Kyungdeuk Ko, Donghyeon Kim, Kyungseok Oh, Hanseok Ko
{"title":"WaveVC:语音和基频一致的原始音频语音转换","authors":"Kyungdeuk Ko, Donghyeon Kim, Kyungseok Oh, Hanseok Ko","doi":"10.1007/s11063-024-11613-0","DOIUrl":null,"url":null,"abstract":"<p>Voice conversion (VC) is a task for changing the speech of a source speaker to the target voice while preserving linguistic information of the source speech. The existing VC methods typically use mel-spectrogram as both input and output, so a separate vocoder is required to transform mel-spectrogram into waveform. Therefore, the VC performance varies depending on the vocoder performance, and noisy speech can be generated due to problems such as train-test mismatch. In this paper, we propose a speech and fundamental frequency consistent raw audio voice conversion method called WaveVC. Unlike other methods, WaveVC does not require a separate vocoder and can perform VC directly on raw audio waveform using 1D convolution. This eliminates the issue of performance degradation caused by the train-test mismatch of the vocoder. In the training phase, WaveVC employs speech loss and F0 loss to preserve the content of the source speech and generate F0 consistent speech using the pre-trained networks. WaveVC is capable of converting voices while maintaining consistency in speech and fundamental frequency. In the test phase, the F0 feature of the source speech is concatenated with a content embedding vector to ensure the converted speech follows the fundamental frequency flow of the source speech. WaveVC achieves higher performances than baseline methods in both many-to-many VC and any-to-any VC. The converted samples are available online.</p>","PeriodicalId":51144,"journal":{"name":"Neural Processing Letters","volume":"37 1","pages":""},"PeriodicalIF":2.8000,"publicationDate":"2024-05-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"WaveVC: Speech and Fundamental Frequency Consistent Raw Audio Voice Conversion\",\"authors\":\"Kyungdeuk Ko, Donghyeon Kim, Kyungseok Oh, Hanseok Ko\",\"doi\":\"10.1007/s11063-024-11613-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Voice conversion (VC) is a task for changing the speech of a source speaker to the target voice while preserving linguistic information of the source speech. The existing VC methods typically use mel-spectrogram as both input and output, so a separate vocoder is required to transform mel-spectrogram into waveform. Therefore, the VC performance varies depending on the vocoder performance, and noisy speech can be generated due to problems such as train-test mismatch. In this paper, we propose a speech and fundamental frequency consistent raw audio voice conversion method called WaveVC. Unlike other methods, WaveVC does not require a separate vocoder and can perform VC directly on raw audio waveform using 1D convolution. This eliminates the issue of performance degradation caused by the train-test mismatch of the vocoder. In the training phase, WaveVC employs speech loss and F0 loss to preserve the content of the source speech and generate F0 consistent speech using the pre-trained networks. WaveVC is capable of converting voices while maintaining consistency in speech and fundamental frequency. In the test phase, the F0 feature of the source speech is concatenated with a content embedding vector to ensure the converted speech follows the fundamental frequency flow of the source speech. WaveVC achieves higher performances than baseline methods in both many-to-many VC and any-to-any VC. The converted samples are available online.</p>\",\"PeriodicalId\":51144,\"journal\":{\"name\":\"Neural Processing Letters\",\"volume\":\"37 1\",\"pages\":\"\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-05-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Neural Processing Letters\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11063-024-11613-0\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neural Processing Letters","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11063-024-11613-0","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
WaveVC: Speech and Fundamental Frequency Consistent Raw Audio Voice Conversion
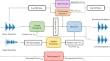
Voice conversion (VC) is a task for changing the speech of a source speaker to the target voice while preserving linguistic information of the source speech. The existing VC methods typically use mel-spectrogram as both input and output, so a separate vocoder is required to transform mel-spectrogram into waveform. Therefore, the VC performance varies depending on the vocoder performance, and noisy speech can be generated due to problems such as train-test mismatch. In this paper, we propose a speech and fundamental frequency consistent raw audio voice conversion method called WaveVC. Unlike other methods, WaveVC does not require a separate vocoder and can perform VC directly on raw audio waveform using 1D convolution. This eliminates the issue of performance degradation caused by the train-test mismatch of the vocoder. In the training phase, WaveVC employs speech loss and F0 loss to preserve the content of the source speech and generate F0 consistent speech using the pre-trained networks. WaveVC is capable of converting voices while maintaining consistency in speech and fundamental frequency. In the test phase, the F0 feature of the source speech is concatenated with a content embedding vector to ensure the converted speech follows the fundamental frequency flow of the source speech. WaveVC achieves higher performances than baseline methods in both many-to-many VC and any-to-any VC. The converted samples are available online.
期刊介绍:
Neural Processing Letters is an international journal publishing research results and innovative ideas on all aspects of artificial neural networks. Coverage includes theoretical developments, biological models, new formal modes, learning, applications, software and hardware developments, and prospective researches.
The journal promotes fast exchange of information in the community of neural network researchers and users. The resurgence of interest in the field of artificial neural networks since the beginning of the 1980s is coupled to tremendous research activity in specialized or multidisciplinary groups. Research, however, is not possible without good communication between people and the exchange of information, especially in a field covering such different areas; fast communication is also a key aspect, and this is the reason for Neural Processing Letters




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
