Innocent Gerald Asiimwe, Bonginkosi S'fiso Ndzamba, Samer Mouksassi, Goonaseelan Colin Pillai, Aurelie Lombard, Jennifer Lang
{"title":"机器学习辅助筛选相关变量:应用于地西帕明的临床数据。","authors":"Innocent Gerald Asiimwe, Bonginkosi S'fiso Ndzamba, Samer Mouksassi, Goonaseelan Colin Pillai, Aurelie Lombard, Jennifer Lang","doi":"10.1208/s12248-024-00934-6","DOIUrl":null,"url":null,"abstract":"<p><p>Stepwise covariate modeling (SCM) has a high computational burden and can select the wrong covariates. Machine learning (ML) has been proposed as a screening tool to improve the efficiency of covariate selection, but little is known about how to apply ML on actual clinical data. First, we simulated datasets based on clinical data to compare the performance of various ML and traditional pharmacometrics (PMX) techniques with and without accounting for highly-correlated covariates. This simulation step identified the ML algorithm and the number of top covariates to select when using the actual clinical data. A previously developed desipramine population-pharmacokinetic model was used to simulate virtual subjects. Fifteen covariates were considered with four having an effect included. Based on the F1 score (an accuracy measure), ridge regression was the most accurate ML technique on 200 simulated datasets (F1 score = 0.475 ± 0.231), a performance which almost doubled when highly-correlated covariates were accounted for (F1 score = 0.860 ± 0.158). These performances were better than forwards selection with SCM (F1 score = 0.251 ± 0.274 and 0.499 ± 0.381 without/with correlations respectively). In terms of computational cost, ridge regression (0.42 ± 0.07 seconds/simulated dataset, 1 thread) was ~20,000 times faster than SCM (2.30 ± 2.29 hours, 15 threads). On the clinical dataset, prescreening with the selected ML algorithm reduced SCM runtime by 42.86% (from 1.75 to 1.00 days) and produced the same final model as SCM only. In conclusion, we have demonstrated that accounting for highly-correlated covariates improves ML prescreening accuracy. The choice of ML method and the proportion of important covariates (unknown a priori) can be guided by simulations.</p>","PeriodicalId":50934,"journal":{"name":"AAPS Journal","volume":"26 4","pages":"63"},"PeriodicalIF":3.4000,"publicationDate":"2024-05-30","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Machine-Learning Assisted Screening of Correlated Covariates: Application to Clinical Data of Desipramine.\",\"authors\":\"Innocent Gerald Asiimwe, Bonginkosi S'fiso Ndzamba, Samer Mouksassi, Goonaseelan Colin Pillai, Aurelie Lombard, Jennifer Lang\",\"doi\":\"10.1208/s12248-024-00934-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Stepwise covariate modeling (SCM) has a high computational burden and can select the wrong covariates. Machine learning (ML) has been proposed as a screening tool to improve the efficiency of covariate selection, but little is known about how to apply ML on actual clinical data. First, we simulated datasets based on clinical data to compare the performance of various ML and traditional pharmacometrics (PMX) techniques with and without accounting for highly-correlated covariates. This simulation step identified the ML algorithm and the number of top covariates to select when using the actual clinical data. A previously developed desipramine population-pharmacokinetic model was used to simulate virtual subjects. Fifteen covariates were considered with four having an effect included. Based on the F1 score (an accuracy measure), ridge regression was the most accurate ML technique on 200 simulated datasets (F1 score = 0.475 ± 0.231), a performance which almost doubled when highly-correlated covariates were accounted for (F1 score = 0.860 ± 0.158). These performances were better than forwards selection with SCM (F1 score = 0.251 ± 0.274 and 0.499 ± 0.381 without/with correlations respectively). In terms of computational cost, ridge regression (0.42 ± 0.07 seconds/simulated dataset, 1 thread) was ~20,000 times faster than SCM (2.30 ± 2.29 hours, 15 threads). On the clinical dataset, prescreening with the selected ML algorithm reduced SCM runtime by 42.86% (from 1.75 to 1.00 days) and produced the same final model as SCM only. In conclusion, we have demonstrated that accounting for highly-correlated covariates improves ML prescreening accuracy. The choice of ML method and the proportion of important covariates (unknown a priori) can be guided by simulations.</p>\",\"PeriodicalId\":50934,\"journal\":{\"name\":\"AAPS Journal\",\"volume\":\"26 4\",\"pages\":\"63\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2024-05-30\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"AAPS Journal\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1208/s12248-024-00934-6\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"PHARMACOLOGY & PHARMACY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"AAPS Journal","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1208/s12248-024-00934-6","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
引用次数: 0
摘要
逐步协变量建模(SCM)的计算负担很重,而且可能会选择错误的协变量。机器学习(ML)已被提出作为一种筛选工具来提高协变量选择的效率,但人们对如何将 ML 应用于实际临床数据知之甚少。首先,我们模拟了基于临床数据的数据集,以比较各种 ML 和传统药物计量学 (PMX) 技术在考虑和不考虑高度相关协变量的情况下的性能。这一模拟步骤确定了使用实际临床数据时要选择的 ML 算法和顶级协变量的数量。之前开发的地西帕明群体药代动力学模型被用于模拟虚拟受试者。考虑了 15 个协变量,其中 4 个具有影响。在 200 个模拟数据集上,根据 F1 分数(准确度衡量标准),脊回归是最准确的 ML 技术(F1 分数 = 0.475 ± 0.231),当考虑到高度相关的协变量时,这一性能几乎翻了一番(F1 分数 = 0.860 ± 0.158)。这些性能均优于使用单片机的前向选择(无/有相关性的 F1 分数分别为 0.251 ± 0.274 和 0.499 ± 0.381)。在计算成本方面,脊回归(0.42 ± 0.07 秒/模拟数据集,1 个线程)比单片机(2.30 ± 2.29 小时,15 个线程)快 2 万倍。在临床数据集上,使用选定的 ML 算法进行预筛选可将 SCM 的运行时间减少 42.86%(从 1.75 天减少到 1.00 天),并生成与 SCM 相同的最终模型。总之,我们已经证明,考虑高度相关的协变量可以提高 ML 预筛选的准确性。ML 方法的选择和重要协变量的比例(先验未知)可以通过模拟来指导。
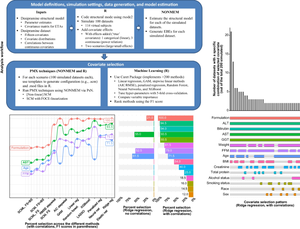
Machine-Learning Assisted Screening of Correlated Covariates: Application to Clinical Data of Desipramine.
Stepwise covariate modeling (SCM) has a high computational burden and can select the wrong covariates. Machine learning (ML) has been proposed as a screening tool to improve the efficiency of covariate selection, but little is known about how to apply ML on actual clinical data. First, we simulated datasets based on clinical data to compare the performance of various ML and traditional pharmacometrics (PMX) techniques with and without accounting for highly-correlated covariates. This simulation step identified the ML algorithm and the number of top covariates to select when using the actual clinical data. A previously developed desipramine population-pharmacokinetic model was used to simulate virtual subjects. Fifteen covariates were considered with four having an effect included. Based on the F1 score (an accuracy measure), ridge regression was the most accurate ML technique on 200 simulated datasets (F1 score = 0.475 ± 0.231), a performance which almost doubled when highly-correlated covariates were accounted for (F1 score = 0.860 ± 0.158). These performances were better than forwards selection with SCM (F1 score = 0.251 ± 0.274 and 0.499 ± 0.381 without/with correlations respectively). In terms of computational cost, ridge regression (0.42 ± 0.07 seconds/simulated dataset, 1 thread) was ~20,000 times faster than SCM (2.30 ± 2.29 hours, 15 threads). On the clinical dataset, prescreening with the selected ML algorithm reduced SCM runtime by 42.86% (from 1.75 to 1.00 days) and produced the same final model as SCM only. In conclusion, we have demonstrated that accounting for highly-correlated covariates improves ML prescreening accuracy. The choice of ML method and the proportion of important covariates (unknown a priori) can be guided by simulations.
期刊介绍:
The AAPS Journal, an official journal of the American Association of Pharmaceutical Scientists (AAPS), publishes novel and significant findings in the various areas of pharmaceutical sciences impacting human and veterinary therapeutics, including:
· Drug Design and Discovery
· Pharmaceutical Biotechnology
· Biopharmaceutics, Formulation, and Drug Delivery
· Metabolism and Transport
· Pharmacokinetics, Pharmacodynamics, and Pharmacometrics
· Translational Research
· Clinical Evaluations and Therapeutic Outcomes
· Regulatory Science
We invite submissions under the following article types:
· Original Research Articles
· Reviews and Mini-reviews
· White Papers, Commentaries, and Editorials
· Meeting Reports
· Brief/Technical Reports and Rapid Communications
· Regulatory Notes
· Tutorials
· Protocols in the Pharmaceutical Sciences
In addition, The AAPS Journal publishes themes, organized by guest editors, which are focused on particular areas of current interest to our field.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
