Jens H. Fünderich, Lukas J. Beinhauer, Frank Renkewitz
{"title":"减少、再利用、再循环:介绍 MetaPipeX,一个多实验室数据分析框架。","authors":"Jens H. Fünderich, Lukas J. Beinhauer, Frank Renkewitz","doi":"10.1002/jrsm.1733","DOIUrl":null,"url":null,"abstract":"<p>Multi-lab projects are large scale collaborations between participating data collection sites that gather empirical evidence and (usually) analyze that evidence using meta-analyses. They are a valuable form of scientific collaboration, produce outstanding data sets and are a great resource for third-party researchers. Their data may be reanalyzed and used in research synthesis. Their repositories and code could provide guidance to future projects of this kind. But, while multi-labs are similar in their structure and aggregate their data using meta-analyses, they deploy a variety of different solutions regarding the storage structure in the repositories, the way the (analysis) code is structured and the file-formats they provide. Continuing this trend implies that anyone who wants to work with data from multiple of these projects, or combine their datasets, is faced with an ever-increasing complexity. Some of that complexity could be avoided. Here, we introduce MetaPipeX, a standardized framework to harmonize, document and analyze multi-lab data. It features a pipeline conceptualization of the analysis and documentation process, an R-package that implements both and a Shiny App (https://www.apps.meta-rep.lmu.de/metapipex/) that allows users to explore and visualize these data sets. We introduce the framework by describing its components and applying it to a practical example. Engaging with this form of collaboration and integrating it further into research practice will certainly be beneficial to quantitative sciences and we hope the framework provides a structure and tools to reduce effort for anyone who creates, re-uses, harmonizes or learns about multi-lab replication projects.</p>","PeriodicalId":226,"journal":{"name":"Research Synthesis Methods","volume":"15 6","pages":"1183-1199"},"PeriodicalIF":6.1000,"publicationDate":"2024-06-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/jrsm.1733","citationCount":"0","resultStr":"{\"title\":\"Reduce, reuse, recycle: Introducing MetaPipeX, a framework for analyses of multi-lab data\",\"authors\":\"Jens H. Fünderich, Lukas J. Beinhauer, Frank Renkewitz\",\"doi\":\"10.1002/jrsm.1733\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Multi-lab projects are large scale collaborations between participating data collection sites that gather empirical evidence and (usually) analyze that evidence using meta-analyses. They are a valuable form of scientific collaboration, produce outstanding data sets and are a great resource for third-party researchers. Their data may be reanalyzed and used in research synthesis. Their repositories and code could provide guidance to future projects of this kind. But, while multi-labs are similar in their structure and aggregate their data using meta-analyses, they deploy a variety of different solutions regarding the storage structure in the repositories, the way the (analysis) code is structured and the file-formats they provide. Continuing this trend implies that anyone who wants to work with data from multiple of these projects, or combine their datasets, is faced with an ever-increasing complexity. Some of that complexity could be avoided. Here, we introduce MetaPipeX, a standardized framework to harmonize, document and analyze multi-lab data. It features a pipeline conceptualization of the analysis and documentation process, an R-package that implements both and a Shiny App (https://www.apps.meta-rep.lmu.de/metapipex/) that allows users to explore and visualize these data sets. We introduce the framework by describing its components and applying it to a practical example. Engaging with this form of collaboration and integrating it further into research practice will certainly be beneficial to quantitative sciences and we hope the framework provides a structure and tools to reduce effort for anyone who creates, re-uses, harmonizes or learns about multi-lab replication projects.</p>\",\"PeriodicalId\":226,\"journal\":{\"name\":\"Research Synthesis Methods\",\"volume\":\"15 6\",\"pages\":\"1183-1199\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2024-06-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/jrsm.1733\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Research Synthesis Methods\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/jrsm.1733\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Research Synthesis Methods","FirstCategoryId":"99","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/jrsm.1733","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
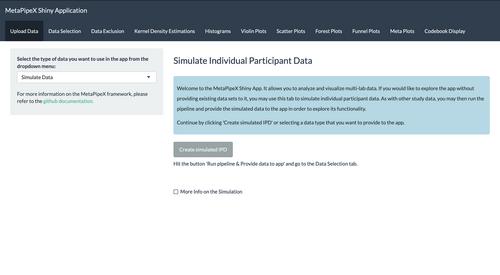
多实验室项目是参与数据收集站点之间的大规模合作,这些站点收集经验证据,并(通常)使用元分析对证据进行分析。它们是一种有价值的科学合作形式,能产生出色的数据集,是第三方研究人员的重要资源。它们的数据可以重新分析并用于研究综述。它们的资料库和代码可以为未来的此类项目提供指导。不过,虽然多重实验室在结构上相似,并使用元分析汇总数据,但它们在资源库的存储结构、(分析)代码的结构方式以及提供的文件格式方面却采用了各种不同的解决方案。继续保持这种趋势意味着,任何人想要处理来自多个此类项目的数据或合并数据集,都会面临日益增加的复杂性。其中一些复杂性是可以避免的。在此,我们介绍 MetaPipeX,这是一个用于协调、记录和分析多个实验室数据的标准化框架。它的特点包括:分析和记录过程的管道概念化、实现这两个过程的 R 包以及允许用户探索和可视化这些数据集的 Shiny App (https://www.apps.meta-rep.lmu.de/metapipex/)。我们介绍了该框架的各个组成部分,并将其应用到一个实际例子中。参与这种形式的合作并将其进一步整合到研究实践中肯定会对定量科学有益,我们希望该框架能为创建、重用、协调或学习多实验室复制项目的任何人提供结构和工具,以减少工作量。
Reduce, reuse, recycle: Introducing MetaPipeX, a framework for analyses of multi-lab data
Multi-lab projects are large scale collaborations between participating data collection sites that gather empirical evidence and (usually) analyze that evidence using meta-analyses. They are a valuable form of scientific collaboration, produce outstanding data sets and are a great resource for third-party researchers. Their data may be reanalyzed and used in research synthesis. Their repositories and code could provide guidance to future projects of this kind. But, while multi-labs are similar in their structure and aggregate their data using meta-analyses, they deploy a variety of different solutions regarding the storage structure in the repositories, the way the (analysis) code is structured and the file-formats they provide. Continuing this trend implies that anyone who wants to work with data from multiple of these projects, or combine their datasets, is faced with an ever-increasing complexity. Some of that complexity could be avoided. Here, we introduce MetaPipeX, a standardized framework to harmonize, document and analyze multi-lab data. It features a pipeline conceptualization of the analysis and documentation process, an R-package that implements both and a Shiny App (https://www.apps.meta-rep.lmu.de/metapipex/) that allows users to explore and visualize these data sets. We introduce the framework by describing its components and applying it to a practical example. Engaging with this form of collaboration and integrating it further into research practice will certainly be beneficial to quantitative sciences and we hope the framework provides a structure and tools to reduce effort for anyone who creates, re-uses, harmonizes or learns about multi-lab replication projects.
期刊介绍:
Research Synthesis Methods is a reputable, peer-reviewed journal that focuses on the development and dissemination of methods for conducting systematic research synthesis. Our aim is to advance the knowledge and application of research synthesis methods across various disciplines.
Our journal provides a platform for the exchange of ideas and knowledge related to designing, conducting, analyzing, interpreting, reporting, and applying research synthesis. While research synthesis is commonly practiced in the health and social sciences, our journal also welcomes contributions from other fields to enrich the methodologies employed in research synthesis across scientific disciplines.
By bridging different disciplines, we aim to foster collaboration and cross-fertilization of ideas, ultimately enhancing the quality and effectiveness of research synthesis methods. Whether you are a researcher, practitioner, or stakeholder involved in research synthesis, our journal strives to offer valuable insights and practical guidance for your work.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
