{"title":"LMNet:用于立体匹配的可学习多尺度成本量","authors":"Jiatao Liu , Yaping Zhang","doi":"10.1016/j.image.2024.117169","DOIUrl":null,"url":null,"abstract":"<div><p>Calculating disparities through stereo matching is an important step in a variety of machine vision tasks used for robotics and similar applications. The use of deep neural networks for stereo matching requires the construction of a matching cost volume. However, the occluded, non-textured, and reflective regions are ill-posed, which cannot be directly matched. In previous studies, a direct calculation has typically been used to measure matching costs for single-scale feature maps, which makes it difficult to predict disparity for ill-posed regions. Thus, we propose a learnable multi-scale matching cost calculation method (LMNet) to improve the accuracy of stereo matching. This learned matching cost can reasonably estimate the disparity of the regions that are conventionally difficult to match. Multi-level 3D dilation convolutions for multi-scale features are introduced during constructing cost volumes because the receptive field of the convolution kernels is limited. The experimental results show that the proposed method achieves significant improvement in ill-posed regions. Compared with the classical architecture GwcNet, End-Point-Error (EPE) of the proposed method on the Scene Flow dataset is reduced by 16.46%. The number of parameters and required calculations are also reduced by 8.71% and 20.05%, respectively. The proposed model code and pre-training parameters are available at: <span><span>https://github.com/jt-liu/LMNet</span><svg><path></path></svg></span>.</p></div>","PeriodicalId":49521,"journal":{"name":"Signal Processing-Image Communication","volume":"128 ","pages":"Article 117169"},"PeriodicalIF":2.7000,"publicationDate":"2024-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"LMNet: A learnable multi-scale cost volume for stereo matching\",\"authors\":\"Jiatao Liu , Yaping Zhang\",\"doi\":\"10.1016/j.image.2024.117169\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Calculating disparities through stereo matching is an important step in a variety of machine vision tasks used for robotics and similar applications. The use of deep neural networks for stereo matching requires the construction of a matching cost volume. However, the occluded, non-textured, and reflective regions are ill-posed, which cannot be directly matched. In previous studies, a direct calculation has typically been used to measure matching costs for single-scale feature maps, which makes it difficult to predict disparity for ill-posed regions. Thus, we propose a learnable multi-scale matching cost calculation method (LMNet) to improve the accuracy of stereo matching. This learned matching cost can reasonably estimate the disparity of the regions that are conventionally difficult to match. Multi-level 3D dilation convolutions for multi-scale features are introduced during constructing cost volumes because the receptive field of the convolution kernels is limited. The experimental results show that the proposed method achieves significant improvement in ill-posed regions. Compared with the classical architecture GwcNet, End-Point-Error (EPE) of the proposed method on the Scene Flow dataset is reduced by 16.46%. The number of parameters and required calculations are also reduced by 8.71% and 20.05%, respectively. The proposed model code and pre-training parameters are available at: <span><span>https://github.com/jt-liu/LMNet</span><svg><path></path></svg></span>.</p></div>\",\"PeriodicalId\":49521,\"journal\":{\"name\":\"Signal Processing-Image Communication\",\"volume\":\"128 \",\"pages\":\"Article 117169\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2024-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Signal Processing-Image Communication\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0923596524000705\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/7/11 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"ENGINEERING, ELECTRICAL & ELECTRONIC\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Signal Processing-Image Communication","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0923596524000705","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/7/11 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
LMNet: A learnable multi-scale cost volume for stereo matching
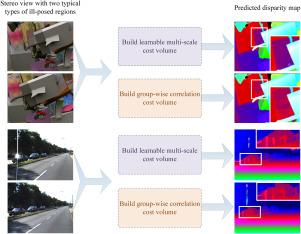
Calculating disparities through stereo matching is an important step in a variety of machine vision tasks used for robotics and similar applications. The use of deep neural networks for stereo matching requires the construction of a matching cost volume. However, the occluded, non-textured, and reflective regions are ill-posed, which cannot be directly matched. In previous studies, a direct calculation has typically been used to measure matching costs for single-scale feature maps, which makes it difficult to predict disparity for ill-posed regions. Thus, we propose a learnable multi-scale matching cost calculation method (LMNet) to improve the accuracy of stereo matching. This learned matching cost can reasonably estimate the disparity of the regions that are conventionally difficult to match. Multi-level 3D dilation convolutions for multi-scale features are introduced during constructing cost volumes because the receptive field of the convolution kernels is limited. The experimental results show that the proposed method achieves significant improvement in ill-posed regions. Compared with the classical architecture GwcNet, End-Point-Error (EPE) of the proposed method on the Scene Flow dataset is reduced by 16.46%. The number of parameters and required calculations are also reduced by 8.71% and 20.05%, respectively. The proposed model code and pre-training parameters are available at: https://github.com/jt-liu/LMNet.
期刊介绍:
Signal Processing: Image Communication is an international journal for the development of the theory and practice of image communication. Its primary objectives are the following:
To present a forum for the advancement of theory and practice of image communication.
To stimulate cross-fertilization between areas similar in nature which have traditionally been separated, for example, various aspects of visual communications and information systems.
To contribute to a rapid information exchange between the industrial and academic environments.
The editorial policy and the technical content of the journal are the responsibility of the Editor-in-Chief, the Area Editors and the Advisory Editors. The Journal is self-supporting from subscription income and contains a minimum amount of advertisements. Advertisements are subject to the prior approval of the Editor-in-Chief. The journal welcomes contributions from every country in the world.
Signal Processing: Image Communication publishes articles relating to aspects of the design, implementation and use of image communication systems. The journal features original research work, tutorial and review articles, and accounts of practical developments.
Subjects of interest include image/video coding, 3D video representations and compression, 3D graphics and animation compression, HDTV and 3DTV systems, video adaptation, video over IP, peer-to-peer video networking, interactive visual communication, multi-user video conferencing, wireless video broadcasting and communication, visual surveillance, 2D and 3D image/video quality measures, pre/post processing, video restoration and super-resolution, multi-camera video analysis, motion analysis, content-based image/video indexing and retrieval, face and gesture processing, video synthesis, 2D and 3D image/video acquisition and display technologies, architectures for image/video processing and communication.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
