Dong-Xin Ye , Jun-Wen Yu , Rui Li , Yu-Duo Hao , Tian-Yu Wang , Hui Yang , Hui Ding
{"title":"基于自动机器学习的重组热点预测。","authors":"Dong-Xin Ye , Jun-Wen Yu , Rui Li , Yu-Duo Hao , Tian-Yu Wang , Hui Yang , Hui Ding","doi":"10.1016/j.jmb.2024.168653","DOIUrl":null,"url":null,"abstract":"<div><div>Meiotic recombination plays a pivotal role in genetic evolution. Genetic variation induced by recombination is a crucial factor in generating biodiversity and a driving force for evolution. At present, the development of recombination hotspot prediction methods has encountered challenges related to insufficient feature extraction and limited generalization capabilities. This paper focused on the research of recombination hotspot prediction methods. We explored deep learning-based recombination hotspot prediction and scrutinized the shortcomings of prevalent models in addressing the challenge of recombination hotspot prediction. To addressing these deficiencies, an automated machine learning approach was utilized to construct recombination hotspot prediction model. The model combined sequence information with physicochemical properties by employing TF-IDF-Kmer and DNA composition components to acquire more effective feature data. Experimental results validate the effectiveness of the feature extraction method and automated machine learning technology used in this study. The final model was validated on three distinct datasets and yielded accuracy rates of 97.14%, 79.71%, and 98.73%, surpassing the current leading models by 2%, 2.56%, and 4%, respectively. In addition, we incorporated tools such as SHAP and AutoGluon to analyze the interpretability of black-box models, delved into the impact of individual features on the results, and investigated the reasons behind misclassification of samples. Finally, an application of recombination hotspot prediction was established to facilitate easy access to necessary information and tools for researchers. The research outcomes of this paper underscore the enormous potential of automated machine learning methods in gene sequence prediction.</div></div>","PeriodicalId":369,"journal":{"name":"Journal of Molecular Biology","volume":"437 6","pages":"Article 168653"},"PeriodicalIF":4.7000,"publicationDate":"2025-03-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"The Prediction of Recombination Hotspot Based on Automated Machine Learning\",\"authors\":\"Dong-Xin Ye , Jun-Wen Yu , Rui Li , Yu-Duo Hao , Tian-Yu Wang , Hui Yang , Hui Ding\",\"doi\":\"10.1016/j.jmb.2024.168653\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Meiotic recombination plays a pivotal role in genetic evolution. Genetic variation induced by recombination is a crucial factor in generating biodiversity and a driving force for evolution. At present, the development of recombination hotspot prediction methods has encountered challenges related to insufficient feature extraction and limited generalization capabilities. This paper focused on the research of recombination hotspot prediction methods. We explored deep learning-based recombination hotspot prediction and scrutinized the shortcomings of prevalent models in addressing the challenge of recombination hotspot prediction. To addressing these deficiencies, an automated machine learning approach was utilized to construct recombination hotspot prediction model. The model combined sequence information with physicochemical properties by employing TF-IDF-Kmer and DNA composition components to acquire more effective feature data. Experimental results validate the effectiveness of the feature extraction method and automated machine learning technology used in this study. The final model was validated on three distinct datasets and yielded accuracy rates of 97.14%, 79.71%, and 98.73%, surpassing the current leading models by 2%, 2.56%, and 4%, respectively. In addition, we incorporated tools such as SHAP and AutoGluon to analyze the interpretability of black-box models, delved into the impact of individual features on the results, and investigated the reasons behind misclassification of samples. Finally, an application of recombination hotspot prediction was established to facilitate easy access to necessary information and tools for researchers. The research outcomes of this paper underscore the enormous potential of automated machine learning methods in gene sequence prediction.</div></div>\",\"PeriodicalId\":369,\"journal\":{\"name\":\"Journal of Molecular Biology\",\"volume\":\"437 6\",\"pages\":\"Article 168653\"},\"PeriodicalIF\":4.7000,\"publicationDate\":\"2025-03-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Molecular Biology\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0022283624002481\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/6/12 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMISTRY & MOLECULAR BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Molecular Biology","FirstCategoryId":"99","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0022283624002481","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/6/12 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
The Prediction of Recombination Hotspot Based on Automated Machine Learning
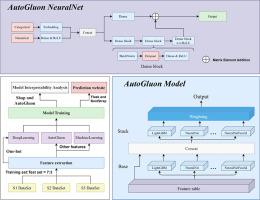
Meiotic recombination plays a pivotal role in genetic evolution. Genetic variation induced by recombination is a crucial factor in generating biodiversity and a driving force for evolution. At present, the development of recombination hotspot prediction methods has encountered challenges related to insufficient feature extraction and limited generalization capabilities. This paper focused on the research of recombination hotspot prediction methods. We explored deep learning-based recombination hotspot prediction and scrutinized the shortcomings of prevalent models in addressing the challenge of recombination hotspot prediction. To addressing these deficiencies, an automated machine learning approach was utilized to construct recombination hotspot prediction model. The model combined sequence information with physicochemical properties by employing TF-IDF-Kmer and DNA composition components to acquire more effective feature data. Experimental results validate the effectiveness of the feature extraction method and automated machine learning technology used in this study. The final model was validated on three distinct datasets and yielded accuracy rates of 97.14%, 79.71%, and 98.73%, surpassing the current leading models by 2%, 2.56%, and 4%, respectively. In addition, we incorporated tools such as SHAP and AutoGluon to analyze the interpretability of black-box models, delved into the impact of individual features on the results, and investigated the reasons behind misclassification of samples. Finally, an application of recombination hotspot prediction was established to facilitate easy access to necessary information and tools for researchers. The research outcomes of this paper underscore the enormous potential of automated machine learning methods in gene sequence prediction.
期刊介绍:
Journal of Molecular Biology (JMB) provides high quality, comprehensive and broad coverage in all areas of molecular biology. The journal publishes original scientific research papers that provide mechanistic and functional insights and report a significant advance to the field. The journal encourages the submission of multidisciplinary studies that use complementary experimental and computational approaches to address challenging biological questions.
Research areas include but are not limited to: Biomolecular interactions, signaling networks, systems biology; Cell cycle, cell growth, cell differentiation; Cell death, autophagy; Cell signaling and regulation; Chemical biology; Computational biology, in combination with experimental studies; DNA replication, repair, and recombination; Development, regenerative biology, mechanistic and functional studies of stem cells; Epigenetics, chromatin structure and function; Gene expression; Membrane processes, cell surface proteins and cell-cell interactions; Methodological advances, both experimental and theoretical, including databases; Microbiology, virology, and interactions with the host or environment; Microbiota mechanistic and functional studies; Nuclear organization; Post-translational modifications, proteomics; Processing and function of biologically important macromolecules and complexes; Molecular basis of disease; RNA processing, structure and functions of non-coding RNAs, transcription; Sorting, spatiotemporal organization, trafficking; Structural biology; Synthetic biology; Translation, protein folding, chaperones, protein degradation and quality control.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
