{"title":"大数据的多维扩展","authors":"Pedro Delicado, Cristian Pachón-García","doi":"10.1007/s11634-024-00591-9","DOIUrl":null,"url":null,"abstract":"<div><p>We present a set of algorithms implementing multidimensional scaling (MDS) for large data sets. MDS is a family of dimensionality reduction techniques using a <span>\\(n \\times n\\)</span> distance matrix as input, where <i>n</i> is the number of individuals, and producing a low dimensional configuration: a <span>\\(n\\times r\\)</span> matrix with <span>\\(r<<n\\)</span>. When <i>n</i> is large, MDS is unaffordable with classical MDS algorithms because their extremely large memory and time requirements. We compare six non-standard algorithms intended to overcome these difficulties. They are based on the central idea of partitioning the data set into small pieces, where classical MDS methods can work. Two of these algorithms are original proposals. In order to check the performance of the algorithms as well as to compare them, we have done a simulation study. Additionally, we have used the algorithms to obtain an MDS configuration for EMNIST: a real large data set with more than 800000 points. We conclude that all the algorithms are appropriate to use for obtaining an MDS configuration, but we recommend to use one of our proposals, since it is a fast algorithm with satisfactory statistical properties when working with big data. An <span>R</span> package implementing the algorithms has been created.</p></div>","PeriodicalId":49270,"journal":{"name":"Advances in Data Analysis and Classification","volume":"19 3","pages":"649 - 670"},"PeriodicalIF":1.3000,"publicationDate":"2024-04-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s11634-024-00591-9.pdf","citationCount":"0","resultStr":"{\"title\":\"Multidimensional scaling for big data\",\"authors\":\"Pedro Delicado, Cristian Pachón-García\",\"doi\":\"10.1007/s11634-024-00591-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>We present a set of algorithms implementing multidimensional scaling (MDS) for large data sets. MDS is a family of dimensionality reduction techniques using a <span>\\\\(n \\\\times n\\\\)</span> distance matrix as input, where <i>n</i> is the number of individuals, and producing a low dimensional configuration: a <span>\\\\(n\\\\times r\\\\)</span> matrix with <span>\\\\(r<<n\\\\)</span>. When <i>n</i> is large, MDS is unaffordable with classical MDS algorithms because their extremely large memory and time requirements. We compare six non-standard algorithms intended to overcome these difficulties. They are based on the central idea of partitioning the data set into small pieces, where classical MDS methods can work. Two of these algorithms are original proposals. In order to check the performance of the algorithms as well as to compare them, we have done a simulation study. Additionally, we have used the algorithms to obtain an MDS configuration for EMNIST: a real large data set with more than 800000 points. We conclude that all the algorithms are appropriate to use for obtaining an MDS configuration, but we recommend to use one of our proposals, since it is a fast algorithm with satisfactory statistical properties when working with big data. An <span>R</span> package implementing the algorithms has been created.</p></div>\",\"PeriodicalId\":49270,\"journal\":{\"name\":\"Advances in Data Analysis and Classification\",\"volume\":\"19 3\",\"pages\":\"649 - 670\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2024-04-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s11634-024-00591-9.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advances in Data Analysis and Classification\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s11634-024-00591-9\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Data Analysis and Classification","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s11634-024-00591-9","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
引用次数: 0
摘要
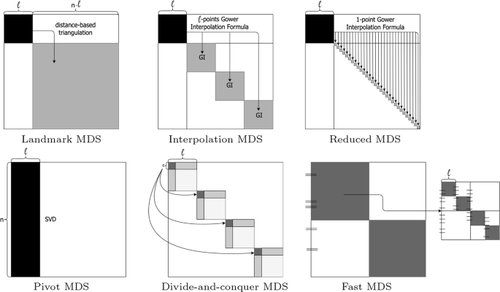
我们提出了一套为大型数据集实现多维缩放(MDS)的算法。MDS 是一系列降维技术,使用一个 \(n \times n\) 距离矩阵作为输入,其中 n 是个体的数量,并产生一个低维配置:一个 \(r<<n\) 的 \(n \times r\) 矩阵。当 n 较大时,经典的 MDS 算法由于内存和时间要求极高而难以承受。我们比较了六种旨在克服这些困难的非标准算法。这些算法的核心思想是将数据集分割成小块,这样经典的 MDS 方法就能发挥作用。其中两种算法是原创提案。为了检验这些算法的性能并进行比较,我们进行了模拟研究。此外,我们还使用这些算法获得了 EMNIST 的 MDS 配置:一个拥有超过 800000 个点的真实大型数据集。我们的结论是,所有算法都适合用于获取 MDS 配置,但我们建议使用我们的建议之一,因为它是一种快速算法,在处理大数据时具有令人满意的统计特性。我们创建了一个实现这些算法的 R 软件包。
We present a set of algorithms implementing multidimensional scaling (MDS) for large data sets. MDS is a family of dimensionality reduction techniques using a \(n \times n\) distance matrix as input, where n is the number of individuals, and producing a low dimensional configuration: a \(n\times r\) matrix with \(r<<n\). When n is large, MDS is unaffordable with classical MDS algorithms because their extremely large memory and time requirements. We compare six non-standard algorithms intended to overcome these difficulties. They are based on the central idea of partitioning the data set into small pieces, where classical MDS methods can work. Two of these algorithms are original proposals. In order to check the performance of the algorithms as well as to compare them, we have done a simulation study. Additionally, we have used the algorithms to obtain an MDS configuration for EMNIST: a real large data set with more than 800000 points. We conclude that all the algorithms are appropriate to use for obtaining an MDS configuration, but we recommend to use one of our proposals, since it is a fast algorithm with satisfactory statistical properties when working with big data. An R package implementing the algorithms has been created.
期刊介绍:
The international journal Advances in Data Analysis and Classification (ADAC) is designed as a forum for high standard publications on research and applications concerning the extraction of knowable aspects from many types of data. It publishes articles on such topics as structural, quantitative, or statistical approaches for the analysis of data; advances in classification, clustering, and pattern recognition methods; strategies for modeling complex data and mining large data sets; methods for the extraction of knowledge from data, and applications of advanced methods in specific domains of practice. Articles illustrate how new domain-specific knowledge can be made available from data by skillful use of data analysis methods. The journal also publishes survey papers that outline, and illuminate the basic ideas and techniques of special approaches.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
