Lijie Xu, Shuang Qiu, Binhang Yuan, Jiawei Jiang, Cedric Renggli, Shaoduo Gan, Kaan Kara, Guoliang Li, Ji Liu, Wentao Wu, Jieping Ye, Ce Zhang
{"title":"无需完全数据洗牌的随机梯度下降:在数据库内机器学习和深度学习系统中的应用","authors":"Lijie Xu, Shuang Qiu, Binhang Yuan, Jiawei Jiang, Cedric Renggli, Shaoduo Gan, Kaan Kara, Guoliang Li, Ji Liu, Wentao Wu, Jieping Ye, Ce Zhang","doi":"10.1007/s00778-024-00845-0","DOIUrl":null,"url":null,"abstract":"<p>Modern machine learning (ML) systems commonly use stochastic gradient descent (SGD) to train ML models. However, SGD relies on random data order to converge, which usually requires a full data shuffle. For in-DB ML systems and deep learning systems with large datasets stored on <i>block-addressable secondary storage</i> such as HDD and SSD, this full data shuffle leads to low I/O performance—the data shuffling time can be even longer than the training itself, due to massive random data accesses. To balance the convergence rate of SGD (which favors data randomness) and its I/O performance (which favors sequential access), previous work has proposed several data shuffling strategies. In this paper, we first perform an empirical study on existing data shuffling strategies, showing that these strategies suffer from either low performance or low convergence rate. To solve this problem, we propose a simple but novel <i>two-level</i> data shuffling strategy named <span>CorgiPile</span>, which can <i>avoid</i> a full data shuffle while maintaining <i>comparable</i> convergence rate of SGD as if a full shuffle were performed. We further theoretically analyze the convergence behavior of <span>CorgiPile</span> and empirically evaluate its efficacy in both in-DB ML and deep learning systems. For in-DB ML systems, we integrate <span>CorgiPile</span> into PostgreSQL by introducing three new <i>physical</i> operators with optimizations. For deep learning systems, we extend single-process <span>CorgiPile</span> to multi-process <span>CorgiPile</span> for the parallel/distributed environment and integrate it into PyTorch. Our evaluation shows that <span>CorgiPile</span> can achieve comparable convergence rate with the full-shuffle-based SGD for both linear models and deep learning models. For in-DB ML with linear models, <span>CorgiPile</span> is 1.6<span>\\(\\times \\)</span> <span>\\(-\\)</span>12.8<span>\\(\\times \\)</span> faster than two state-of-the-art systems, Apache MADlib and Bismarck, on both HDD and SSD. For deep learning models on ImageNet, <span>CorgiPile</span> is 1.5<span>\\(\\times \\)</span> faster than PyTorch with full data shuffle.</p>","PeriodicalId":501532,"journal":{"name":"The VLDB Journal","volume":"44 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-04-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Stochastic gradient descent without full data shuffle: with applications to in-database machine learning and deep learning systems\",\"authors\":\"Lijie Xu, Shuang Qiu, Binhang Yuan, Jiawei Jiang, Cedric Renggli, Shaoduo Gan, Kaan Kara, Guoliang Li, Ji Liu, Wentao Wu, Jieping Ye, Ce Zhang\",\"doi\":\"10.1007/s00778-024-00845-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Modern machine learning (ML) systems commonly use stochastic gradient descent (SGD) to train ML models. However, SGD relies on random data order to converge, which usually requires a full data shuffle. For in-DB ML systems and deep learning systems with large datasets stored on <i>block-addressable secondary storage</i> such as HDD and SSD, this full data shuffle leads to low I/O performance—the data shuffling time can be even longer than the training itself, due to massive random data accesses. To balance the convergence rate of SGD (which favors data randomness) and its I/O performance (which favors sequential access), previous work has proposed several data shuffling strategies. In this paper, we first perform an empirical study on existing data shuffling strategies, showing that these strategies suffer from either low performance or low convergence rate. To solve this problem, we propose a simple but novel <i>two-level</i> data shuffling strategy named <span>CorgiPile</span>, which can <i>avoid</i> a full data shuffle while maintaining <i>comparable</i> convergence rate of SGD as if a full shuffle were performed. We further theoretically analyze the convergence behavior of <span>CorgiPile</span> and empirically evaluate its efficacy in both in-DB ML and deep learning systems. For in-DB ML systems, we integrate <span>CorgiPile</span> into PostgreSQL by introducing three new <i>physical</i> operators with optimizations. For deep learning systems, we extend single-process <span>CorgiPile</span> to multi-process <span>CorgiPile</span> for the parallel/distributed environment and integrate it into PyTorch. Our evaluation shows that <span>CorgiPile</span> can achieve comparable convergence rate with the full-shuffle-based SGD for both linear models and deep learning models. For in-DB ML with linear models, <span>CorgiPile</span> is 1.6<span>\\\\(\\\\times \\\\)</span> <span>\\\\(-\\\\)</span>12.8<span>\\\\(\\\\times \\\\)</span> faster than two state-of-the-art systems, Apache MADlib and Bismarck, on both HDD and SSD. For deep learning models on ImageNet, <span>CorgiPile</span> is 1.5<span>\\\\(\\\\times \\\\)</span> faster than PyTorch with full data shuffle.</p>\",\"PeriodicalId\":501532,\"journal\":{\"name\":\"The VLDB Journal\",\"volume\":\"44 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-04-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"The VLDB Journal\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s00778-024-00845-0\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"The VLDB Journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00778-024-00845-0","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Stochastic gradient descent without full data shuffle: with applications to in-database machine learning and deep learning systems
Modern machine learning (ML) systems commonly use stochastic gradient descent (SGD) to train ML models. However, SGD relies on random data order to converge, which usually requires a full data shuffle. For in-DB ML systems and deep learning systems with large datasets stored on block-addressable secondary storage such as HDD and SSD, this full data shuffle leads to low I/O performance—the data shuffling time can be even longer than the training itself, due to massive random data accesses. To balance the convergence rate of SGD (which favors data randomness) and its I/O performance (which favors sequential access), previous work has proposed several data shuffling strategies. In this paper, we first perform an empirical study on existing data shuffling strategies, showing that these strategies suffer from either low performance or low convergence rate. To solve this problem, we propose a simple but novel two-level data shuffling strategy named CorgiPile, which can avoid a full data shuffle while maintaining comparable convergence rate of SGD as if a full shuffle were performed. We further theoretically analyze the convergence behavior of CorgiPile and empirically evaluate its efficacy in both in-DB ML and deep learning systems. For in-DB ML systems, we integrate CorgiPile into PostgreSQL by introducing three new physical operators with optimizations. For deep learning systems, we extend single-process CorgiPile to multi-process CorgiPile for the parallel/distributed environment and integrate it into PyTorch. Our evaluation shows that CorgiPile can achieve comparable convergence rate with the full-shuffle-based SGD for both linear models and deep learning models. For in-DB ML with linear models, CorgiPile is 1.6\(\times \)\(-\)12.8\(\times \) faster than two state-of-the-art systems, Apache MADlib and Bismarck, on both HDD and SSD. For deep learning models on ImageNet, CorgiPile is 1.5\(\times \) faster than PyTorch with full data shuffle.
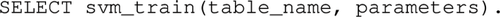


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
