{"title":"通过引导式语言图像预训练(BioMedBLIP)提高多模态医疗任务的准确性:性能评估研究。","authors":"Usman Naseem, Surendrabikram Thapa, Anum Masood","doi":"10.2196/56627","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Medical image analysis, particularly in the context of visual question answering (VQA) and image captioning, is crucial for accurate diagnosis and educational purposes.</p><p><strong>Objective: </strong>Our study aims to introduce BioMedBLIP models, fine-tuned for VQA tasks using specialized medical data sets such as Radiology Objects in Context and Medical Information Mart for Intensive Care-Chest X-ray, and evaluate their performance in comparison to the state of the art (SOTA) original Bootstrapping Language-Image Pretraining (BLIP) model.</p><p><strong>Methods: </strong>We present 9 versions of BioMedBLIP across 3 downstream tasks in various data sets. The models are trained on a varying number of epochs. The findings indicate the strong overall performance of our models. We proposed BioMedBLIP for the VQA generation model, VQA classification model, and BioMedBLIP image caption model. We conducted pretraining in BLIP using medical data sets, producing an adapted BLIP model tailored for medical applications.</p><p><strong>Results: </strong>In VQA generation tasks, BioMedBLIP models outperformed the SOTA on the Semantically-Labeled Knowledge-Enhanced (SLAKE) data set, VQA in Radiology (VQA-RAD), and Image Cross-Language Evaluation Forum data sets. In VQA classification, our models consistently surpassed the SOTA on the SLAKE data set. Our models also showed competitive performance on the VQA-RAD and PathVQA data sets. Similarly, in image captioning tasks, our model beat the SOTA, suggesting the importance of pretraining with medical data sets. Overall, in 20 different data sets and task combinations, our BioMedBLIP excelled in 15 (75%) out of 20 tasks. BioMedBLIP represents a new SOTA in 15 (75%) out of 20 tasks, and our responses were rated higher in all 20 tasks (P<.005) in comparison to SOTA models.</p><p><strong>Conclusions: </strong>Our BioMedBLIP models show promising performance and suggest that incorporating medical knowledge through pretraining with domain-specific medical data sets helps models achieve higher performance. Our models thus demonstrate their potential to advance medical image analysis, impacting diagnosis, medical education, and research. However, data quality, task-specific variability, computational resources, and ethical considerations should be carefully addressed. In conclusion, our models represent a contribution toward the synergy of artificial intelligence and medicine. We have made BioMedBLIP freely available, which will help in further advancing research in multimodal medical tasks.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"12 ","pages":"e56627"},"PeriodicalIF":3.8000,"publicationDate":"2024-08-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11333867/pdf/","citationCount":"0","resultStr":"{\"title\":\"Advancing Accuracy in Multimodal Medical Tasks Through Bootstrapped Language-Image Pretraining (BioMedBLIP): Performance Evaluation Study.\",\"authors\":\"Usman Naseem, Surendrabikram Thapa, Anum Masood\",\"doi\":\"10.2196/56627\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Medical image analysis, particularly in the context of visual question answering (VQA) and image captioning, is crucial for accurate diagnosis and educational purposes.</p><p><strong>Objective: </strong>Our study aims to introduce BioMedBLIP models, fine-tuned for VQA tasks using specialized medical data sets such as Radiology Objects in Context and Medical Information Mart for Intensive Care-Chest X-ray, and evaluate their performance in comparison to the state of the art (SOTA) original Bootstrapping Language-Image Pretraining (BLIP) model.</p><p><strong>Methods: </strong>We present 9 versions of BioMedBLIP across 3 downstream tasks in various data sets. The models are trained on a varying number of epochs. The findings indicate the strong overall performance of our models. We proposed BioMedBLIP for the VQA generation model, VQA classification model, and BioMedBLIP image caption model. We conducted pretraining in BLIP using medical data sets, producing an adapted BLIP model tailored for medical applications.</p><p><strong>Results: </strong>In VQA generation tasks, BioMedBLIP models outperformed the SOTA on the Semantically-Labeled Knowledge-Enhanced (SLAKE) data set, VQA in Radiology (VQA-RAD), and Image Cross-Language Evaluation Forum data sets. In VQA classification, our models consistently surpassed the SOTA on the SLAKE data set. Our models also showed competitive performance on the VQA-RAD and PathVQA data sets. Similarly, in image captioning tasks, our model beat the SOTA, suggesting the importance of pretraining with medical data sets. Overall, in 20 different data sets and task combinations, our BioMedBLIP excelled in 15 (75%) out of 20 tasks. BioMedBLIP represents a new SOTA in 15 (75%) out of 20 tasks, and our responses were rated higher in all 20 tasks (P<.005) in comparison to SOTA models.</p><p><strong>Conclusions: </strong>Our BioMedBLIP models show promising performance and suggest that incorporating medical knowledge through pretraining with domain-specific medical data sets helps models achieve higher performance. Our models thus demonstrate their potential to advance medical image analysis, impacting diagnosis, medical education, and research. However, data quality, task-specific variability, computational resources, and ethical considerations should be carefully addressed. In conclusion, our models represent a contribution toward the synergy of artificial intelligence and medicine. We have made BioMedBLIP freely available, which will help in further advancing research in multimodal medical tasks.</p>\",\"PeriodicalId\":56334,\"journal\":{\"name\":\"JMIR Medical Informatics\",\"volume\":\"12 \",\"pages\":\"e56627\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2024-08-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11333867/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Medical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.2196/56627\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/56627","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
Advancing Accuracy in Multimodal Medical Tasks Through Bootstrapped Language-Image Pretraining (BioMedBLIP): Performance Evaluation Study.
Background: Medical image analysis, particularly in the context of visual question answering (VQA) and image captioning, is crucial for accurate diagnosis and educational purposes.
Objective: Our study aims to introduce BioMedBLIP models, fine-tuned for VQA tasks using specialized medical data sets such as Radiology Objects in Context and Medical Information Mart for Intensive Care-Chest X-ray, and evaluate their performance in comparison to the state of the art (SOTA) original Bootstrapping Language-Image Pretraining (BLIP) model.
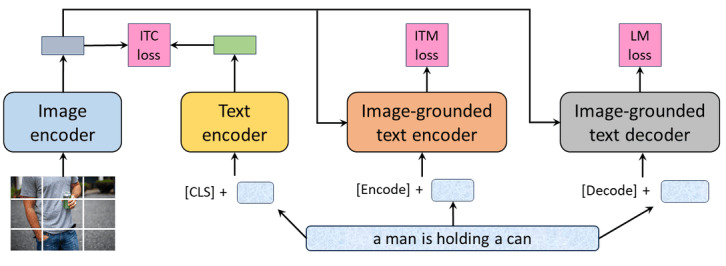
Methods: We present 9 versions of BioMedBLIP across 3 downstream tasks in various data sets. The models are trained on a varying number of epochs. The findings indicate the strong overall performance of our models. We proposed BioMedBLIP for the VQA generation model, VQA classification model, and BioMedBLIP image caption model. We conducted pretraining in BLIP using medical data sets, producing an adapted BLIP model tailored for medical applications.
Results: In VQA generation tasks, BioMedBLIP models outperformed the SOTA on the Semantically-Labeled Knowledge-Enhanced (SLAKE) data set, VQA in Radiology (VQA-RAD), and Image Cross-Language Evaluation Forum data sets. In VQA classification, our models consistently surpassed the SOTA on the SLAKE data set. Our models also showed competitive performance on the VQA-RAD and PathVQA data sets. Similarly, in image captioning tasks, our model beat the SOTA, suggesting the importance of pretraining with medical data sets. Overall, in 20 different data sets and task combinations, our BioMedBLIP excelled in 15 (75%) out of 20 tasks. BioMedBLIP represents a new SOTA in 15 (75%) out of 20 tasks, and our responses were rated higher in all 20 tasks (P<.005) in comparison to SOTA models.
Conclusions: Our BioMedBLIP models show promising performance and suggest that incorporating medical knowledge through pretraining with domain-specific medical data sets helps models achieve higher performance. Our models thus demonstrate their potential to advance medical image analysis, impacting diagnosis, medical education, and research. However, data quality, task-specific variability, computational resources, and ethical considerations should be carefully addressed. In conclusion, our models represent a contribution toward the synergy of artificial intelligence and medicine. We have made BioMedBLIP freely available, which will help in further advancing research in multimodal medical tasks.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
