Wouter van Loon, Marjolein Fokkema, Botond Szabo, Mark de Rooij
{"title":"多视图叠加中的视图选择:选择元学习器","authors":"Wouter van Loon, Marjolein Fokkema, Botond Szabo, Mark de Rooij","doi":"10.1007/s11634-024-00587-5","DOIUrl":null,"url":null,"abstract":"<div><p>Multi-view stacking is a framework for combining information from different views (i.e. different feature sets) describing the same set of objects. In this framework, a <i>base-learner</i> algorithm is trained on each view separately, and their predictions are then combined by a <i>meta-learner</i> algorithm. In a previous study, stacked penalized logistic regression, a special case of multi-view stacking, has been shown to be useful in identifying which views are most important for prediction. In this article we expand this research by considering seven different algorithms to use as the meta-learner, and evaluating their view selection and classification performance in simulations and two applications on real gene-expression data sets. Our results suggest that if both view selection and classification accuracy are important to the research at hand, then the nonnegative lasso, nonnegative adaptive lasso and nonnegative elastic net are suitable meta-learners. Exactly which among these three is to be preferred depends on the research context. The remaining four meta-learners, namely nonnegative ridge regression, nonnegative forward selection, stability selection and the interpolating predictor, show little advantages in order to be preferred over the other three.\n</p></div>","PeriodicalId":49270,"journal":{"name":"Advances in Data Analysis and Classification","volume":"19 3","pages":"579 - 617"},"PeriodicalIF":1.3000,"publicationDate":"2024-04-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s11634-024-00587-5.pdf","citationCount":"0","resultStr":"{\"title\":\"View selection in multi-view stacking: choosing the meta-learner\",\"authors\":\"Wouter van Loon, Marjolein Fokkema, Botond Szabo, Mark de Rooij\",\"doi\":\"10.1007/s11634-024-00587-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Multi-view stacking is a framework for combining information from different views (i.e. different feature sets) describing the same set of objects. In this framework, a <i>base-learner</i> algorithm is trained on each view separately, and their predictions are then combined by a <i>meta-learner</i> algorithm. In a previous study, stacked penalized logistic regression, a special case of multi-view stacking, has been shown to be useful in identifying which views are most important for prediction. In this article we expand this research by considering seven different algorithms to use as the meta-learner, and evaluating their view selection and classification performance in simulations and two applications on real gene-expression data sets. Our results suggest that if both view selection and classification accuracy are important to the research at hand, then the nonnegative lasso, nonnegative adaptive lasso and nonnegative elastic net are suitable meta-learners. Exactly which among these three is to be preferred depends on the research context. The remaining four meta-learners, namely nonnegative ridge regression, nonnegative forward selection, stability selection and the interpolating predictor, show little advantages in order to be preferred over the other three.\\n</p></div>\",\"PeriodicalId\":49270,\"journal\":{\"name\":\"Advances in Data Analysis and Classification\",\"volume\":\"19 3\",\"pages\":\"579 - 617\"},\"PeriodicalIF\":1.3000,\"publicationDate\":\"2024-04-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s11634-024-00587-5.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advances in Data Analysis and Classification\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s11634-024-00587-5\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"STATISTICS & PROBABILITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in Data Analysis and Classification","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s11634-024-00587-5","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
View selection in multi-view stacking: choosing the meta-learner
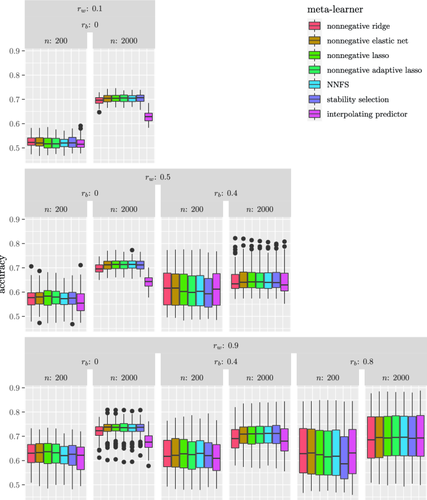
Multi-view stacking is a framework for combining information from different views (i.e. different feature sets) describing the same set of objects. In this framework, a base-learner algorithm is trained on each view separately, and their predictions are then combined by a meta-learner algorithm. In a previous study, stacked penalized logistic regression, a special case of multi-view stacking, has been shown to be useful in identifying which views are most important for prediction. In this article we expand this research by considering seven different algorithms to use as the meta-learner, and evaluating their view selection and classification performance in simulations and two applications on real gene-expression data sets. Our results suggest that if both view selection and classification accuracy are important to the research at hand, then the nonnegative lasso, nonnegative adaptive lasso and nonnegative elastic net are suitable meta-learners. Exactly which among these three is to be preferred depends on the research context. The remaining four meta-learners, namely nonnegative ridge regression, nonnegative forward selection, stability selection and the interpolating predictor, show little advantages in order to be preferred over the other three.
期刊介绍:
The international journal Advances in Data Analysis and Classification (ADAC) is designed as a forum for high standard publications on research and applications concerning the extraction of knowable aspects from many types of data. It publishes articles on such topics as structural, quantitative, or statistical approaches for the analysis of data; advances in classification, clustering, and pattern recognition methods; strategies for modeling complex data and mining large data sets; methods for the extraction of knowledge from data, and applications of advanced methods in specific domains of practice. Articles illustrate how new domain-specific knowledge can be made available from data by skillful use of data analysis methods. The journal also publishes survey papers that outline, and illuminate the basic ideas and techniques of special approaches.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
