Pedro Mateus , Justine Moonen , Magdalena Beran , Eva Jaarsma , Sophie M. van der Landen , Joost Heuvelink , Mahlet Birhanu , Alexander G.J. Harms , Esther Bron , Frank J. Wolters , Davy Cats , Hailiang Mei , Julie Oomens , Willemijn Jansen , Miranda T. Schram , Andre Dekker , Inigo Bermejo
{"title":"使用 OMOP 通用数据模型进行多队列痴呆症研究的数据协调和联合学习:荷兰痴呆症队列联盟案例研究。","authors":"Pedro Mateus , Justine Moonen , Magdalena Beran , Eva Jaarsma , Sophie M. van der Landen , Joost Heuvelink , Mahlet Birhanu , Alexander G.J. Harms , Esther Bron , Frank J. Wolters , Davy Cats , Hailiang Mei , Julie Oomens , Willemijn Jansen , Miranda T. Schram , Andre Dekker , Inigo Bermejo","doi":"10.1016/j.jbi.2024.104661","DOIUrl":null,"url":null,"abstract":"<div><h3>Background</h3><p>Establishing collaborations between cohort studies has been fundamental for progress in health research. However, such collaborations are hampered by heterogeneous data representations across cohorts and legal constraints to data sharing. The first arises from a lack of consensus in standards of data collection and representation across cohort studies and is usually tackled by applying data harmonization processes. The second is increasingly important due to raised awareness for privacy protection and stricter regulations, such as the GDPR. Federated learning has emerged as a privacy-preserving alternative to transferring data between institutions through analyzing data in a decentralized manner.</p></div><div><h3>Methods</h3><p>In this study, we set up a federated learning infrastructure for a consortium of nine Dutch cohorts with appropriate data available to the etiology of dementia, including an extract, transform, and load (ETL) pipeline for data harmonization. Additionally, we assessed the challenges of transforming and standardizing cohort data using the Observational Medical Outcomes Partnership (OMOP) common data model (CDM) and evaluated our tool in one of the cohorts employing federated algorithms.</p></div><div><h3>Results</h3><p>We successfully applied our ETL tool and observed a complete coverage of the cohorts’ data by the OMOP CDM. The OMOP CDM facilitated the data representation and standardization, but we identified limitations for cohort-specific data fields and in the scope of the vocabularies available. Specific challenges arise in a multi-cohort federated collaboration due to technical constraints in local environments, data heterogeneity, and lack of direct access to the data.</p></div><div><h3>Conclusion</h3><p>In this article, we describe the solutions to these challenges and limitations encountered in our study. Our study shows the potential of federated learning as a privacy-preserving solution for multi-cohort studies that enhance reproducibility and reuse of both data and analyses.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"155 ","pages":"Article 104661"},"PeriodicalIF":4.5000,"publicationDate":"2024-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S1532046424000790/pdfft?md5=427f60e31fbd734fb61c4e9620e9e4d4&pid=1-s2.0-S1532046424000790-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Data harmonization and federated learning for multi-cohort dementia research using the OMOP common data model: A Netherlands consortium of dementia cohorts case study\",\"authors\":\"Pedro Mateus , Justine Moonen , Magdalena Beran , Eva Jaarsma , Sophie M. van der Landen , Joost Heuvelink , Mahlet Birhanu , Alexander G.J. Harms , Esther Bron , Frank J. Wolters , Davy Cats , Hailiang Mei , Julie Oomens , Willemijn Jansen , Miranda T. Schram , Andre Dekker , Inigo Bermejo\",\"doi\":\"10.1016/j.jbi.2024.104661\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Background</h3><p>Establishing collaborations between cohort studies has been fundamental for progress in health research. However, such collaborations are hampered by heterogeneous data representations across cohorts and legal constraints to data sharing. The first arises from a lack of consensus in standards of data collection and representation across cohort studies and is usually tackled by applying data harmonization processes. The second is increasingly important due to raised awareness for privacy protection and stricter regulations, such as the GDPR. Federated learning has emerged as a privacy-preserving alternative to transferring data between institutions through analyzing data in a decentralized manner.</p></div><div><h3>Methods</h3><p>In this study, we set up a federated learning infrastructure for a consortium of nine Dutch cohorts with appropriate data available to the etiology of dementia, including an extract, transform, and load (ETL) pipeline for data harmonization. Additionally, we assessed the challenges of transforming and standardizing cohort data using the Observational Medical Outcomes Partnership (OMOP) common data model (CDM) and evaluated our tool in one of the cohorts employing federated algorithms.</p></div><div><h3>Results</h3><p>We successfully applied our ETL tool and observed a complete coverage of the cohorts’ data by the OMOP CDM. The OMOP CDM facilitated the data representation and standardization, but we identified limitations for cohort-specific data fields and in the scope of the vocabularies available. Specific challenges arise in a multi-cohort federated collaboration due to technical constraints in local environments, data heterogeneity, and lack of direct access to the data.</p></div><div><h3>Conclusion</h3><p>In this article, we describe the solutions to these challenges and limitations encountered in our study. Our study shows the potential of federated learning as a privacy-preserving solution for multi-cohort studies that enhance reproducibility and reuse of both data and analyses.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"155 \",\"pages\":\"Article 104661\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2024-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S1532046424000790/pdfft?md5=427f60e31fbd734fb61c4e9620e9e4d4&pid=1-s2.0-S1532046424000790-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424000790\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/5/26 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424000790","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/5/26 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Data harmonization and federated learning for multi-cohort dementia research using the OMOP common data model: A Netherlands consortium of dementia cohorts case study
Background
Establishing collaborations between cohort studies has been fundamental for progress in health research. However, such collaborations are hampered by heterogeneous data representations across cohorts and legal constraints to data sharing. The first arises from a lack of consensus in standards of data collection and representation across cohort studies and is usually tackled by applying data harmonization processes. The second is increasingly important due to raised awareness for privacy protection and stricter regulations, such as the GDPR. Federated learning has emerged as a privacy-preserving alternative to transferring data between institutions through analyzing data in a decentralized manner.
Methods
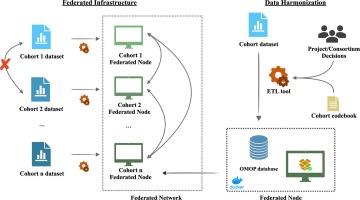
In this study, we set up a federated learning infrastructure for a consortium of nine Dutch cohorts with appropriate data available to the etiology of dementia, including an extract, transform, and load (ETL) pipeline for data harmonization. Additionally, we assessed the challenges of transforming and standardizing cohort data using the Observational Medical Outcomes Partnership (OMOP) common data model (CDM) and evaluated our tool in one of the cohorts employing federated algorithms.
Results
We successfully applied our ETL tool and observed a complete coverage of the cohorts’ data by the OMOP CDM. The OMOP CDM facilitated the data representation and standardization, but we identified limitations for cohort-specific data fields and in the scope of the vocabularies available. Specific challenges arise in a multi-cohort federated collaboration due to technical constraints in local environments, data heterogeneity, and lack of direct access to the data.
Conclusion
In this article, we describe the solutions to these challenges and limitations encountered in our study. Our study shows the potential of federated learning as a privacy-preserving solution for multi-cohort studies that enhance reproducibility and reuse of both data and analyses.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
