Johanna Eckrich, Jörg Ellinger, Alexander Cox, Johannes Stein, Manuel Ritter, Andrew Blaikie, Sebastian Kuhn, Christoph Raphael Buhr
{"title":"泌尿外科顾问与大型语言模型:泌尿外科医疗建议的潜力与危害","authors":"Johanna Eckrich, Jörg Ellinger, Alexander Cox, Johannes Stein, Manuel Ritter, Andrew Blaikie, Sebastian Kuhn, Christoph Raphael Buhr","doi":"10.1002/bco2.359","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Background</h3>\n \n <p>Current interest surrounding large language models (LLMs) will lead to an increase in their use for medical advice. Although LLMs offer huge potential, they also pose potential misinformation hazards.</p>\n </section>\n \n <section>\n \n <h3> Objective</h3>\n \n <p>This study evaluates three LLMs answering urology-themed clinical case-based questions by comparing the quality of answers to those provided by urology consultants.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>Forty-five case-based questions were answered by consultants and LLMs (ChatGPT 3.5, ChatGPT 4, Bard). Answers were blindly rated using a six-step Likert scale by four consultants in the categories: ‘medical adequacy’, ‘conciseness’, ‘coherence’ and ‘comprehensibility’. Possible misinformation hazards were identified; a modified Turing test was included, and the character count was matched.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>Higher ratings in every category were recorded for the consultants. LLMs' overall performance in language-focused categories (coherence and comprehensibility) was relatively high. Medical adequacy was significantly poorer compared with the consultants. Possible misinformation hazards were identified in 2.8% to 18.9% of answers generated by LLMs compared with <1% of consultant's answers. Poorer conciseness rates and a higher character count were provided by LLMs. Among individual LLMs, ChatGPT 4 performed best in medical accuracy (<i>p</i> < 0.0001) and coherence (<i>p</i> = 0.001), whereas Bard received the lowest scores. Generated responses were accurately associated with their source with 98% accuracy in LLMs and 99% with consultants.</p>\n </section>\n \n <section>\n \n <h3> Conclusions</h3>\n \n <p>The quality of consultant answers was superior to LLMs in all categories. High semantic scores for LLM answers were found; however, the lack of medical accuracy led to potential misinformation hazards from LLM ‘consultations’. Further investigations are necessary for new generations.</p>\n </section>\n </div>","PeriodicalId":72420,"journal":{"name":"BJUI compass","volume":"5 5","pages":"552-558"},"PeriodicalIF":1.9000,"publicationDate":"2024-04-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/bco2.359","citationCount":"0","resultStr":"{\"title\":\"Urology consultants versus large language models: Potentials and hazards for medical advice in urology\",\"authors\":\"Johanna Eckrich, Jörg Ellinger, Alexander Cox, Johannes Stein, Manuel Ritter, Andrew Blaikie, Sebastian Kuhn, Christoph Raphael Buhr\",\"doi\":\"10.1002/bco2.359\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Background</h3>\\n \\n <p>Current interest surrounding large language models (LLMs) will lead to an increase in their use for medical advice. Although LLMs offer huge potential, they also pose potential misinformation hazards.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Objective</h3>\\n \\n <p>This study evaluates three LLMs answering urology-themed clinical case-based questions by comparing the quality of answers to those provided by urology consultants.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Methods</h3>\\n \\n <p>Forty-five case-based questions were answered by consultants and LLMs (ChatGPT 3.5, ChatGPT 4, Bard). Answers were blindly rated using a six-step Likert scale by four consultants in the categories: ‘medical adequacy’, ‘conciseness’, ‘coherence’ and ‘comprehensibility’. Possible misinformation hazards were identified; a modified Turing test was included, and the character count was matched.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Results</h3>\\n \\n <p>Higher ratings in every category were recorded for the consultants. LLMs' overall performance in language-focused categories (coherence and comprehensibility) was relatively high. Medical adequacy was significantly poorer compared with the consultants. Possible misinformation hazards were identified in 2.8% to 18.9% of answers generated by LLMs compared with <1% of consultant's answers. Poorer conciseness rates and a higher character count were provided by LLMs. Among individual LLMs, ChatGPT 4 performed best in medical accuracy (<i>p</i> < 0.0001) and coherence (<i>p</i> = 0.001), whereas Bard received the lowest scores. Generated responses were accurately associated with their source with 98% accuracy in LLMs and 99% with consultants.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Conclusions</h3>\\n \\n <p>The quality of consultant answers was superior to LLMs in all categories. High semantic scores for LLM answers were found; however, the lack of medical accuracy led to potential misinformation hazards from LLM ‘consultations’. Further investigations are necessary for new generations.</p>\\n </section>\\n </div>\",\"PeriodicalId\":72420,\"journal\":{\"name\":\"BJUI compass\",\"volume\":\"5 5\",\"pages\":\"552-558\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2024-04-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/bco2.359\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BJUI compass\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://bjui-journals.onlinelibrary.wiley.com/doi/10.1002/bco2.359\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"UROLOGY & NEPHROLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BJUI compass","FirstCategoryId":"1085","ListUrlMain":"https://bjui-journals.onlinelibrary.wiley.com/doi/10.1002/bco2.359","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"UROLOGY & NEPHROLOGY","Score":null,"Total":0}
Urology consultants versus large language models: Potentials and hazards for medical advice in urology
Background
Current interest surrounding large language models (LLMs) will lead to an increase in their use for medical advice. Although LLMs offer huge potential, they also pose potential misinformation hazards.
Objective
This study evaluates three LLMs answering urology-themed clinical case-based questions by comparing the quality of answers to those provided by urology consultants.
Methods
Forty-five case-based questions were answered by consultants and LLMs (ChatGPT 3.5, ChatGPT 4, Bard). Answers were blindly rated using a six-step Likert scale by four consultants in the categories: ‘medical adequacy’, ‘conciseness’, ‘coherence’ and ‘comprehensibility’. Possible misinformation hazards were identified; a modified Turing test was included, and the character count was matched.
Results
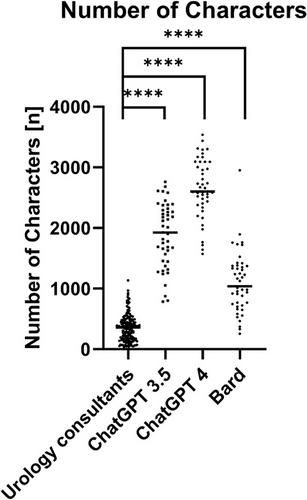
Higher ratings in every category were recorded for the consultants. LLMs' overall performance in language-focused categories (coherence and comprehensibility) was relatively high. Medical adequacy was significantly poorer compared with the consultants. Possible misinformation hazards were identified in 2.8% to 18.9% of answers generated by LLMs compared with <1% of consultant's answers. Poorer conciseness rates and a higher character count were provided by LLMs. Among individual LLMs, ChatGPT 4 performed best in medical accuracy (p < 0.0001) and coherence (p = 0.001), whereas Bard received the lowest scores. Generated responses were accurately associated with their source with 98% accuracy in LLMs and 99% with consultants.
Conclusions
The quality of consultant answers was superior to LLMs in all categories. High semantic scores for LLM answers were found; however, the lack of medical accuracy led to potential misinformation hazards from LLM ‘consultations’. Further investigations are necessary for new generations.




 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
