{"title":"在数字 PET/CT 中引入基于深度学习的 [18F]FDG PET 去噪对 EORTC 和 PERCIST 治疗反应评估的影响。","authors":"Kathleen Weyts, Justine Lequesne, Alison Johnson, Hubert Curcio, Aurélie Parzy, Elodie Coquan, Charline Lasnon","doi":"10.1186/s13550-024-01128-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>[<sup>18</sup>F]FDG PET denoising by SubtlePET™ using deep learning artificial intelligence (AI) was previously found to induce slight modifications in lesion and reference organs' quantification and in lesion detection. As a next step, we aimed to evaluate its clinical impact on [<sup>18</sup>F]FDG PET solid tumour treatment response assessments, while comparing \"standard PET\" to \"AI denoised half-duration PET\" (\"AI PET\") during follow-up.</p><p><strong>Results: </strong>110 patients referred for baseline and follow-up standard digital [<sup>18</sup>F]FDG PET/CT were prospectively included. \"Standard\" EORTC and, if applicable, PERCIST response classifications by 2 readers between baseline standard PET1 and follow-up standard PET2 as a \"gold standard\" were compared to \"mixed\" classifications between standard PET1 and AI PET2 (group 1; n = 64), or between AI PET1 and standard PET2 (group 2; n = 46). Separate classifications were established using either standardized uptake values from ultra-high definition PET with or without AI denoising (simplified to \"UHD\") or EANM research limited v2 (EARL2)-compliant values (by Gaussian filtering in standard PET and using the same filter in AI PET). Overall, pooling both study groups, in 11/110 (10%) patients at least one EORTC<sub>UHD or EARL2</sub> or PERCIST<sub>UHD or EARL2</sub> mixed vs. standard classification was discordant, with 369/397 (93%) concordant classifications, unweighted Cohen's kappa = 0.86 (95% CI: 0.78-0.94). These modified mixed vs. standard classifications could have impacted management in 2% of patients.</p><p><strong>Conclusions: </strong>Although comparing similar PET images is preferable for therapy response assessment, the comparison between a standard [<sup>18</sup>F]FDG PET and an AI denoised half-duration PET is feasible and seems clinically satisfactory.</p>","PeriodicalId":11611,"journal":{"name":"EJNMMI Research","volume":"14 1","pages":"72"},"PeriodicalIF":3.1000,"publicationDate":"2024-08-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11316728/pdf/","citationCount":"0","resultStr":"{\"title\":\"The impact of introducing deep learning based [<sup>18</sup>F]FDG PET denoising on EORTC and PERCIST therapeutic response assessments in digital PET/CT.\",\"authors\":\"Kathleen Weyts, Justine Lequesne, Alison Johnson, Hubert Curcio, Aurélie Parzy, Elodie Coquan, Charline Lasnon\",\"doi\":\"10.1186/s13550-024-01128-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>[<sup>18</sup>F]FDG PET denoising by SubtlePET™ using deep learning artificial intelligence (AI) was previously found to induce slight modifications in lesion and reference organs' quantification and in lesion detection. As a next step, we aimed to evaluate its clinical impact on [<sup>18</sup>F]FDG PET solid tumour treatment response assessments, while comparing \\\"standard PET\\\" to \\\"AI denoised half-duration PET\\\" (\\\"AI PET\\\") during follow-up.</p><p><strong>Results: </strong>110 patients referred for baseline and follow-up standard digital [<sup>18</sup>F]FDG PET/CT were prospectively included. \\\"Standard\\\" EORTC and, if applicable, PERCIST response classifications by 2 readers between baseline standard PET1 and follow-up standard PET2 as a \\\"gold standard\\\" were compared to \\\"mixed\\\" classifications between standard PET1 and AI PET2 (group 1; n = 64), or between AI PET1 and standard PET2 (group 2; n = 46). Separate classifications were established using either standardized uptake values from ultra-high definition PET with or without AI denoising (simplified to \\\"UHD\\\") or EANM research limited v2 (EARL2)-compliant values (by Gaussian filtering in standard PET and using the same filter in AI PET). Overall, pooling both study groups, in 11/110 (10%) patients at least one EORTC<sub>UHD or EARL2</sub> or PERCIST<sub>UHD or EARL2</sub> mixed vs. standard classification was discordant, with 369/397 (93%) concordant classifications, unweighted Cohen's kappa = 0.86 (95% CI: 0.78-0.94). These modified mixed vs. standard classifications could have impacted management in 2% of patients.</p><p><strong>Conclusions: </strong>Although comparing similar PET images is preferable for therapy response assessment, the comparison between a standard [<sup>18</sup>F]FDG PET and an AI denoised half-duration PET is feasible and seems clinically satisfactory.</p>\",\"PeriodicalId\":11611,\"journal\":{\"name\":\"EJNMMI Research\",\"volume\":\"14 1\",\"pages\":\"72\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-08-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11316728/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"EJNMMI Research\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1186/s13550-024-01128-z\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"EJNMMI Research","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s13550-024-01128-z","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
引用次数: 0
摘要
背景:以前曾发现,SubtlePET™ 使用深度学习人工智能(AI)对[18F]FDG PET 去噪会导致病变和参照器官的量化以及病变检测发生轻微变化。下一步,我们旨在评估其对[18F]FDG PET 实体瘤治疗反应评估的临床影响,同时在随访期间比较 "标准 PET "和 "AI 去噪半持续时间 PET"("AI PET"):前瞻性纳入了110名接受基线和后续标准数字[18F]FDG PET/CT检查的患者。作为 "金标准",由两名阅读者对基线标准 PET1 和随访标准 PET2 进行 "标准 "EORTC 反应分类(如适用,PERCIST 反应分类),并与标准 PET1 和 AI PET2 之间的 "混合 "分类(第 1 组;n = 64)或 AI PET1 和标准 PET2 之间的 "混合 "分类(第 2 组;n = 46)进行比较。单独的分类是使用有或没有人工智能去噪的超高清 PET 的标准化摄取值(简化为 "UHD")或符合 EANM research limited v2 (EARL2) 标准的摄取值(在标准 PET 中使用高斯滤波,在人工智能 PET 中使用相同的滤波)确定的。总体而言,汇总两个研究组,11/110(10%)例患者中至少有一个 EORTCUHD 或 EARL2 或 PERCISTUHD 或 EARL2 混合与标准分类不一致,369/397(93%)例患者分类一致,未加权科恩卡帕 = 0.86(95% CI:0.78-0.94)。这些修改后的混合分类与标准分类可能会影响2%患者的治疗:尽管比较相似的正电子发射计算机断层图像更有利于治疗反应评估,但标准[18F]FDG正电子发射计算机断层图像与人工智能去噪半长时正电子发射计算机断层图像之间的比较是可行的,而且在临床上似乎令人满意。
The impact of introducing deep learning based [18F]FDG PET denoising on EORTC and PERCIST therapeutic response assessments in digital PET/CT.
Background: [18F]FDG PET denoising by SubtlePET™ using deep learning artificial intelligence (AI) was previously found to induce slight modifications in lesion and reference organs' quantification and in lesion detection. As a next step, we aimed to evaluate its clinical impact on [18F]FDG PET solid tumour treatment response assessments, while comparing "standard PET" to "AI denoised half-duration PET" ("AI PET") during follow-up.
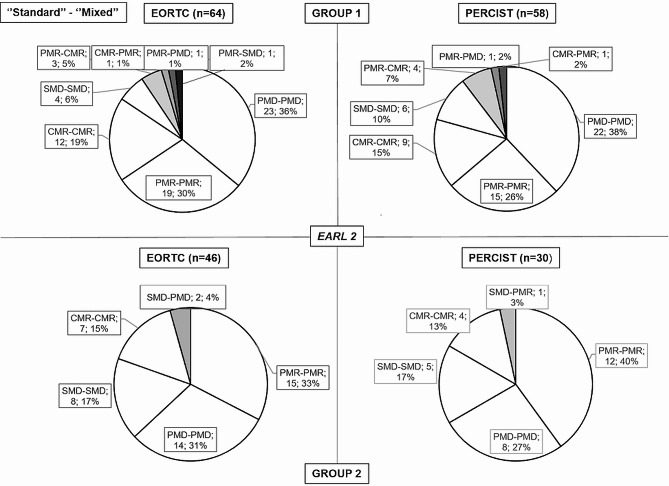
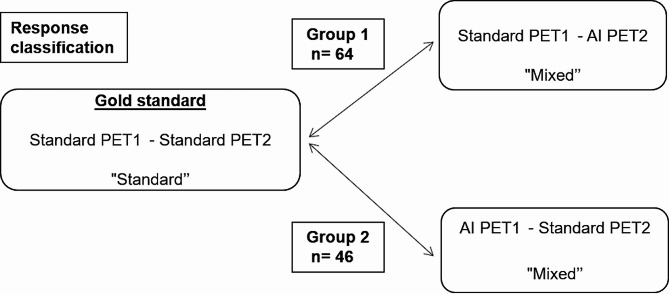
Results: 110 patients referred for baseline and follow-up standard digital [18F]FDG PET/CT were prospectively included. "Standard" EORTC and, if applicable, PERCIST response classifications by 2 readers between baseline standard PET1 and follow-up standard PET2 as a "gold standard" were compared to "mixed" classifications between standard PET1 and AI PET2 (group 1; n = 64), or between AI PET1 and standard PET2 (group 2; n = 46). Separate classifications were established using either standardized uptake values from ultra-high definition PET with or without AI denoising (simplified to "UHD") or EANM research limited v2 (EARL2)-compliant values (by Gaussian filtering in standard PET and using the same filter in AI PET). Overall, pooling both study groups, in 11/110 (10%) patients at least one EORTCUHD or EARL2 or PERCISTUHD or EARL2 mixed vs. standard classification was discordant, with 369/397 (93%) concordant classifications, unweighted Cohen's kappa = 0.86 (95% CI: 0.78-0.94). These modified mixed vs. standard classifications could have impacted management in 2% of patients.
Conclusions: Although comparing similar PET images is preferable for therapy response assessment, the comparison between a standard [18F]FDG PET and an AI denoised half-duration PET is feasible and seems clinically satisfactory.
EJNMMI ResearchRADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING&nb-
CiteScore
5.90
自引率
3.10%
发文量
72
审稿时长
13 weeks
期刊介绍:
EJNMMI Research publishes new basic, translational and clinical research in the field of nuclear medicine and molecular imaging. Regular features include original research articles, rapid communication of preliminary data on innovative research, interesting case reports, editorials, and letters to the editor. Educational articles on basic sciences, fundamental aspects and controversy related to pre-clinical and clinical research or ethical aspects of research are also welcome. Timely reviews provide updates on current applications, issues in imaging research and translational aspects of nuclear medicine and molecular imaging technologies.
The main emphasis is placed on the development of targeted imaging with radiopharmaceuticals within the broader context of molecular probes to enhance understanding and characterisation of the complex biological processes underlying disease and to develop, test and guide new treatment modalities, including radionuclide therapy.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
