{"title":"错误报告优先级分类模型。复制研究","authors":"Andreea Galbin-Nasui, Andreea Vescan","doi":"10.1007/s10515-024-00432-1","DOIUrl":null,"url":null,"abstract":"<div><p>Bug tracking systems receive a large number of bugs on a daily basis. The process of maintaining the integrity of the software and producing high-quality software is challenging. The bug-sorting process is usually a manual task that can lead to human errors and be time-consuming. The purpose of this research is twofold: first, to conduct a literature review on the bug report priority classification approaches, and second, to replicate existing approaches with various classifiers to extract new insights about the priority classification approaches. We used a Systematic Literature Review methodology to identify the most relevant existing approaches related to the bug report priority classification problem. Furthermore, we conducted a replication study on three classifiers: Naive Bayes (NB), Support Vector Machines (SVM), and Convolutional Neural Network (CNN). Two sets of experiments are performed: first, our own NLTK implementation based on NB and CNN, and second, based on Weka implementation for NB, SVM, and CNN. The dataset used consists of several Eclipse projects and one project related to database systems. The obtained results are better for the bug priority P3 for the CNN classifier, and overall the quality relation between the three classifiers is preserved as in the original studies. The replication study confirmed the findings of the original studies, emphasizing the need to further investigate the relationship between the characteristics of the projects used as training and those used as testing.</p></div>","PeriodicalId":55414,"journal":{"name":"Automated Software Engineering","volume":"31 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-04-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Bug reports priority classification models. Replication study\",\"authors\":\"Andreea Galbin-Nasui, Andreea Vescan\",\"doi\":\"10.1007/s10515-024-00432-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Bug tracking systems receive a large number of bugs on a daily basis. The process of maintaining the integrity of the software and producing high-quality software is challenging. The bug-sorting process is usually a manual task that can lead to human errors and be time-consuming. The purpose of this research is twofold: first, to conduct a literature review on the bug report priority classification approaches, and second, to replicate existing approaches with various classifiers to extract new insights about the priority classification approaches. We used a Systematic Literature Review methodology to identify the most relevant existing approaches related to the bug report priority classification problem. Furthermore, we conducted a replication study on three classifiers: Naive Bayes (NB), Support Vector Machines (SVM), and Convolutional Neural Network (CNN). Two sets of experiments are performed: first, our own NLTK implementation based on NB and CNN, and second, based on Weka implementation for NB, SVM, and CNN. The dataset used consists of several Eclipse projects and one project related to database systems. The obtained results are better for the bug priority P3 for the CNN classifier, and overall the quality relation between the three classifiers is preserved as in the original studies. The replication study confirmed the findings of the original studies, emphasizing the need to further investigate the relationship between the characteristics of the projects used as training and those used as testing.</p></div>\",\"PeriodicalId\":55414,\"journal\":{\"name\":\"Automated Software Engineering\",\"volume\":\"31 1\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-04-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Automated Software Engineering\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10515-024-00432-1\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Automated Software Engineering","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10515-024-00432-1","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Bug reports priority classification models. Replication study
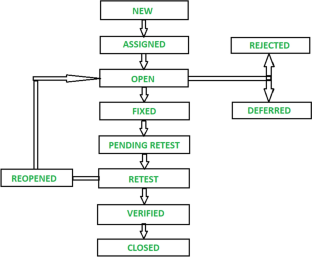
Bug tracking systems receive a large number of bugs on a daily basis. The process of maintaining the integrity of the software and producing high-quality software is challenging. The bug-sorting process is usually a manual task that can lead to human errors and be time-consuming. The purpose of this research is twofold: first, to conduct a literature review on the bug report priority classification approaches, and second, to replicate existing approaches with various classifiers to extract new insights about the priority classification approaches. We used a Systematic Literature Review methodology to identify the most relevant existing approaches related to the bug report priority classification problem. Furthermore, we conducted a replication study on three classifiers: Naive Bayes (NB), Support Vector Machines (SVM), and Convolutional Neural Network (CNN). Two sets of experiments are performed: first, our own NLTK implementation based on NB and CNN, and second, based on Weka implementation for NB, SVM, and CNN. The dataset used consists of several Eclipse projects and one project related to database systems. The obtained results are better for the bug priority P3 for the CNN classifier, and overall the quality relation between the three classifiers is preserved as in the original studies. The replication study confirmed the findings of the original studies, emphasizing the need to further investigate the relationship between the characteristics of the projects used as training and those used as testing.
期刊介绍:
This journal details research, tutorial papers, survey and accounts of significant industrial experience in the foundations, techniques, tools and applications of automated software engineering technology. This includes the study of techniques for constructing, understanding, adapting, and modeling software artifacts and processes.
Coverage in Automated Software Engineering examines both automatic systems and collaborative systems as well as computational models of human software engineering activities. In addition, it presents knowledge representations and artificial intelligence techniques applicable to automated software engineering, and formal techniques that support or provide theoretical foundations. The journal also includes reviews of books, software, conferences and workshops.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
