{"title":"采用修正交叉验证和 Bootstrap 调整的惩罚回归方法可生成更好的预测模型。","authors":"Menelaos Pavlou, Rumana Z. Omar, Gareth Ambler","doi":"10.1002/bimj.202300245","DOIUrl":null,"url":null,"abstract":"<p>Risk prediction models fitted using maximum likelihood estimation (MLE) are often overfitted resulting in predictions that are too extreme and a calibration slope (CS) less than 1. Penalized methods, such as Ridge and Lasso, have been suggested as a solution to this problem as they tend to shrink regression coefficients toward zero, resulting in predictions closer to the average. The amount of shrinkage is regulated by a tuning parameter, <span></span><math>\n <semantics>\n <mrow>\n <mi>λ</mi>\n <mo>,</mo>\n </mrow>\n <annotation>$\\lambda ,$</annotation>\n </semantics></math> commonly selected via cross-validation (“standard tuning”). Though penalized methods have been found to improve calibration on average, they often over-shrink and exhibit large variability in the selected <span></span><math>\n <semantics>\n <mi>λ</mi>\n <annotation>$\\lambda $</annotation>\n </semantics></math> and hence the CS. This is a problem, particularly for small sample sizes, but also when using sample sizes recommended to control overfitting. We consider whether these problems are partly due to selecting <span></span><math>\n <semantics>\n <mi>λ</mi>\n <annotation>$\\lambda $</annotation>\n </semantics></math> using cross-validation with “training” datasets of reduced size compared to the original development sample, resulting in an over-estimation of <span></span><math>\n <semantics>\n <mi>λ</mi>\n <annotation>$\\lambda $</annotation>\n </semantics></math> and, hence, excessive shrinkage. We propose a modified cross-validation tuning method (“modified tuning”), which estimates <span></span><math>\n <semantics>\n <mi>λ</mi>\n <annotation>$\\lambda $</annotation>\n </semantics></math> from a pseudo-development dataset obtained via bootstrapping from the original dataset, albeit of larger size, such that the resulting cross-validation training datasets are of the same size as the original dataset. Modified tuning can be easily implemented in standard software and is closely related to bootstrap selection of the tuning parameter (“bootstrap tuning”). We evaluated modified and bootstrap tuning for Ridge and Lasso in simulated and real data using recommended sample sizes, and sizes slightly lower and higher. They substantially improved the selection of <span></span><math>\n <semantics>\n <mi>λ</mi>\n <annotation>$\\lambda $</annotation>\n </semantics></math>, resulting in improved CS compared to the standard tuning method. They also improved predictions compared to MLE.</p>","PeriodicalId":55360,"journal":{"name":"Biometrical Journal","volume":"66 5","pages":""},"PeriodicalIF":2.1000,"publicationDate":"2024-06-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/bimj.202300245","citationCount":"0","resultStr":"{\"title\":\"Penalized Regression Methods With Modified Cross-Validation and Bootstrap Tuning Produce Better Prediction Models\",\"authors\":\"Menelaos Pavlou, Rumana Z. Omar, Gareth Ambler\",\"doi\":\"10.1002/bimj.202300245\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Risk prediction models fitted using maximum likelihood estimation (MLE) are often overfitted resulting in predictions that are too extreme and a calibration slope (CS) less than 1. Penalized methods, such as Ridge and Lasso, have been suggested as a solution to this problem as they tend to shrink regression coefficients toward zero, resulting in predictions closer to the average. The amount of shrinkage is regulated by a tuning parameter, <span></span><math>\\n <semantics>\\n <mrow>\\n <mi>λ</mi>\\n <mo>,</mo>\\n </mrow>\\n <annotation>$\\\\lambda ,$</annotation>\\n </semantics></math> commonly selected via cross-validation (“standard tuning”). Though penalized methods have been found to improve calibration on average, they often over-shrink and exhibit large variability in the selected <span></span><math>\\n <semantics>\\n <mi>λ</mi>\\n <annotation>$\\\\lambda $</annotation>\\n </semantics></math> and hence the CS. This is a problem, particularly for small sample sizes, but also when using sample sizes recommended to control overfitting. We consider whether these problems are partly due to selecting <span></span><math>\\n <semantics>\\n <mi>λ</mi>\\n <annotation>$\\\\lambda $</annotation>\\n </semantics></math> using cross-validation with “training” datasets of reduced size compared to the original development sample, resulting in an over-estimation of <span></span><math>\\n <semantics>\\n <mi>λ</mi>\\n <annotation>$\\\\lambda $</annotation>\\n </semantics></math> and, hence, excessive shrinkage. We propose a modified cross-validation tuning method (“modified tuning”), which estimates <span></span><math>\\n <semantics>\\n <mi>λ</mi>\\n <annotation>$\\\\lambda $</annotation>\\n </semantics></math> from a pseudo-development dataset obtained via bootstrapping from the original dataset, albeit of larger size, such that the resulting cross-validation training datasets are of the same size as the original dataset. Modified tuning can be easily implemented in standard software and is closely related to bootstrap selection of the tuning parameter (“bootstrap tuning”). We evaluated modified and bootstrap tuning for Ridge and Lasso in simulated and real data using recommended sample sizes, and sizes slightly lower and higher. They substantially improved the selection of <span></span><math>\\n <semantics>\\n <mi>λ</mi>\\n <annotation>$\\\\lambda $</annotation>\\n </semantics></math>, resulting in improved CS compared to the standard tuning method. They also improved predictions compared to MLE.</p>\",\"PeriodicalId\":55360,\"journal\":{\"name\":\"Biometrical Journal\",\"volume\":\"66 5\",\"pages\":\"\"},\"PeriodicalIF\":2.1000,\"publicationDate\":\"2024-06-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/bimj.202300245\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biometrical Journal\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/bimj.202300245\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biometrical Journal","FirstCategoryId":"99","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/bimj.202300245","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Penalized Regression Methods With Modified Cross-Validation and Bootstrap Tuning Produce Better Prediction Models
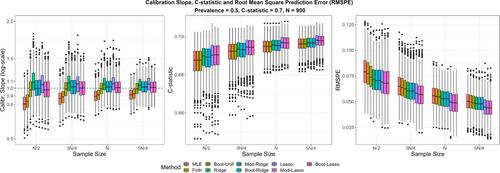
Risk prediction models fitted using maximum likelihood estimation (MLE) are often overfitted resulting in predictions that are too extreme and a calibration slope (CS) less than 1. Penalized methods, such as Ridge and Lasso, have been suggested as a solution to this problem as they tend to shrink regression coefficients toward zero, resulting in predictions closer to the average. The amount of shrinkage is regulated by a tuning parameter, commonly selected via cross-validation (“standard tuning”). Though penalized methods have been found to improve calibration on average, they often over-shrink and exhibit large variability in the selected and hence the CS. This is a problem, particularly for small sample sizes, but also when using sample sizes recommended to control overfitting. We consider whether these problems are partly due to selecting using cross-validation with “training” datasets of reduced size compared to the original development sample, resulting in an over-estimation of and, hence, excessive shrinkage. We propose a modified cross-validation tuning method (“modified tuning”), which estimates from a pseudo-development dataset obtained via bootstrapping from the original dataset, albeit of larger size, such that the resulting cross-validation training datasets are of the same size as the original dataset. Modified tuning can be easily implemented in standard software and is closely related to bootstrap selection of the tuning parameter (“bootstrap tuning”). We evaluated modified and bootstrap tuning for Ridge and Lasso in simulated and real data using recommended sample sizes, and sizes slightly lower and higher. They substantially improved the selection of , resulting in improved CS compared to the standard tuning method. They also improved predictions compared to MLE.
期刊介绍:
Biometrical Journal publishes papers on statistical methods and their applications in life sciences including medicine, environmental sciences and agriculture. Methodological developments should be motivated by an interesting and relevant problem from these areas. Ideally the manuscript should include a description of the problem and a section detailing the application of the new methodology to the problem. Case studies, review articles and letters to the editors are also welcome. Papers containing only extensive mathematical theory are not suitable for publication in Biometrical Journal.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
