Daniel Rodriguez-Criado, Pilar Bachiller-Burgos, George Vogiatzis, Luis J. Manso
{"title":"从无标签数据中估算多人三维姿态","authors":"Daniel Rodriguez-Criado, Pilar Bachiller-Burgos, George Vogiatzis, Luis J. Manso","doi":"10.1007/s00138-024-01530-6","DOIUrl":null,"url":null,"abstract":"<p>Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, it presents several challenges, especially when approached using multiple views and regular RGB cameras as the only input. First, each person must be uniquely identified in the different views. Secondly, it must be robust to noise, partial occlusions, and views where a person may not be detected. Thirdly, many pose estimation approaches rely on environment-specific annotated datasets that are frequently prohibitively expensive and/or require specialised hardware. Specifically, this is the first multi-camera, multi-person data-driven approach that does not require an annotated dataset. In this work, we address these three challenges with the help of self-supervised learning. In particular, we present a three-staged pipeline and a rigorous evaluation providing evidence that our approach performs faster than other state-of-the-art algorithms, with comparable accuracy, and most importantly, does not require annotated datasets. The pipeline is composed of a 2D skeleton detection step, followed by a Graph Neural Network to estimate cross-view correspondences of the people in the scenario, and a Multi-Layer Perceptron that transforms the 2D information into 3D pose estimations. Our proposal comprises the last two steps, and it is compatible with any 2D skeleton detector as input. These two models are trained in a self-supervised manner, thus avoiding the need for datasets annotated with 3D ground-truth poses.</p>","PeriodicalId":51116,"journal":{"name":"Machine Vision and Applications","volume":"40 1","pages":""},"PeriodicalIF":2.3000,"publicationDate":"2024-04-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Multi-person 3D pose estimation from unlabelled data\",\"authors\":\"Daniel Rodriguez-Criado, Pilar Bachiller-Burgos, George Vogiatzis, Luis J. Manso\",\"doi\":\"10.1007/s00138-024-01530-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, it presents several challenges, especially when approached using multiple views and regular RGB cameras as the only input. First, each person must be uniquely identified in the different views. Secondly, it must be robust to noise, partial occlusions, and views where a person may not be detected. Thirdly, many pose estimation approaches rely on environment-specific annotated datasets that are frequently prohibitively expensive and/or require specialised hardware. Specifically, this is the first multi-camera, multi-person data-driven approach that does not require an annotated dataset. In this work, we address these three challenges with the help of self-supervised learning. In particular, we present a three-staged pipeline and a rigorous evaluation providing evidence that our approach performs faster than other state-of-the-art algorithms, with comparable accuracy, and most importantly, does not require annotated datasets. The pipeline is composed of a 2D skeleton detection step, followed by a Graph Neural Network to estimate cross-view correspondences of the people in the scenario, and a Multi-Layer Perceptron that transforms the 2D information into 3D pose estimations. Our proposal comprises the last two steps, and it is compatible with any 2D skeleton detector as input. These two models are trained in a self-supervised manner, thus avoiding the need for datasets annotated with 3D ground-truth poses.</p>\",\"PeriodicalId\":51116,\"journal\":{\"name\":\"Machine Vision and Applications\",\"volume\":\"40 1\",\"pages\":\"\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2024-04-06\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Machine Vision and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00138-024-01530-6\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Machine Vision and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00138-024-01530-6","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Multi-person 3D pose estimation from unlabelled data
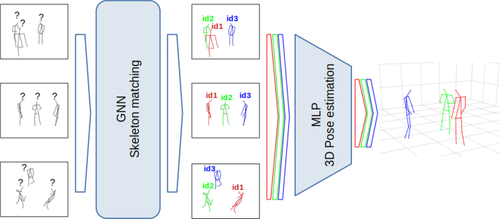
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, it presents several challenges, especially when approached using multiple views and regular RGB cameras as the only input. First, each person must be uniquely identified in the different views. Secondly, it must be robust to noise, partial occlusions, and views where a person may not be detected. Thirdly, many pose estimation approaches rely on environment-specific annotated datasets that are frequently prohibitively expensive and/or require specialised hardware. Specifically, this is the first multi-camera, multi-person data-driven approach that does not require an annotated dataset. In this work, we address these three challenges with the help of self-supervised learning. In particular, we present a three-staged pipeline and a rigorous evaluation providing evidence that our approach performs faster than other state-of-the-art algorithms, with comparable accuracy, and most importantly, does not require annotated datasets. The pipeline is composed of a 2D skeleton detection step, followed by a Graph Neural Network to estimate cross-view correspondences of the people in the scenario, and a Multi-Layer Perceptron that transforms the 2D information into 3D pose estimations. Our proposal comprises the last two steps, and it is compatible with any 2D skeleton detector as input. These two models are trained in a self-supervised manner, thus avoiding the need for datasets annotated with 3D ground-truth poses.
期刊介绍:
Machine Vision and Applications publishes high-quality technical contributions in machine vision research and development. Specifically, the editors encourage submittals in all applications and engineering aspects of image-related computing. In particular, original contributions dealing with scientific, commercial, industrial, military, and biomedical applications of machine vision, are all within the scope of the journal.
Particular emphasis is placed on engineering and technology aspects of image processing and computer vision.
The following aspects of machine vision applications are of interest: algorithms, architectures, VLSI implementations, AI techniques and expert systems for machine vision, front-end sensing, multidimensional and multisensor machine vision, real-time techniques, image databases, virtual reality and visualization. Papers must include a significant experimental validation component.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
