Marco Piccininni , Maximilian Wechsung , Ben Van Calster , Jessica L. Rohmann , Stefan Konigorski , Maarten van Smeden
{"title":"了解用于类不平衡校正的随机再采样技术及其对临床风险预测模型校准和判别的影响。","authors":"Marco Piccininni , Maximilian Wechsung , Ben Van Calster , Jessica L. Rohmann , Stefan Konigorski , Maarten van Smeden","doi":"10.1016/j.jbi.2024.104666","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective</h3><p>Class imbalance is sometimes considered a problem when developing clinical prediction models and assessing their performance. To address it, correction strategies involving manipulations of the training dataset, such as random undersampling or oversampling, are frequently used. The aim of this article is to illustrate the consequences of these class imbalance correction strategies on clinical prediction models’ internal validity in terms of calibration and discrimination performances.</p></div><div><h3>Methods</h3><p>We used both heuristic intuition and formal mathematical reasoning to characterize the relations between conditional probabilities of interest and probabilities targeted when using random undersampling or oversampling. We propose a plug-in estimator that represents a natural correction for predictions obtained from models that have been trained on artificially balanced datasets (“naïve” models). We conducted a Monte Carlo simulation with two different data generation processes and present a real-world example using data from the International Stroke Trial database to empirically demonstrate the consequences of applying random resampling techniques for class imbalance correction on calibration and discrimination (in terms of Area Under the ROC, AUC) for logistic regression and tree-based prediction models.</p></div><div><h3>Results</h3><p>Across our simulations and in the real-world example, calibration of the naïve models was very poor. The models using the plug-in estimator generally outperformed the models relying on class imbalance correction in terms of calibration while achieving the same discrimination performance.</p></div><div><h3>Conclusion</h3><p>Random resampling techniques for class imbalance correction do not generally improve discrimination performance (i.e., AUC), and their use is hard to justify when aiming at providing calibrated predictions. Improper use of such class imbalance correction techniques can lead to suboptimal data usage and less valid risk prediction models.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"155 ","pages":"Article 104666"},"PeriodicalIF":5.9000,"publicationDate":"2024-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Understanding random resampling techniques for class imbalance correction and their consequences on calibration and discrimination of clinical risk prediction models\",\"authors\":\"Marco Piccininni , Maximilian Wechsung , Ben Van Calster , Jessica L. Rohmann , Stefan Konigorski , Maarten van Smeden\",\"doi\":\"10.1016/j.jbi.2024.104666\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective</h3><p>Class imbalance is sometimes considered a problem when developing clinical prediction models and assessing their performance. To address it, correction strategies involving manipulations of the training dataset, such as random undersampling or oversampling, are frequently used. The aim of this article is to illustrate the consequences of these class imbalance correction strategies on clinical prediction models’ internal validity in terms of calibration and discrimination performances.</p></div><div><h3>Methods</h3><p>We used both heuristic intuition and formal mathematical reasoning to characterize the relations between conditional probabilities of interest and probabilities targeted when using random undersampling or oversampling. We propose a plug-in estimator that represents a natural correction for predictions obtained from models that have been trained on artificially balanced datasets (“naïve” models). We conducted a Monte Carlo simulation with two different data generation processes and present a real-world example using data from the International Stroke Trial database to empirically demonstrate the consequences of applying random resampling techniques for class imbalance correction on calibration and discrimination (in terms of Area Under the ROC, AUC) for logistic regression and tree-based prediction models.</p></div><div><h3>Results</h3><p>Across our simulations and in the real-world example, calibration of the naïve models was very poor. The models using the plug-in estimator generally outperformed the models relying on class imbalance correction in terms of calibration while achieving the same discrimination performance.</p></div><div><h3>Conclusion</h3><p>Random resampling techniques for class imbalance correction do not generally improve discrimination performance (i.e., AUC), and their use is hard to justify when aiming at providing calibrated predictions. Improper use of such class imbalance correction techniques can lead to suboptimal data usage and less valid risk prediction models.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"155 \",\"pages\":\"Article 104666\"},\"PeriodicalIF\":5.9000,\"publicationDate\":\"2024-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424000844\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/6/6 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424000844","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/6/6 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
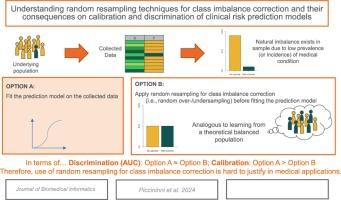
Understanding random resampling techniques for class imbalance correction and their consequences on calibration and discrimination of clinical risk prediction models
Objective
Class imbalance is sometimes considered a problem when developing clinical prediction models and assessing their performance. To address it, correction strategies involving manipulations of the training dataset, such as random undersampling or oversampling, are frequently used. The aim of this article is to illustrate the consequences of these class imbalance correction strategies on clinical prediction models’ internal validity in terms of calibration and discrimination performances.
Methods
We used both heuristic intuition and formal mathematical reasoning to characterize the relations between conditional probabilities of interest and probabilities targeted when using random undersampling or oversampling. We propose a plug-in estimator that represents a natural correction for predictions obtained from models that have been trained on artificially balanced datasets (“naïve” models). We conducted a Monte Carlo simulation with two different data generation processes and present a real-world example using data from the International Stroke Trial database to empirically demonstrate the consequences of applying random resampling techniques for class imbalance correction on calibration and discrimination (in terms of Area Under the ROC, AUC) for logistic regression and tree-based prediction models.
Results
Across our simulations and in the real-world example, calibration of the naïve models was very poor. The models using the plug-in estimator generally outperformed the models relying on class imbalance correction in terms of calibration while achieving the same discrimination performance.
Conclusion
Random resampling techniques for class imbalance correction do not generally improve discrimination performance (i.e., AUC), and their use is hard to justify when aiming at providing calibrated predictions. Improper use of such class imbalance correction techniques can lead to suboptimal data usage and less valid risk prediction models.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
