{"title":"基于模糊粗糙集的马群优化算法,适用于客户行为数据的地图缩减框架","authors":"D. Sudha, M. Krishnamurthy","doi":"10.1007/s10115-024-02105-7","DOIUrl":null,"url":null,"abstract":"<p>A large number of association rules often minimizes the reliability of data mining results; hence, a dimensionality reduction technique is crucial for data analysis. When analyzing massive datasets, existing models take more time to scan the entire database because they discover unnecessary items and transactions that are not necessary for data analysis. For this purpose, the Fuzzy Rough Set-based Horse Herd Optimization (FRS-HHO) algorithm is proposed to be integrated with the Map Reduce algorithm to minimize query retrieval time and improve performance. The HHO algorithm minimizes the number of unnecessary items and transactions with minimal support value from the dataset to maximize fitness based on multiple objectives such as support, confidence, interestingness, and lift to evaluate the quality of association rules. The feature value of each item in the population is obtained by a Map Reduce-based fitness function to generate optimal frequent itemsets with minimum time. The Horse Herd Optimization (HHO) is employed to solve the high-dimensional optimization problems. The proposed FRS-HHO approach takes less time to execute for dimensions and has a space complexity of 38% for a total of 10 k transactions. Also, the FRS-HHO approach offers a speedup rate of 17% and a 12% decrease in input–output communication cost when compared to other approaches. The proposed FRS-HHO model enhances performance in terms of execution time, space complexity, and speed.</p>","PeriodicalId":54749,"journal":{"name":"Knowledge and Information Systems","volume":"35 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-04-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A fuzzy rough set-based horse herd optimization algorithm for map reduce framework for customer behavior data\",\"authors\":\"D. Sudha, M. Krishnamurthy\",\"doi\":\"10.1007/s10115-024-02105-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>A large number of association rules often minimizes the reliability of data mining results; hence, a dimensionality reduction technique is crucial for data analysis. When analyzing massive datasets, existing models take more time to scan the entire database because they discover unnecessary items and transactions that are not necessary for data analysis. For this purpose, the Fuzzy Rough Set-based Horse Herd Optimization (FRS-HHO) algorithm is proposed to be integrated with the Map Reduce algorithm to minimize query retrieval time and improve performance. The HHO algorithm minimizes the number of unnecessary items and transactions with minimal support value from the dataset to maximize fitness based on multiple objectives such as support, confidence, interestingness, and lift to evaluate the quality of association rules. The feature value of each item in the population is obtained by a Map Reduce-based fitness function to generate optimal frequent itemsets with minimum time. The Horse Herd Optimization (HHO) is employed to solve the high-dimensional optimization problems. The proposed FRS-HHO approach takes less time to execute for dimensions and has a space complexity of 38% for a total of 10 k transactions. Also, the FRS-HHO approach offers a speedup rate of 17% and a 12% decrease in input–output communication cost when compared to other approaches. The proposed FRS-HHO model enhances performance in terms of execution time, space complexity, and speed.</p>\",\"PeriodicalId\":54749,\"journal\":{\"name\":\"Knowledge and Information Systems\",\"volume\":\"35 1\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-04-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Knowledge and Information Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10115-024-02105-7\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Knowledge and Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10115-024-02105-7","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
A fuzzy rough set-based horse herd optimization algorithm for map reduce framework for customer behavior data
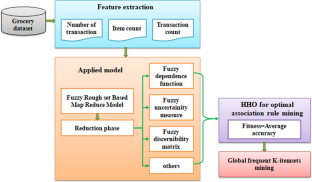
A large number of association rules often minimizes the reliability of data mining results; hence, a dimensionality reduction technique is crucial for data analysis. When analyzing massive datasets, existing models take more time to scan the entire database because they discover unnecessary items and transactions that are not necessary for data analysis. For this purpose, the Fuzzy Rough Set-based Horse Herd Optimization (FRS-HHO) algorithm is proposed to be integrated with the Map Reduce algorithm to minimize query retrieval time and improve performance. The HHO algorithm minimizes the number of unnecessary items and transactions with minimal support value from the dataset to maximize fitness based on multiple objectives such as support, confidence, interestingness, and lift to evaluate the quality of association rules. The feature value of each item in the population is obtained by a Map Reduce-based fitness function to generate optimal frequent itemsets with minimum time. The Horse Herd Optimization (HHO) is employed to solve the high-dimensional optimization problems. The proposed FRS-HHO approach takes less time to execute for dimensions and has a space complexity of 38% for a total of 10 k transactions. Also, the FRS-HHO approach offers a speedup rate of 17% and a 12% decrease in input–output communication cost when compared to other approaches. The proposed FRS-HHO model enhances performance in terms of execution time, space complexity, and speed.
期刊介绍:
Knowledge and Information Systems (KAIS) provides an international forum for researchers and professionals to share their knowledge and report new advances on all topics related to knowledge systems and advanced information systems. This monthly peer-reviewed archival journal publishes state-of-the-art research reports on emerging topics in KAIS, reviews of important techniques in related areas, and application papers of interest to a general readership.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
