-sub-heading\\\">Graphical Abstract</h3>\\n\",\"PeriodicalId\":36926,\"journal\":{\"name\":\"European Radiology Experimental\",\"volume\":\"50 1\",\"pages\":\"\"},\"PeriodicalIF\":3.6000,\"publicationDate\":\"2024-04-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"European Radiology Experimental\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1186/s41747-024-00442-4\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"European Radiology Experimental","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41747-024-00442-4","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
Public data homogenization for AI model development in breast cancer
Background
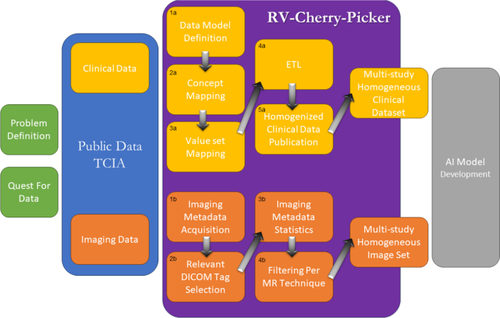
Developing trustworthy artificial intelligence (AI) models for clinical applications requires access to clinical and imaging data cohorts. Reusing of publicly available datasets has the potential to fill this gap. Specifically in the domain of breast cancer, a large archive of publicly accessible medical images along with the corresponding clinical data is available at The Cancer Imaging Archive (TCIA). However, existing datasets cannot be directly used as they are heterogeneous and cannot be effectively filtered for selecting specific image types required to develop AI models. This work focuses on the development of a homogenized dataset in the domain of breast cancer including clinical and imaging data.
Methods
Five datasets were acquired from the TCIA and were harmonized. For the clinical data harmonization, a common data model was developed and a repeatable, documented “extract-transform-load” process was defined and executed for their homogenization. Further, Digital Imaging and COmmunications in Medicine (DICOM) information was extracted from magnetic resonance imaging (MRI) data and made accessible and searchable.
Results
The resulting harmonized dataset includes information about 2,035 subjects with breast cancer. Further, a platform named RV-Cherry-Picker enables search over both the clinical and diagnostic imaging datasets, providing unified access, facilitating the downloading of all study imaging that correspond to specific series’ characteristics (e.g., dynamic contrast-enhanced series), and reducing the burden of acquiring the appropriate set of images for the respective AI model scenario.
Conclusions
RV-Cherry-Picker provides access to the largest, publicly available, homogenized, imaging/clinical dataset for breast cancer to develop AI models on top.
Relevance statement
We present a solution for creating merged public datasets supporting AI model development, using as an example the breast cancer domain and magnetic resonance imaging images.
Key points
• The proposed platform allows unified access to the largest, homogenized public imaging dataset for breast cancer.
• A methodology for the semantically enriched homogenization of public clinical data is presented.
• The platform is able to make a detailed selection of breast MRI data for the development of AI models.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
