Daniel Mansilla, Jesper Tveit, Harald Aurlien, Tamir Avigdor, Victoria Ros-Castello, Alyssa Ho, Chifaou Abdallah, Jean Gotman, Sándor Beniczky, Birgit Frauscher
{"title":"人工智能脑电图解读的通用性:外部验证研究。","authors":"Daniel Mansilla, Jesper Tveit, Harald Aurlien, Tamir Avigdor, Victoria Ros-Castello, Alyssa Ho, Chifaou Abdallah, Jean Gotman, Sándor Beniczky, Birgit Frauscher","doi":"10.1111/epi.18082","DOIUrl":null,"url":null,"abstract":"<div>\n \n \n <section>\n \n <h3> Objective</h3>\n \n <p>The automated interpretation of clinical electroencephalograms (EEGs) using artificial intelligence (AI) holds the potential to bridge the treatment gap in resource-limited settings and reduce the workload at specialized centers. However, to facilitate broad clinical implementation, it is essential to establish generalizability across diverse patient populations and equipment. We assessed whether SCORE-AI demonstrates diagnostic accuracy comparable to that of experts when applied to a geographically different patient population, recorded with distinct EEG equipment and technical settings.</p>\n </section>\n \n <section>\n \n <h3> Methods</h3>\n \n <p>We assessed the diagnostic accuracy of a “fixed-and-frozen” AI model, using an independent dataset and external gold standard, and benchmarked it against three experts blinded to all other data. The dataset comprised 50% normal and 50% abnormal routine EEGs, equally distributed among the four major classes of EEG abnormalities (focal epileptiform, generalized epileptiform, focal nonepileptiform, and diffuse nonepileptiform). To assess diagnostic accuracy, we computed sensitivity, specificity, and accuracy of the AI model and the experts against the external gold standard.</p>\n </section>\n \n <section>\n \n <h3> Results</h3>\n \n <p>We analyzed EEGs from 104 patients (64 females, median age = 38.6 [range = 16–91] years). SCORE-AI performed equally well compared to the experts, with an overall accuracy of 92% (95% confidence interval [CI] = 90%–94%) versus 94% (95% CI = 92%–96%). There was no significant difference between SCORE-AI and the experts for any metric or category. SCORE-AI performed well independently of the vigilance state (false classification during awake: 5/41 [12.2%], false classification during sleep: 2/11 [18.2%]; <i>p</i> = .63) and normal variants (false classification in presence of normal variants: 4/14 [28.6%], false classification in absence of normal variants: 3/38 [7.9%]; <i>p</i> = .07).</p>\n </section>\n \n <section>\n \n <h3> Significance</h3>\n \n <p>SCORE-AI achieved diagnostic performance equal to human experts in an EEG dataset independent of the development dataset, in a geographically distinct patient population, recorded with different equipment and technical settings than the development dataset.</p>\n </section>\n </div>","PeriodicalId":11768,"journal":{"name":"Epilepsia","volume":"65 10","pages":"3028-3037"},"PeriodicalIF":5.6000,"publicationDate":"2024-08-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/epi.18082","citationCount":"0","resultStr":"{\"title\":\"Generalizability of electroencephalographic interpretation using artificial intelligence: An external validation study\",\"authors\":\"Daniel Mansilla, Jesper Tveit, Harald Aurlien, Tamir Avigdor, Victoria Ros-Castello, Alyssa Ho, Chifaou Abdallah, Jean Gotman, Sándor Beniczky, Birgit Frauscher\",\"doi\":\"10.1111/epi.18082\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n \\n \\n <section>\\n \\n <h3> Objective</h3>\\n \\n <p>The automated interpretation of clinical electroencephalograms (EEGs) using artificial intelligence (AI) holds the potential to bridge the treatment gap in resource-limited settings and reduce the workload at specialized centers. However, to facilitate broad clinical implementation, it is essential to establish generalizability across diverse patient populations and equipment. We assessed whether SCORE-AI demonstrates diagnostic accuracy comparable to that of experts when applied to a geographically different patient population, recorded with distinct EEG equipment and technical settings.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Methods</h3>\\n \\n <p>We assessed the diagnostic accuracy of a “fixed-and-frozen” AI model, using an independent dataset and external gold standard, and benchmarked it against three experts blinded to all other data. The dataset comprised 50% normal and 50% abnormal routine EEGs, equally distributed among the four major classes of EEG abnormalities (focal epileptiform, generalized epileptiform, focal nonepileptiform, and diffuse nonepileptiform). To assess diagnostic accuracy, we computed sensitivity, specificity, and accuracy of the AI model and the experts against the external gold standard.</p>\\n </section>\\n \\n <section>\\n \\n <h3> Results</h3>\\n \\n <p>We analyzed EEGs from 104 patients (64 females, median age = 38.6 [range = 16–91] years). SCORE-AI performed equally well compared to the experts, with an overall accuracy of 92% (95% confidence interval [CI] = 90%–94%) versus 94% (95% CI = 92%–96%). There was no significant difference between SCORE-AI and the experts for any metric or category. SCORE-AI performed well independently of the vigilance state (false classification during awake: 5/41 [12.2%], false classification during sleep: 2/11 [18.2%]; <i>p</i> = .63) and normal variants (false classification in presence of normal variants: 4/14 [28.6%], false classification in absence of normal variants: 3/38 [7.9%]; <i>p</i> = .07).</p>\\n </section>\\n \\n <section>\\n \\n <h3> Significance</h3>\\n \\n <p>SCORE-AI achieved diagnostic performance equal to human experts in an EEG dataset independent of the development dataset, in a geographically distinct patient population, recorded with different equipment and technical settings than the development dataset.</p>\\n </section>\\n </div>\",\"PeriodicalId\":11768,\"journal\":{\"name\":\"Epilepsia\",\"volume\":\"65 10\",\"pages\":\"3028-3037\"},\"PeriodicalIF\":5.6000,\"publicationDate\":\"2024-08-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/epi.18082\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Epilepsia\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/epi.18082\",\"RegionNum\":1,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CLINICAL NEUROLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Epilepsia","FirstCategoryId":"3","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/epi.18082","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CLINICAL NEUROLOGY","Score":null,"Total":0}
Generalizability of electroencephalographic interpretation using artificial intelligence: An external validation study
Objective
The automated interpretation of clinical electroencephalograms (EEGs) using artificial intelligence (AI) holds the potential to bridge the treatment gap in resource-limited settings and reduce the workload at specialized centers. However, to facilitate broad clinical implementation, it is essential to establish generalizability across diverse patient populations and equipment. We assessed whether SCORE-AI demonstrates diagnostic accuracy comparable to that of experts when applied to a geographically different patient population, recorded with distinct EEG equipment and technical settings.
Methods
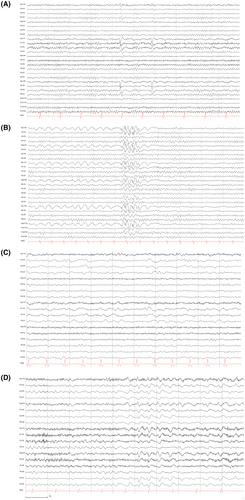
We assessed the diagnostic accuracy of a “fixed-and-frozen” AI model, using an independent dataset and external gold standard, and benchmarked it against three experts blinded to all other data. The dataset comprised 50% normal and 50% abnormal routine EEGs, equally distributed among the four major classes of EEG abnormalities (focal epileptiform, generalized epileptiform, focal nonepileptiform, and diffuse nonepileptiform). To assess diagnostic accuracy, we computed sensitivity, specificity, and accuracy of the AI model and the experts against the external gold standard.
Results
We analyzed EEGs from 104 patients (64 females, median age = 38.6 [range = 16–91] years). SCORE-AI performed equally well compared to the experts, with an overall accuracy of 92% (95% confidence interval [CI] = 90%–94%) versus 94% (95% CI = 92%–96%). There was no significant difference between SCORE-AI and the experts for any metric or category. SCORE-AI performed well independently of the vigilance state (false classification during awake: 5/41 [12.2%], false classification during sleep: 2/11 [18.2%]; p = .63) and normal variants (false classification in presence of normal variants: 4/14 [28.6%], false classification in absence of normal variants: 3/38 [7.9%]; p = .07).
Significance
SCORE-AI achieved diagnostic performance equal to human experts in an EEG dataset independent of the development dataset, in a geographically distinct patient population, recorded with different equipment and technical settings than the development dataset.
期刊介绍:
Epilepsia is the leading, authoritative source for innovative clinical and basic science research for all aspects of epilepsy and seizures. In addition, Epilepsia publishes critical reviews, opinion pieces, and guidelines that foster understanding and aim to improve the diagnosis and treatment of people with seizures and epilepsy.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
