{"title":"F2S-Net:学习帧到段的预测,实现在线动作检测","authors":"Yi Liu, Yu Qiao, Yali Wang","doi":"10.1007/s11554-024-01454-4","DOIUrl":null,"url":null,"abstract":"<p>Online action detection (OAD) aims at predicting action per frame from a streaming untrimmed video in real time. Most existing approaches leverage all the historical frames in the sliding window as the temporal context of the current frame since single-frame prediction is often unreliable. However, such a manner inevitably introduces useless even noisy video content, which often misleads action classifier when recognizing the ongoing action in the current frame. To alleviate this difficulty, we propose a concise and novel F2S-Net, which can adaptively discover the contextual segments in the online sliding window, and convert current frame prediction into relevant-segment prediction. More specifically, as the current frame can be either action or background, we develop F2S-Net with a distinct two-branch structure, i.e., the action (or background) branch can exploit the action (or background) segments. Via multi-level action supervision, these two branches can complementarily enhance each other, allowing to identify the contextual segments in the sliding window to robustly predict what is ongoing. We evaluate our approach on popular OAD benchmarks, i.e., THUMOS-14, TVSeries and HDD. The extensive results show that our F2S-Net outperforms the recent state-of-the-art approaches.</p>","PeriodicalId":51224,"journal":{"name":"Journal of Real-Time Image Processing","volume":"22 1","pages":""},"PeriodicalIF":2.9000,"publicationDate":"2024-04-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"F2S-Net: learning frame-to-segment prediction for online action detection\",\"authors\":\"Yi Liu, Yu Qiao, Yali Wang\",\"doi\":\"10.1007/s11554-024-01454-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Online action detection (OAD) aims at predicting action per frame from a streaming untrimmed video in real time. Most existing approaches leverage all the historical frames in the sliding window as the temporal context of the current frame since single-frame prediction is often unreliable. However, such a manner inevitably introduces useless even noisy video content, which often misleads action classifier when recognizing the ongoing action in the current frame. To alleviate this difficulty, we propose a concise and novel F2S-Net, which can adaptively discover the contextual segments in the online sliding window, and convert current frame prediction into relevant-segment prediction. More specifically, as the current frame can be either action or background, we develop F2S-Net with a distinct two-branch structure, i.e., the action (or background) branch can exploit the action (or background) segments. Via multi-level action supervision, these two branches can complementarily enhance each other, allowing to identify the contextual segments in the sliding window to robustly predict what is ongoing. We evaluate our approach on popular OAD benchmarks, i.e., THUMOS-14, TVSeries and HDD. The extensive results show that our F2S-Net outperforms the recent state-of-the-art approaches.</p>\",\"PeriodicalId\":51224,\"journal\":{\"name\":\"Journal of Real-Time Image Processing\",\"volume\":\"22 1\",\"pages\":\"\"},\"PeriodicalIF\":2.9000,\"publicationDate\":\"2024-04-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Real-Time Image Processing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11554-024-01454-4\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Real-Time Image Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11554-024-01454-4","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
F2S-Net: learning frame-to-segment prediction for online action detection
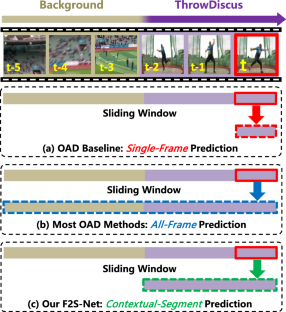
Online action detection (OAD) aims at predicting action per frame from a streaming untrimmed video in real time. Most existing approaches leverage all the historical frames in the sliding window as the temporal context of the current frame since single-frame prediction is often unreliable. However, such a manner inevitably introduces useless even noisy video content, which often misleads action classifier when recognizing the ongoing action in the current frame. To alleviate this difficulty, we propose a concise and novel F2S-Net, which can adaptively discover the contextual segments in the online sliding window, and convert current frame prediction into relevant-segment prediction. More specifically, as the current frame can be either action or background, we develop F2S-Net with a distinct two-branch structure, i.e., the action (or background) branch can exploit the action (or background) segments. Via multi-level action supervision, these two branches can complementarily enhance each other, allowing to identify the contextual segments in the sliding window to robustly predict what is ongoing. We evaluate our approach on popular OAD benchmarks, i.e., THUMOS-14, TVSeries and HDD. The extensive results show that our F2S-Net outperforms the recent state-of-the-art approaches.
期刊介绍:
Due to rapid advancements in integrated circuit technology, the rich theoretical results that have been developed by the image and video processing research community are now being increasingly applied in practical systems to solve real-world image and video processing problems. Such systems involve constraints placed not only on their size, cost, and power consumption, but also on the timeliness of the image data processed.
Examples of such systems are mobile phones, digital still/video/cell-phone cameras, portable media players, personal digital assistants, high-definition television, video surveillance systems, industrial visual inspection systems, medical imaging devices, vision-guided autonomous robots, spectral imaging systems, and many other real-time embedded systems. In these real-time systems, strict timing requirements demand that results are available within a certain interval of time as imposed by the application.
It is often the case that an image processing algorithm is developed and proven theoretically sound, presumably with a specific application in mind, but its practical applications and the detailed steps, methodology, and trade-off analysis required to achieve its real-time performance are not fully explored, leaving these critical and usually non-trivial issues for those wishing to employ the algorithm in a real-time system.
The Journal of Real-Time Image Processing is intended to bridge the gap between the theory and practice of image processing, serving the greater community of researchers, practicing engineers, and industrial professionals who deal with designing, implementing or utilizing image processing systems which must satisfy real-time design constraints.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
