{"title":"预测甘薯感官特征的近红外光谱学机器学习方法。","authors":"Judith Ssali Nantongo, Edwin Serunkuma, Gabriela Burgos, Mariam Nakitto, Fabrice Davrieux, Reuben Ssali","doi":"10.1016/j.saa.2024.124406","DOIUrl":null,"url":null,"abstract":"<p><p>It has been established that near infrared (NIR) spectroscopy has the potential of estimating sensory traits given the direct spectral responses that these properties have in the NIR region. In sweetpotato, sensory and texture traits are key for improving acceptability of the crop for food security and nutrition. Studies have statistically modelled the levels of NIR spectroscopy sensory characteristics using partial least squares (PLS) regression methods. To improve prediction accuracy, there are many advanced techniques, which could enhance modelling of fresh (wet and un-processed) samples or nonlinear dependence relationships. Performance of different quantitative prediction models for sensory traits developed using different machine learning methods were compared. Overall, results show that linear methods; linear support vector machine (L-SVM), principal component regression (PCR) and PLS exhibited higher mean R<sup>2</sup> values than other statistical methods. For all the 27 sensory traits, calibration models using L-SVM and PCR has slightly higher overall R<sup>2</sup> (x¯ = 0.33) compared to PLS (x¯ = 0.32) and radial-based SVM (NL-SVM; x¯= 0.30). The levels of orange color intensity were the best predicted by all the calibration models (R<sup>2</sup> = 0.87 - 0.89). The elastic net linear regression (ENR) and tree-based methods; extreme gradient boost (XGBoost) and random forest (RF) performed worse than would be expected but could possibly be improved with increased sample size. Lower average R<sup>2</sup> values were observed for calibration models of ENR (x¯ = 0.26), XGBoost (x¯ = 0.26) and RF (x¯ = 0.22). The overall RMSE in calibration models was lower in PCR models (X = 0.82) compared to L-SVM (x¯ = 0.86) and PLS (x¯ = 0.90). ENR, XGBoost and RF also had higher RMSE (x¯ = 0.90 - 0.92). Effective wavelengths selection using the interval partial least-squares regression (iPLS), improved the performance of the models but did not perform as good as the PLS. SNV pre-treatment was useful in improving model performance.</p>","PeriodicalId":94213,"journal":{"name":"Spectrochimica acta. Part A, Molecular and biomolecular spectroscopy","volume":"318 ","pages":"124406"},"PeriodicalIF":4.6000,"publicationDate":"2024-10-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Machine learning methods in near infrared spectroscopy for predicting sensory traits in sweetpotatoes.\",\"authors\":\"Judith Ssali Nantongo, Edwin Serunkuma, Gabriela Burgos, Mariam Nakitto, Fabrice Davrieux, Reuben Ssali\",\"doi\":\"10.1016/j.saa.2024.124406\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>It has been established that near infrared (NIR) spectroscopy has the potential of estimating sensory traits given the direct spectral responses that these properties have in the NIR region. In sweetpotato, sensory and texture traits are key for improving acceptability of the crop for food security and nutrition. Studies have statistically modelled the levels of NIR spectroscopy sensory characteristics using partial least squares (PLS) regression methods. To improve prediction accuracy, there are many advanced techniques, which could enhance modelling of fresh (wet and un-processed) samples or nonlinear dependence relationships. Performance of different quantitative prediction models for sensory traits developed using different machine learning methods were compared. Overall, results show that linear methods; linear support vector machine (L-SVM), principal component regression (PCR) and PLS exhibited higher mean R<sup>2</sup> values than other statistical methods. For all the 27 sensory traits, calibration models using L-SVM and PCR has slightly higher overall R<sup>2</sup> (x¯ = 0.33) compared to PLS (x¯ = 0.32) and radial-based SVM (NL-SVM; x¯= 0.30). The levels of orange color intensity were the best predicted by all the calibration models (R<sup>2</sup> = 0.87 - 0.89). The elastic net linear regression (ENR) and tree-based methods; extreme gradient boost (XGBoost) and random forest (RF) performed worse than would be expected but could possibly be improved with increased sample size. Lower average R<sup>2</sup> values were observed for calibration models of ENR (x¯ = 0.26), XGBoost (x¯ = 0.26) and RF (x¯ = 0.22). The overall RMSE in calibration models was lower in PCR models (X = 0.82) compared to L-SVM (x¯ = 0.86) and PLS (x¯ = 0.90). ENR, XGBoost and RF also had higher RMSE (x¯ = 0.90 - 0.92). Effective wavelengths selection using the interval partial least-squares regression (iPLS), improved the performance of the models but did not perform as good as the PLS. SNV pre-treatment was useful in improving model performance.</p>\",\"PeriodicalId\":94213,\"journal\":{\"name\":\"Spectrochimica acta. Part A, Molecular and biomolecular spectroscopy\",\"volume\":\"318 \",\"pages\":\"124406\"},\"PeriodicalIF\":4.6000,\"publicationDate\":\"2024-10-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Spectrochimica acta. Part A, Molecular and biomolecular spectroscopy\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1016/j.saa.2024.124406\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/5/4 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Spectrochimica acta. Part A, Molecular and biomolecular spectroscopy","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1016/j.saa.2024.124406","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/5/4 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Machine learning methods in near infrared spectroscopy for predicting sensory traits in sweetpotatoes.
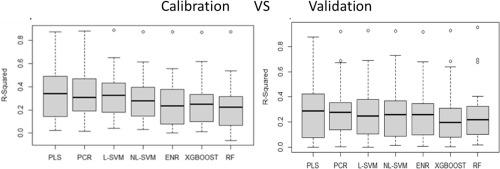
It has been established that near infrared (NIR) spectroscopy has the potential of estimating sensory traits given the direct spectral responses that these properties have in the NIR region. In sweetpotato, sensory and texture traits are key for improving acceptability of the crop for food security and nutrition. Studies have statistically modelled the levels of NIR spectroscopy sensory characteristics using partial least squares (PLS) regression methods. To improve prediction accuracy, there are many advanced techniques, which could enhance modelling of fresh (wet and un-processed) samples or nonlinear dependence relationships. Performance of different quantitative prediction models for sensory traits developed using different machine learning methods were compared. Overall, results show that linear methods; linear support vector machine (L-SVM), principal component regression (PCR) and PLS exhibited higher mean R2 values than other statistical methods. For all the 27 sensory traits, calibration models using L-SVM and PCR has slightly higher overall R2 (x¯ = 0.33) compared to PLS (x¯ = 0.32) and radial-based SVM (NL-SVM; x¯= 0.30). The levels of orange color intensity were the best predicted by all the calibration models (R2 = 0.87 - 0.89). The elastic net linear regression (ENR) and tree-based methods; extreme gradient boost (XGBoost) and random forest (RF) performed worse than would be expected but could possibly be improved with increased sample size. Lower average R2 values were observed for calibration models of ENR (x¯ = 0.26), XGBoost (x¯ = 0.26) and RF (x¯ = 0.22). The overall RMSE in calibration models was lower in PCR models (X = 0.82) compared to L-SVM (x¯ = 0.86) and PLS (x¯ = 0.90). ENR, XGBoost and RF also had higher RMSE (x¯ = 0.90 - 0.92). Effective wavelengths selection using the interval partial least-squares regression (iPLS), improved the performance of the models but did not perform as good as the PLS. SNV pre-treatment was useful in improving model performance.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
