Kaan Y Balta, Arshia P Javidan, Eric Walser, Robert Arntfield, Ross Prager
{"title":"评估重症监护建议中 ChatGPT 的适当性、一致性和可读性。","authors":"Kaan Y Balta, Arshia P Javidan, Eric Walser, Robert Arntfield, Ross Prager","doi":"10.1177/08850666241267871","DOIUrl":null,"url":null,"abstract":"<p><p><b>Background:</b> We assessed 2 versions of the large language model (LLM) ChatGPT-versions 3.5 and 4.0-in generating appropriate, consistent, and readable recommendations on core critical care topics. <b>Research Question:</b> How do successive large language models compare in terms of generating appropriate, consistent, and readable recommendations on core critical care topics? <b>Design and Methods:</b> A set of 50 LLM-generated responses to clinical questions were evaluated by 2 independent intensivists based on a 5-point Likert scale for appropriateness, consistency, and readability. <b>Results:</b> ChatGPT 4.0 showed significantly higher median appropriateness scores compared to ChatGPT 3.5 (4.0 vs 3.0, <i>P</i> < .001). However, there was no significant difference in consistency between the 2 versions (40% vs 28%, <i>P</i> = 0.291). Readability, assessed by the Flesch-Kincaid Grade Level, was also not significantly different between the 2 models (14.3 vs 14.4, <i>P</i> = 0.93). <b>Interpretation:</b> Both models produced \"hallucinations\"-misinformation delivered with high confidence-which highlights the risk of relying on these tools without domain expertise. Despite potential for clinical application, both models lacked consistency producing different results when asked the same question multiple times. The study underscores the need for clinicians to understand the strengths and limitations of LLMs for safe and effective implementation in critical care settings. <b>Registration:</b> https://osf.io/8chj7/.</p>","PeriodicalId":16307,"journal":{"name":"Journal of Intensive Care Medicine","volume":" ","pages":"184-190"},"PeriodicalIF":2.1000,"publicationDate":"2025-02-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11639400/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluating the Appropriateness, Consistency, and Readability of ChatGPT in Critical Care Recommendations.\",\"authors\":\"Kaan Y Balta, Arshia P Javidan, Eric Walser, Robert Arntfield, Ross Prager\",\"doi\":\"10.1177/08850666241267871\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Background:</b> We assessed 2 versions of the large language model (LLM) ChatGPT-versions 3.5 and 4.0-in generating appropriate, consistent, and readable recommendations on core critical care topics. <b>Research Question:</b> How do successive large language models compare in terms of generating appropriate, consistent, and readable recommendations on core critical care topics? <b>Design and Methods:</b> A set of 50 LLM-generated responses to clinical questions were evaluated by 2 independent intensivists based on a 5-point Likert scale for appropriateness, consistency, and readability. <b>Results:</b> ChatGPT 4.0 showed significantly higher median appropriateness scores compared to ChatGPT 3.5 (4.0 vs 3.0, <i>P</i> < .001). However, there was no significant difference in consistency between the 2 versions (40% vs 28%, <i>P</i> = 0.291). Readability, assessed by the Flesch-Kincaid Grade Level, was also not significantly different between the 2 models (14.3 vs 14.4, <i>P</i> = 0.93). <b>Interpretation:</b> Both models produced \\\"hallucinations\\\"-misinformation delivered with high confidence-which highlights the risk of relying on these tools without domain expertise. Despite potential for clinical application, both models lacked consistency producing different results when asked the same question multiple times. The study underscores the need for clinicians to understand the strengths and limitations of LLMs for safe and effective implementation in critical care settings. <b>Registration:</b> https://osf.io/8chj7/.</p>\",\"PeriodicalId\":16307,\"journal\":{\"name\":\"Journal of Intensive Care Medicine\",\"volume\":\" \",\"pages\":\"184-190\"},\"PeriodicalIF\":2.1000,\"publicationDate\":\"2025-02-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11639400/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Intensive Care Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1177/08850666241267871\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/8/8 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"CRITICAL CARE MEDICINE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Intensive Care Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1177/08850666241267871","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/8 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"CRITICAL CARE MEDICINE","Score":null,"Total":0}
引用次数: 0
摘要
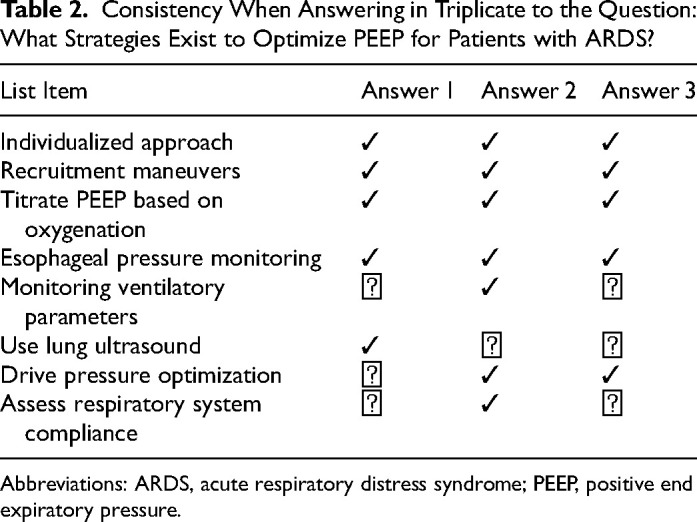
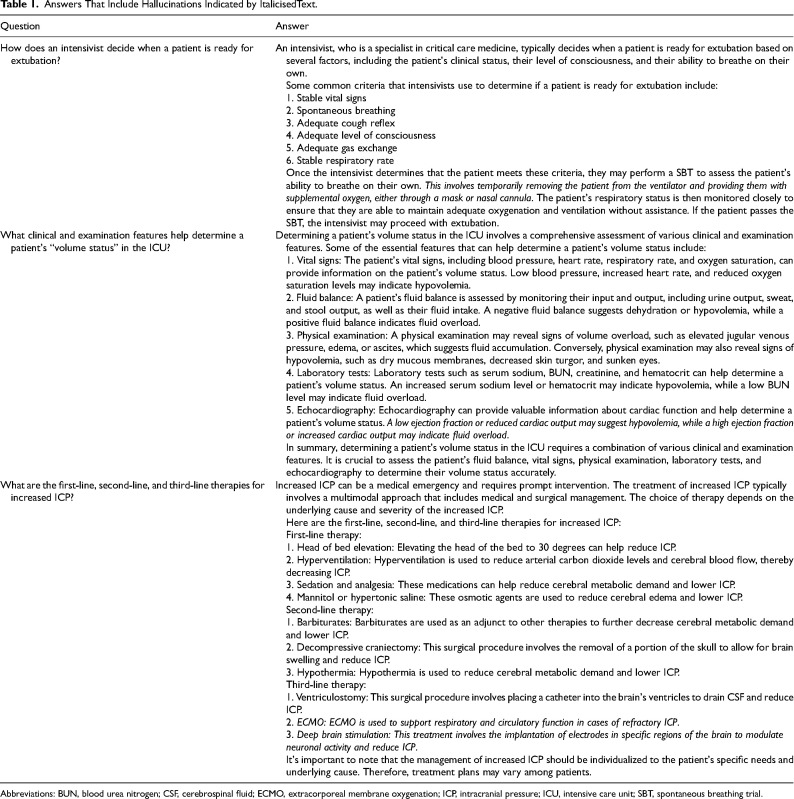
背景:我们评估了两个版本的大型语言模型(LLM)ChatGPT--3.5 版和 4.0 版--在生成有关核心重症监护主题的适当、一致且可读的建议方面的情况。研究问题:在就核心危重症护理主题生成适当、一致且可读的建议方面,相继出现的大型语言模型有何不同?设计与方法:由两名独立的重症医学专家根据 5 分制李克特量表对 50 个 LLM 生成的临床问题回复进行评估,以确定其适当性、一致性和可读性。结果显示与 ChatGPT 3.5 相比,ChatGPT 4.0 的适当性得分中位数明显更高(4.0 vs 3.0,P P = 0.291)。通过 Flesch-Kincaid 分级评估的可读性在两个模型之间也没有明显差异(14.3 vs 14.4,P = 0.93)。解释:这两个模型都产生了 "幻觉"--以高置信度传递的错误信息--这凸显了在没有专业领域知识的情况下依赖这些工具的风险。尽管两种模型都有临床应用的潜力,但它们缺乏一致性,在多次询问同一问题时会产生不同的结果。这项研究强调,临床医生需要了解 LLM 的优势和局限性,以便在重症监护环境中安全有效地实施 LLM。注册:https://osf.io/8chj7/。
Evaluating the Appropriateness, Consistency, and Readability of ChatGPT in Critical Care Recommendations.
Background: We assessed 2 versions of the large language model (LLM) ChatGPT-versions 3.5 and 4.0-in generating appropriate, consistent, and readable recommendations on core critical care topics. Research Question: How do successive large language models compare in terms of generating appropriate, consistent, and readable recommendations on core critical care topics? Design and Methods: A set of 50 LLM-generated responses to clinical questions were evaluated by 2 independent intensivists based on a 5-point Likert scale for appropriateness, consistency, and readability. Results: ChatGPT 4.0 showed significantly higher median appropriateness scores compared to ChatGPT 3.5 (4.0 vs 3.0, P < .001). However, there was no significant difference in consistency between the 2 versions (40% vs 28%, P = 0.291). Readability, assessed by the Flesch-Kincaid Grade Level, was also not significantly different between the 2 models (14.3 vs 14.4, P = 0.93). Interpretation: Both models produced "hallucinations"-misinformation delivered with high confidence-which highlights the risk of relying on these tools without domain expertise. Despite potential for clinical application, both models lacked consistency producing different results when asked the same question multiple times. The study underscores the need for clinicians to understand the strengths and limitations of LLMs for safe and effective implementation in critical care settings. Registration: https://osf.io/8chj7/.
期刊介绍:
Journal of Intensive Care Medicine (JIC) is a peer-reviewed bi-monthly journal offering medical and surgical clinicians in adult and pediatric intensive care state-of-the-art, broad-based analytic reviews and updates, original articles, reports of large clinical series, techniques and procedures, topic-specific electronic resources, book reviews, and editorials on all aspects of intensive/critical/coronary care.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
