{"title":"眼科检索增强大型语言模型框架的开发与评估。","authors":"Ming-Jie Luo, Jianyu Pang, Shaowei Bi, Yunxi Lai, Jiaman Zhao, Yuanrui Shang, Tingxin Cui, Yahan Yang, Zhenzhe Lin, Lanqin Zhao, Xiaohang Wu, Duoru Lin, Jingjing Chen, Haotian Lin","doi":"10.1001/jamaophthalmol.2024.2513","DOIUrl":null,"url":null,"abstract":"<p><strong>Importance: </strong>Although augmenting large language models (LLMs) with knowledge bases may improve medical domain-specific performance, practical methods are needed for local implementation of LLMs that address privacy concerns and enhance accessibility for health care professionals.</p><p><strong>Objective: </strong>To develop an accurate, cost-effective local implementation of an LLM to mitigate privacy concerns and support their practical deployment in health care settings.</p><p><strong>Design, setting, and participants: </strong>ChatZOC (Sun Yat-Sen University Zhongshan Ophthalmology Center), a retrieval-augmented LLM framework, was developed by enhancing a baseline LLM with a comprehensive ophthalmic dataset and evaluation framework (CODE), which includes over 30 000 pieces of ophthalmic knowledge. This LLM was benchmarked against 10 representative LLMs, including GPT-4 and GPT-3.5 Turbo (OpenAI), across 300 clinical questions in ophthalmology. The evaluation, involving a panel of medical experts and biomedical researchers, focused on accuracy, utility, and safety. A double-masked approach was used to try to minimize bias assessment across all models. The study used a comprehensive knowledge base derived from ophthalmic clinical practice, without directly involving clinical patients.</p><p><strong>Exposures: </strong>LLM response to clinical questions.</p><p><strong>Main outcomes and measures: </strong>Accuracy, utility, and safety of LLMs in responding to clinical questions.</p><p><strong>Results: </strong>The baseline model achieved a human ranking score of 0.48. The retrieval-augmented LLM had a score of 0.60, a difference of 0.12 (95% CI, 0.02-0.22; P = .02) from baseline and not different from GPT-4 with a score of 0.61 (difference = 0.01; 95% CI, -0.11 to 0.13; P = .89). For scientific consensus, the retrieval-augmented LLM was 84.0% compared with the baseline model of 46.5% (difference = 37.5%; 95% CI, 29.0%-46.0%; P < .001) and not different from GPT-4 with a value of 79.2% (difference = 4.8%; 95% CI, -0.3% to 10.0%; P = .06).</p><p><strong>Conclusions and relevance: </strong>Results of this quality improvement study suggest that the integration of high-quality knowledge bases improved the LLM's performance in medical domains. This study highlights the transformative potential of augmented LLMs in clinical practice by providing reliable, safe, and practical clinical information. Further research is needed to explore the broader application of such frameworks in the real world.</p>","PeriodicalId":14518,"journal":{"name":"JAMA ophthalmology","volume":" ","pages":"798-805"},"PeriodicalIF":9.2000,"publicationDate":"2024-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11258636/pdf/","citationCount":"0","resultStr":"{\"title\":\"Development and Evaluation of a Retrieval-Augmented Large Language Model Framework for Ophthalmology.\",\"authors\":\"Ming-Jie Luo, Jianyu Pang, Shaowei Bi, Yunxi Lai, Jiaman Zhao, Yuanrui Shang, Tingxin Cui, Yahan Yang, Zhenzhe Lin, Lanqin Zhao, Xiaohang Wu, Duoru Lin, Jingjing Chen, Haotian Lin\",\"doi\":\"10.1001/jamaophthalmol.2024.2513\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Importance: </strong>Although augmenting large language models (LLMs) with knowledge bases may improve medical domain-specific performance, practical methods are needed for local implementation of LLMs that address privacy concerns and enhance accessibility for health care professionals.</p><p><strong>Objective: </strong>To develop an accurate, cost-effective local implementation of an LLM to mitigate privacy concerns and support their practical deployment in health care settings.</p><p><strong>Design, setting, and participants: </strong>ChatZOC (Sun Yat-Sen University Zhongshan Ophthalmology Center), a retrieval-augmented LLM framework, was developed by enhancing a baseline LLM with a comprehensive ophthalmic dataset and evaluation framework (CODE), which includes over 30 000 pieces of ophthalmic knowledge. This LLM was benchmarked against 10 representative LLMs, including GPT-4 and GPT-3.5 Turbo (OpenAI), across 300 clinical questions in ophthalmology. The evaluation, involving a panel of medical experts and biomedical researchers, focused on accuracy, utility, and safety. A double-masked approach was used to try to minimize bias assessment across all models. The study used a comprehensive knowledge base derived from ophthalmic clinical practice, without directly involving clinical patients.</p><p><strong>Exposures: </strong>LLM response to clinical questions.</p><p><strong>Main outcomes and measures: </strong>Accuracy, utility, and safety of LLMs in responding to clinical questions.</p><p><strong>Results: </strong>The baseline model achieved a human ranking score of 0.48. The retrieval-augmented LLM had a score of 0.60, a difference of 0.12 (95% CI, 0.02-0.22; P = .02) from baseline and not different from GPT-4 with a score of 0.61 (difference = 0.01; 95% CI, -0.11 to 0.13; P = .89). For scientific consensus, the retrieval-augmented LLM was 84.0% compared with the baseline model of 46.5% (difference = 37.5%; 95% CI, 29.0%-46.0%; P < .001) and not different from GPT-4 with a value of 79.2% (difference = 4.8%; 95% CI, -0.3% to 10.0%; P = .06).</p><p><strong>Conclusions and relevance: </strong>Results of this quality improvement study suggest that the integration of high-quality knowledge bases improved the LLM's performance in medical domains. This study highlights the transformative potential of augmented LLMs in clinical practice by providing reliable, safe, and practical clinical information. Further research is needed to explore the broader application of such frameworks in the real world.</p>\",\"PeriodicalId\":14518,\"journal\":{\"name\":\"JAMA ophthalmology\",\"volume\":\" \",\"pages\":\"798-805\"},\"PeriodicalIF\":9.2000,\"publicationDate\":\"2024-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11258636/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMA ophthalmology\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1001/jamaophthalmol.2024.2513\",\"RegionNum\":1,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"OPHTHALMOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMA ophthalmology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1001/jamaophthalmol.2024.2513","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
Development and Evaluation of a Retrieval-Augmented Large Language Model Framework for Ophthalmology.
Importance: Although augmenting large language models (LLMs) with knowledge bases may improve medical domain-specific performance, practical methods are needed for local implementation of LLMs that address privacy concerns and enhance accessibility for health care professionals.
Objective: To develop an accurate, cost-effective local implementation of an LLM to mitigate privacy concerns and support their practical deployment in health care settings.
Design, setting, and participants: ChatZOC (Sun Yat-Sen University Zhongshan Ophthalmology Center), a retrieval-augmented LLM framework, was developed by enhancing a baseline LLM with a comprehensive ophthalmic dataset and evaluation framework (CODE), which includes over 30 000 pieces of ophthalmic knowledge. This LLM was benchmarked against 10 representative LLMs, including GPT-4 and GPT-3.5 Turbo (OpenAI), across 300 clinical questions in ophthalmology. The evaluation, involving a panel of medical experts and biomedical researchers, focused on accuracy, utility, and safety. A double-masked approach was used to try to minimize bias assessment across all models. The study used a comprehensive knowledge base derived from ophthalmic clinical practice, without directly involving clinical patients.
Exposures: LLM response to clinical questions.
Main outcomes and measures: Accuracy, utility, and safety of LLMs in responding to clinical questions.
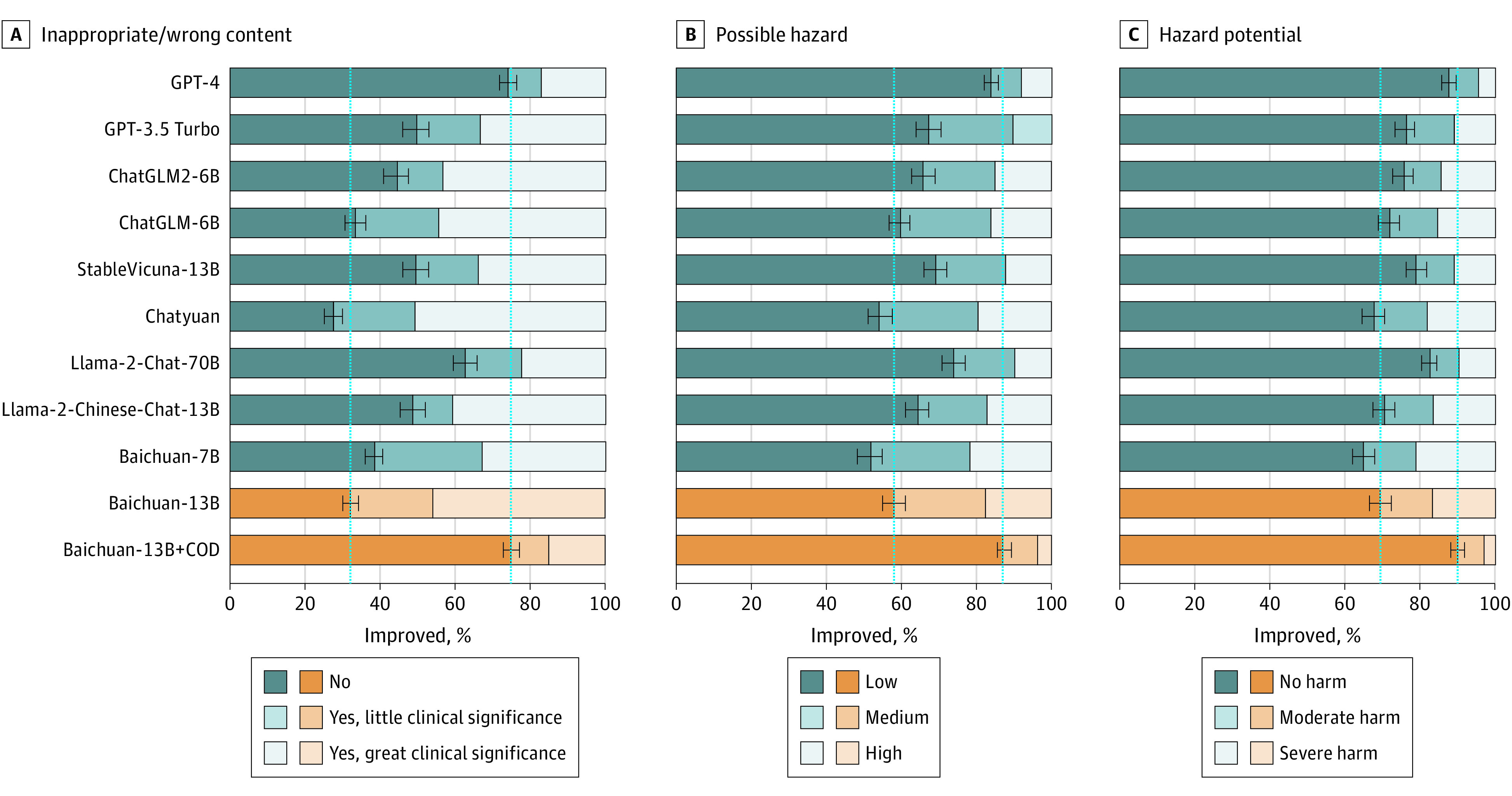
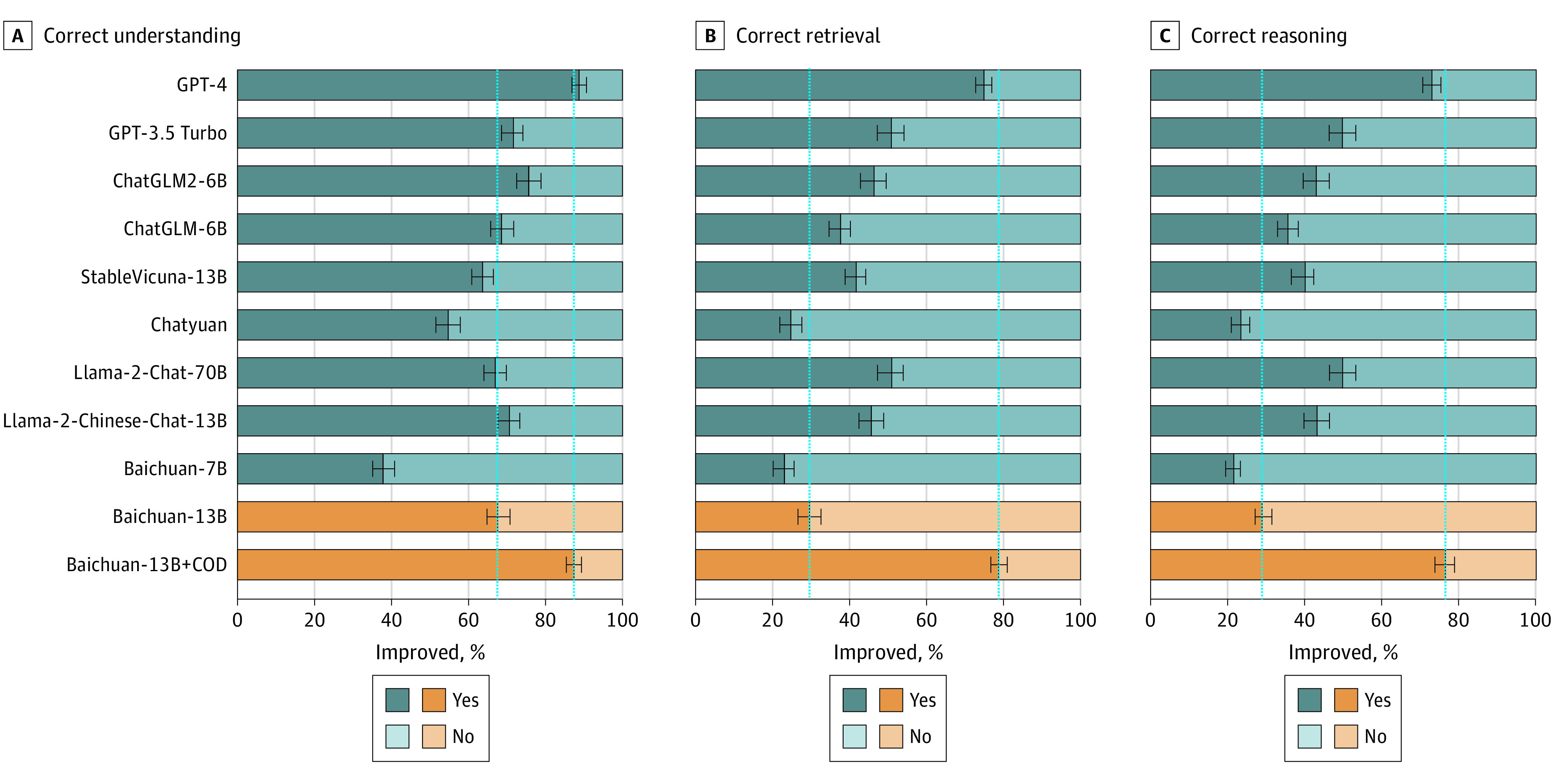
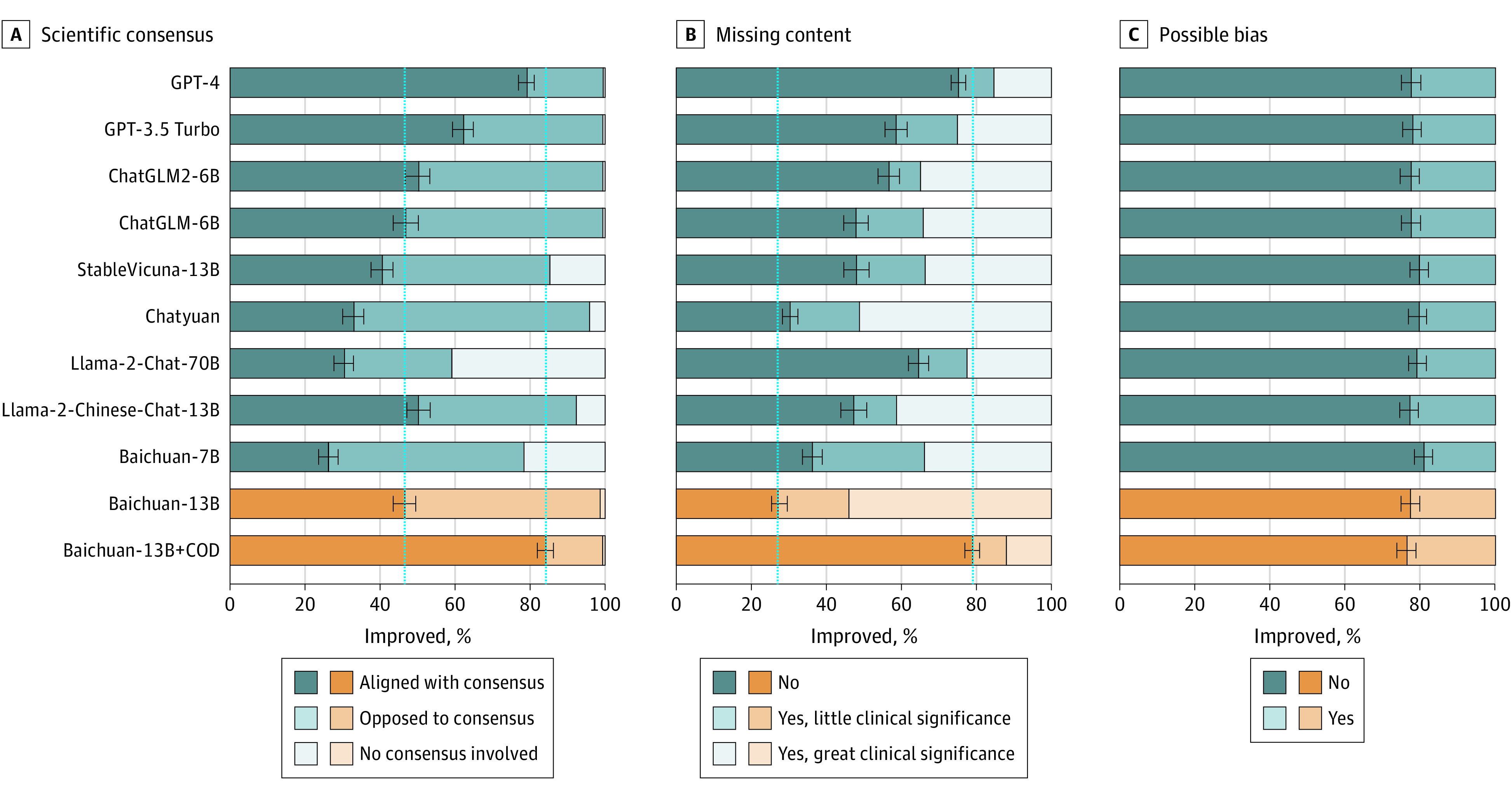
Results: The baseline model achieved a human ranking score of 0.48. The retrieval-augmented LLM had a score of 0.60, a difference of 0.12 (95% CI, 0.02-0.22; P = .02) from baseline and not different from GPT-4 with a score of 0.61 (difference = 0.01; 95% CI, -0.11 to 0.13; P = .89). For scientific consensus, the retrieval-augmented LLM was 84.0% compared with the baseline model of 46.5% (difference = 37.5%; 95% CI, 29.0%-46.0%; P < .001) and not different from GPT-4 with a value of 79.2% (difference = 4.8%; 95% CI, -0.3% to 10.0%; P = .06).
Conclusions and relevance: Results of this quality improvement study suggest that the integration of high-quality knowledge bases improved the LLM's performance in medical domains. This study highlights the transformative potential of augmented LLMs in clinical practice by providing reliable, safe, and practical clinical information. Further research is needed to explore the broader application of such frameworks in the real world.
期刊介绍:
JAMA Ophthalmology, with a rich history of continuous publication since 1869, stands as a distinguished international, peer-reviewed journal dedicated to ophthalmology and visual science. In 2019, the journal proudly commemorated 150 years of uninterrupted service to the field. As a member of the esteemed JAMA Network, a consortium renowned for its peer-reviewed general medical and specialty publications, JAMA Ophthalmology upholds the highest standards of excellence in disseminating cutting-edge research and insights. Join us in celebrating our legacy and advancing the frontiers of ophthalmology and visual science.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
