{"title":"基于机器学习的认知能力衰退预测模型:在多语言环境中使用语音分析的比较研究。","authors":"B Ceyhan, S Bek, T Önal-Süzek","doi":"10.14283/jarlife.2024.6","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Mild cognitive impairment (MCI) is a condition commonly associated with dementia. Therefore, early prediction of progression from MCI to dementia is essential for preventing or alleviating cognitive decline. Given that dementia affects cognitive functions like language and speech, detecting disease progression through speech analysis can provide a cost-effective solution for patients and caregivers.</p><p><strong>Design-participants: </strong>In our study, we examined spontaneous speech (SS) and written Mini Mental Status Examination (MMSE) scores from a 60-patient dataset obtained from the Mugla University Dementia Outpatient Clinic (MUDC) and a 153-patient dataset from the Alzheimer's Dementia Recognition through Spontaneous Speech (ADRess) challenge. Our study, for the first time, analyzed the impact of audio features extracted from SS in distinguishing between different degrees of cognitive impairment using both an Indo-European language and a Turkic language, which exhibit distinct word order, agglutination, noun cases, and grammatical markers.</p><p><strong>Results: </strong>When each machine learning model was tested on its respective trained language, we attained a 95% accuracy using the random forest classifier on the ADRess dataset and a 94% accuracy on the MUDC dataset employing the multilayer perceptron (MLP) neural network algorithm. In our second experiment, we evaluated the effectiveness of each language-specific machine learning model on the dataset of the other language. We achieved accuracies of 72% for English and 76% for Turkish, respectively.</p><p><strong>Conclusion: </strong>These findings underscore the cross-language potential of audio features for automated tracking of cognitive impairment progression in MCI patients, offering a convenient and cost-effective option for clinicians or patients.</p>","PeriodicalId":73537,"journal":{"name":"JAR life","volume":"13 ","pages":"43-50"},"PeriodicalIF":0.0000,"publicationDate":"2024-05-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11106089/pdf/","citationCount":"0","resultStr":"{\"title\":\"Machine Learning-Based Prediction Models for Cognitive Decline Progression: A Comparative Study in Multilingual Settings Using Speech Analysis.\",\"authors\":\"B Ceyhan, S Bek, T Önal-Süzek\",\"doi\":\"10.14283/jarlife.2024.6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Mild cognitive impairment (MCI) is a condition commonly associated with dementia. Therefore, early prediction of progression from MCI to dementia is essential for preventing or alleviating cognitive decline. Given that dementia affects cognitive functions like language and speech, detecting disease progression through speech analysis can provide a cost-effective solution for patients and caregivers.</p><p><strong>Design-participants: </strong>In our study, we examined spontaneous speech (SS) and written Mini Mental Status Examination (MMSE) scores from a 60-patient dataset obtained from the Mugla University Dementia Outpatient Clinic (MUDC) and a 153-patient dataset from the Alzheimer's Dementia Recognition through Spontaneous Speech (ADRess) challenge. Our study, for the first time, analyzed the impact of audio features extracted from SS in distinguishing between different degrees of cognitive impairment using both an Indo-European language and a Turkic language, which exhibit distinct word order, agglutination, noun cases, and grammatical markers.</p><p><strong>Results: </strong>When each machine learning model was tested on its respective trained language, we attained a 95% accuracy using the random forest classifier on the ADRess dataset and a 94% accuracy on the MUDC dataset employing the multilayer perceptron (MLP) neural network algorithm. In our second experiment, we evaluated the effectiveness of each language-specific machine learning model on the dataset of the other language. We achieved accuracies of 72% for English and 76% for Turkish, respectively.</p><p><strong>Conclusion: </strong>These findings underscore the cross-language potential of audio features for automated tracking of cognitive impairment progression in MCI patients, offering a convenient and cost-effective option for clinicians or patients.</p>\",\"PeriodicalId\":73537,\"journal\":{\"name\":\"JAR life\",\"volume\":\"13 \",\"pages\":\"43-50\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-05-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11106089/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAR life\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.14283/jarlife.2024.6\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAR life","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.14283/jarlife.2024.6","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
Machine Learning-Based Prediction Models for Cognitive Decline Progression: A Comparative Study in Multilingual Settings Using Speech Analysis.
Background: Mild cognitive impairment (MCI) is a condition commonly associated with dementia. Therefore, early prediction of progression from MCI to dementia is essential for preventing or alleviating cognitive decline. Given that dementia affects cognitive functions like language and speech, detecting disease progression through speech analysis can provide a cost-effective solution for patients and caregivers.
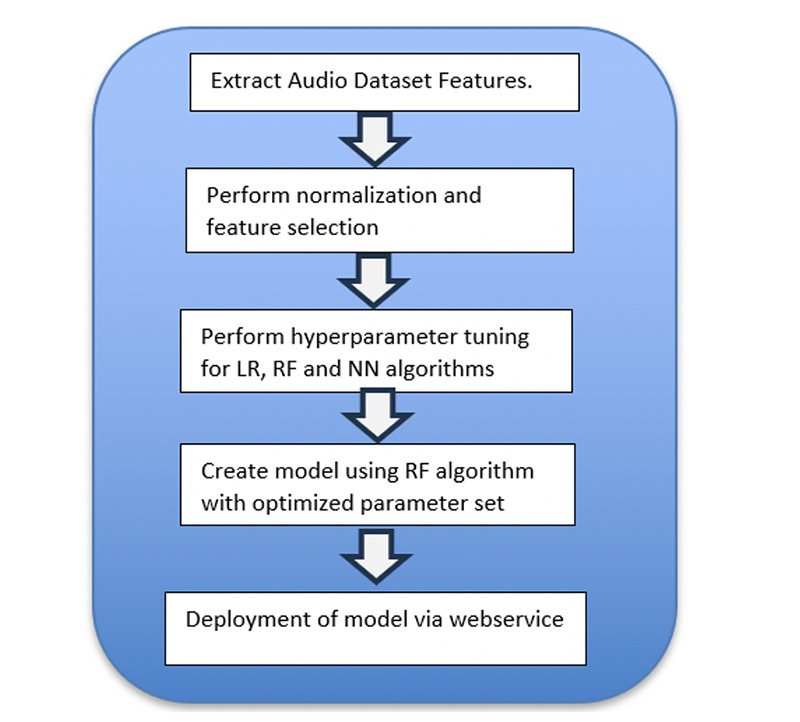
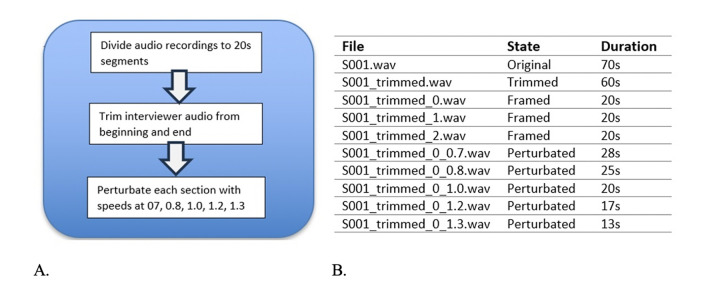
Design-participants: In our study, we examined spontaneous speech (SS) and written Mini Mental Status Examination (MMSE) scores from a 60-patient dataset obtained from the Mugla University Dementia Outpatient Clinic (MUDC) and a 153-patient dataset from the Alzheimer's Dementia Recognition through Spontaneous Speech (ADRess) challenge. Our study, for the first time, analyzed the impact of audio features extracted from SS in distinguishing between different degrees of cognitive impairment using both an Indo-European language and a Turkic language, which exhibit distinct word order, agglutination, noun cases, and grammatical markers.
Results: When each machine learning model was tested on its respective trained language, we attained a 95% accuracy using the random forest classifier on the ADRess dataset and a 94% accuracy on the MUDC dataset employing the multilayer perceptron (MLP) neural network algorithm. In our second experiment, we evaluated the effectiveness of each language-specific machine learning model on the dataset of the other language. We achieved accuracies of 72% for English and 76% for Turkish, respectively.
Conclusion: These findings underscore the cross-language potential of audio features for automated tracking of cognitive impairment progression in MCI patients, offering a convenient and cost-effective option for clinicians or patients.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
