Oluwatobiloba Ayo-Ajibola BS, Ryan J. Davis BS, Matthew E. Lin MD, Neelaysh Vukkadala MD, Karla O'Dell MD, Mark S. Swanson MD, Michael M. Johns III MD, Elizabeth A. Shuman MD
{"title":"TrachGPT:人工智能聊天机器人对气管造口护理建议的评估。","authors":"Oluwatobiloba Ayo-Ajibola BS, Ryan J. Davis BS, Matthew E. Lin MD, Neelaysh Vukkadala MD, Karla O'Dell MD, Mark S. Swanson MD, Michael M. Johns III MD, Elizabeth A. Shuman MD","doi":"10.1002/lio2.1300","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Objective</h3>\n \n <p>Safe home tracheostomy care requires engagement and troubleshooting by patients, who may turn to online, AI-generated information sources. This study assessed the quality of ChatGPT responses to such queries.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>In this cross-sectional study, ChatGPT was prompted with 10 hypothetical tracheostomy care questions in three domains (complication management, self-care advice, and lifestyle adjustment). Responses were graded by four otolaryngologists for appropriateness, accuracy, and overall score. The readability of responses was evaluated using the Flesch Reading Ease (FRE) and Flesch–Kincaid Reading Grade Level (FKRGL). Descriptive statistics and ANOVA testing were performed with statistical significance set to <i>p</i> < .05.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>On a scale of 1–5, with 5 representing the greatest appropriateness or overall score and a 4-point scale with 4 representing the highest accuracy, the responses exhibited moderately high appropriateness (mean = 4.10, SD = 0.90), high accuracy (mean = 3.55, SD = 0.50), and moderately high overall scores (mean = 4.02, SD = 0.86). Scoring between response categories (self-care recommendations, complication recommendations, lifestyle adjustments, and special device considerations) revealed no significant scoring differences. Suboptimal responses lacked nuance and contained incorrect information and recommendations. Readability indicated college and advanced levels for FRE (Mean = 39.5, SD = 7.17) and FKRGL (Mean = 13.1, SD = 1.47), higher than the sixth-grade level recommended for patient-targeted resources by the NIH.</p>\n </section>\n \n <section>\n \n <h3> Conclusion</h3>\n \n <p>While ChatGPT-generated tracheostomy care responses may exhibit acceptable appropriateness, incomplete or misleading information may have dire clinical consequences. Further, inappropriately high reading levels may limit patient comprehension and accessibility. At this point in its technological infancy, AI-generated information should not be solely relied upon as a direct patient care resource.</p>\n </section>\n </div>","PeriodicalId":48529,"journal":{"name":"Laryngoscope Investigative Otolaryngology","volume":"9 4","pages":""},"PeriodicalIF":1.9000,"publicationDate":"2024-07-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11250132/pdf/","citationCount":"0","resultStr":"{\"title\":\"TrachGPT: Appraisal of tracheostomy care recommendations from an artificial intelligent Chatbot\",\"authors\":\"Oluwatobiloba Ayo-Ajibola BS, Ryan J. Davis BS, Matthew E. Lin MD, Neelaysh Vukkadala MD, Karla O'Dell MD, Mark S. Swanson MD, Michael M. Johns III MD, Elizabeth A. Shuman MD\",\"doi\":\"10.1002/lio2.1300\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Objective</h3>\\n \\n <p>Safe home tracheostomy care requires engagement and troubleshooting by patients, who may turn to online, AI-generated information sources. This study assessed the quality of ChatGPT responses to such queries.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Methods</h3>\\n \\n <p>In this cross-sectional study, ChatGPT was prompted with 10 hypothetical tracheostomy care questions in three domains (complication management, self-care advice, and lifestyle adjustment). Responses were graded by four otolaryngologists for appropriateness, accuracy, and overall score. The readability of responses was evaluated using the Flesch Reading Ease (FRE) and Flesch–Kincaid Reading Grade Level (FKRGL). Descriptive statistics and ANOVA testing were performed with statistical significance set to <i>p</i> < .05.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Results</h3>\\n \\n <p>On a scale of 1–5, with 5 representing the greatest appropriateness or overall score and a 4-point scale with 4 representing the highest accuracy, the responses exhibited moderately high appropriateness (mean = 4.10, SD = 0.90), high accuracy (mean = 3.55, SD = 0.50), and moderately high overall scores (mean = 4.02, SD = 0.86). Scoring between response categories (self-care recommendations, complication recommendations, lifestyle adjustments, and special device considerations) revealed no significant scoring differences. Suboptimal responses lacked nuance and contained incorrect information and recommendations. Readability indicated college and advanced levels for FRE (Mean = 39.5, SD = 7.17) and FKRGL (Mean = 13.1, SD = 1.47), higher than the sixth-grade level recommended for patient-targeted resources by the NIH.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Conclusion</h3>\\n \\n <p>While ChatGPT-generated tracheostomy care responses may exhibit acceptable appropriateness, incomplete or misleading information may have dire clinical consequences. Further, inappropriately high reading levels may limit patient comprehension and accessibility. At this point in its technological infancy, AI-generated information should not be solely relied upon as a direct patient care resource.</p>\\n </section>\\n </div>\",\"PeriodicalId\":48529,\"journal\":{\"name\":\"Laryngoscope Investigative Otolaryngology\",\"volume\":\"9 4\",\"pages\":\"\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2024-07-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11250132/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Laryngoscope Investigative Otolaryngology\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/lio2.1300\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"OTORHINOLARYNGOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Laryngoscope Investigative Otolaryngology","FirstCategoryId":"3","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/lio2.1300","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"OTORHINOLARYNGOLOGY","Score":null,"Total":0}
TrachGPT: Appraisal of tracheostomy care recommendations from an artificial intelligent Chatbot
Objective
Safe home tracheostomy care requires engagement and troubleshooting by patients, who may turn to online, AI-generated information sources. This study assessed the quality of ChatGPT responses to such queries.
Methods
In this cross-sectional study, ChatGPT was prompted with 10 hypothetical tracheostomy care questions in three domains (complication management, self-care advice, and lifestyle adjustment). Responses were graded by four otolaryngologists for appropriateness, accuracy, and overall score. The readability of responses was evaluated using the Flesch Reading Ease (FRE) and Flesch–Kincaid Reading Grade Level (FKRGL). Descriptive statistics and ANOVA testing were performed with statistical significance set to p < .05.
Results
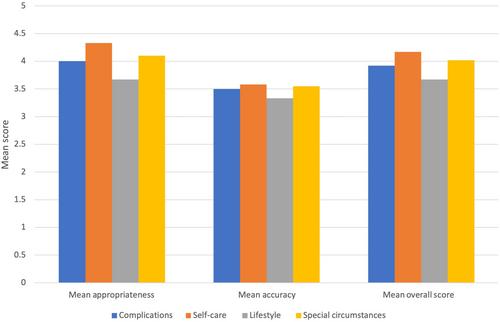
On a scale of 1–5, with 5 representing the greatest appropriateness or overall score and a 4-point scale with 4 representing the highest accuracy, the responses exhibited moderately high appropriateness (mean = 4.10, SD = 0.90), high accuracy (mean = 3.55, SD = 0.50), and moderately high overall scores (mean = 4.02, SD = 0.86). Scoring between response categories (self-care recommendations, complication recommendations, lifestyle adjustments, and special device considerations) revealed no significant scoring differences. Suboptimal responses lacked nuance and contained incorrect information and recommendations. Readability indicated college and advanced levels for FRE (Mean = 39.5, SD = 7.17) and FKRGL (Mean = 13.1, SD = 1.47), higher than the sixth-grade level recommended for patient-targeted resources by the NIH.
Conclusion
While ChatGPT-generated tracheostomy care responses may exhibit acceptable appropriateness, incomplete or misleading information may have dire clinical consequences. Further, inappropriately high reading levels may limit patient comprehension and accessibility. At this point in its technological infancy, AI-generated information should not be solely relied upon as a direct patient care resource.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
