{"title":"USteg-DSE:使用与挤压和激励网合并的 DenseNet 的通用定量隐写分析框架","authors":"Anuradha Singhal, Punam Bedi","doi":"10.1016/j.image.2024.117171","DOIUrl":null,"url":null,"abstract":"<div><p>Carrying concealed communication via media is termed as steganography and unraveling details of such covert transmission is known as steganalysis. Extracting details of hidden message like length, position, embedding algorithm etc. forms part of forensic steganalysis. Predicting length of payload in camouflaged interchange is termed as quantitative steganalysis and is an indispensable tool for forensic investigators. When payload length is estimated without any prior knowledge about cover media or used steganography algorithm, it is termed as universal quantitative steganalysis.</p><p>Most of existing frameworks on quantitative steganalysis available in literature, work for a specific embedding algorithm or are domain specific. In this paper we propose and present USteg-DSE, a deep learning framework for performing universal quantitative image steganalysis using DenseNet with Squeeze & Excitation module (SEM). In deep learning techniques, deeper networks easily capture complex statistical properties. But as depth increases, networks suffer from vanishing gradient problem. In classic architectures, all channels are equally weighted to produce feature maps. Presented USteg-DSE framework overcomes these problems by using DenseNet and SEM. In DenseNet, each layer is directly connected with every other layer. DenseNet makes information and gradient flow easier with fewer feature maps. SEM incorporates content aware mechanism to adaptively regulate weight for every feature map. Presented framework has been compared with existing state-of-the-art techniques for spatial domain as well as transform domain and show better results in terms of Mean Absolute Error (MAE) and Mean Square Error (MSE).</p></div>","PeriodicalId":49521,"journal":{"name":"Signal Processing-Image Communication","volume":"128 ","pages":"Article 117171"},"PeriodicalIF":2.1000,"publicationDate":"2024-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"USteg-DSE: Universal quantitative Steganalysis framework using Densenet merged with Squeeze & Excitation net\",\"authors\":\"Anuradha Singhal, Punam Bedi\",\"doi\":\"10.1016/j.image.2024.117171\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Carrying concealed communication via media is termed as steganography and unraveling details of such covert transmission is known as steganalysis. Extracting details of hidden message like length, position, embedding algorithm etc. forms part of forensic steganalysis. Predicting length of payload in camouflaged interchange is termed as quantitative steganalysis and is an indispensable tool for forensic investigators. When payload length is estimated without any prior knowledge about cover media or used steganography algorithm, it is termed as universal quantitative steganalysis.</p><p>Most of existing frameworks on quantitative steganalysis available in literature, work for a specific embedding algorithm or are domain specific. In this paper we propose and present USteg-DSE, a deep learning framework for performing universal quantitative image steganalysis using DenseNet with Squeeze & Excitation module (SEM). In deep learning techniques, deeper networks easily capture complex statistical properties. But as depth increases, networks suffer from vanishing gradient problem. In classic architectures, all channels are equally weighted to produce feature maps. Presented USteg-DSE framework overcomes these problems by using DenseNet and SEM. In DenseNet, each layer is directly connected with every other layer. DenseNet makes information and gradient flow easier with fewer feature maps. SEM incorporates content aware mechanism to adaptively regulate weight for every feature map. Presented framework has been compared with existing state-of-the-art techniques for spatial domain as well as transform domain and show better results in terms of Mean Absolute Error (MAE) and Mean Square Error (MSE).</p></div>\",\"PeriodicalId\":49521,\"journal\":{\"name\":\"Signal Processing-Image Communication\",\"volume\":\"128 \",\"pages\":\"Article 117171\"},\"PeriodicalIF\":2.1000,\"publicationDate\":\"2024-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Signal Processing-Image Communication\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0923596524000729\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/7/11 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"ENGINEERING, ELECTRICAL & ELECTRONIC\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Signal Processing-Image Communication","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0923596524000729","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/7/11 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
USteg-DSE: Universal quantitative Steganalysis framework using Densenet merged with Squeeze & Excitation net
Carrying concealed communication via media is termed as steganography and unraveling details of such covert transmission is known as steganalysis. Extracting details of hidden message like length, position, embedding algorithm etc. forms part of forensic steganalysis. Predicting length of payload in camouflaged interchange is termed as quantitative steganalysis and is an indispensable tool for forensic investigators. When payload length is estimated without any prior knowledge about cover media or used steganography algorithm, it is termed as universal quantitative steganalysis.
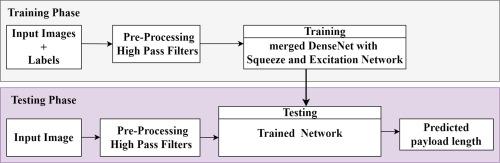
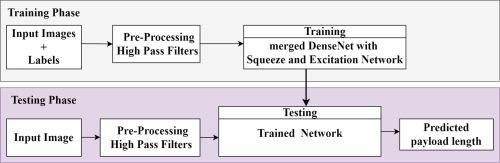
Most of existing frameworks on quantitative steganalysis available in literature, work for a specific embedding algorithm or are domain specific. In this paper we propose and present USteg-DSE, a deep learning framework for performing universal quantitative image steganalysis using DenseNet with Squeeze & Excitation module (SEM). In deep learning techniques, deeper networks easily capture complex statistical properties. But as depth increases, networks suffer from vanishing gradient problem. In classic architectures, all channels are equally weighted to produce feature maps. Presented USteg-DSE framework overcomes these problems by using DenseNet and SEM. In DenseNet, each layer is directly connected with every other layer. DenseNet makes information and gradient flow easier with fewer feature maps. SEM incorporates content aware mechanism to adaptively regulate weight for every feature map. Presented framework has been compared with existing state-of-the-art techniques for spatial domain as well as transform domain and show better results in terms of Mean Absolute Error (MAE) and Mean Square Error (MSE).
期刊介绍:
Signal Processing: Image Communication is an international journal for the development of the theory and practice of image communication. Its primary objectives are the following:
To present a forum for the advancement of theory and practice of image communication.
To stimulate cross-fertilization between areas similar in nature which have traditionally been separated, for example, various aspects of visual communications and information systems.
To contribute to a rapid information exchange between the industrial and academic environments.
The editorial policy and the technical content of the journal are the responsibility of the Editor-in-Chief, the Area Editors and the Advisory Editors. The Journal is self-supporting from subscription income and contains a minimum amount of advertisements. Advertisements are subject to the prior approval of the Editor-in-Chief. The journal welcomes contributions from every country in the world.
Signal Processing: Image Communication publishes articles relating to aspects of the design, implementation and use of image communication systems. The journal features original research work, tutorial and review articles, and accounts of practical developments.
Subjects of interest include image/video coding, 3D video representations and compression, 3D graphics and animation compression, HDTV and 3DTV systems, video adaptation, video over IP, peer-to-peer video networking, interactive visual communication, multi-user video conferencing, wireless video broadcasting and communication, visual surveillance, 2D and 3D image/video quality measures, pre/post processing, video restoration and super-resolution, multi-camera video analysis, motion analysis, content-based image/video indexing and retrieval, face and gesture processing, video synthesis, 2D and 3D image/video acquisition and display technologies, architectures for image/video processing and communication.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
