Gianluca Mondillo, Vittoria Frattolillo, Simone Colosimo, Alessandra Perrotta, Anna Di Sessa, Stefano Guarino, Emanuele Miraglia Del Giudice, Pierluigi Marzuillo
{"title":"掌握小儿肾脏病学领域的基础知识,并通过 ChatGPT-4 \"omni \"和 Gemini 1.5 Flash 的专门培训加以提高。","authors":"Gianluca Mondillo, Vittoria Frattolillo, Simone Colosimo, Alessandra Perrotta, Anna Di Sessa, Stefano Guarino, Emanuele Miraglia Del Giudice, Pierluigi Marzuillo","doi":"10.1007/s00467-024-06486-3","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>We aimed to evaluate the baseline performance and improvement of ChatGPT-4 \"omni\" (ChatGPT-4o) and Gemini 1.5 Flash (Gemini 1.5) in answering multiple-choice questions related to pediatric nephrology after specific training.</p><p><strong>Methods: </strong>Using questions from the \"Educational Review\" articles published by Pediatric Nephrology between January 2014 and April 2024, the models were tested both before and after specific training with Portable Data Format (PDF) and text (TXT) file formats of the Educational Review articles removing the last page containing the correct answers using a Python script. The number of correct answers was recorded.</p><p><strong>Results: </strong>Before training, ChatGPT-4o correctly answered 75.2% of the 1395 questions, outperforming Gemini 1.5, which answered 64.9% correctly (p < 0.001). After training with PDF files, ChatGPT-4o's accuracy increased to 77.8%, while Gemini 1.5 improved significantly to 84.7% (p < 0.001). Training with TXT files showed similar results, with ChatGPT-4o maintaining 77.8% accuracy and Gemini 1.5 further improving to 87.6% (p < 0.001).</p><p><strong>Conclusions: </strong>The study highlights that while ChatGPT-4o has strong baseline performance, specific training does not significantly enhance its accuracy. Conversely, Gemini 1.5, despite its lower initial performance, shows substantial improvement with training, particularly with TXT files. These findings suggest Gemini 1.5's superior ability to store and retrieve information, making it potentially more effective in clinical applications, albeit with a dependency on additional data for optimal performance.</p>","PeriodicalId":19735,"journal":{"name":"Pediatric Nephrology","volume":" ","pages":"151-157"},"PeriodicalIF":2.5000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11584465/pdf/","citationCount":"0","resultStr":"{\"title\":\"Basal knowledge in the field of pediatric nephrology and its enhancement following specific training of ChatGPT-4 \\\"omni\\\" and Gemini 1.5 Flash.\",\"authors\":\"Gianluca Mondillo, Vittoria Frattolillo, Simone Colosimo, Alessandra Perrotta, Anna Di Sessa, Stefano Guarino, Emanuele Miraglia Del Giudice, Pierluigi Marzuillo\",\"doi\":\"10.1007/s00467-024-06486-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>We aimed to evaluate the baseline performance and improvement of ChatGPT-4 \\\"omni\\\" (ChatGPT-4o) and Gemini 1.5 Flash (Gemini 1.5) in answering multiple-choice questions related to pediatric nephrology after specific training.</p><p><strong>Methods: </strong>Using questions from the \\\"Educational Review\\\" articles published by Pediatric Nephrology between January 2014 and April 2024, the models were tested both before and after specific training with Portable Data Format (PDF) and text (TXT) file formats of the Educational Review articles removing the last page containing the correct answers using a Python script. The number of correct answers was recorded.</p><p><strong>Results: </strong>Before training, ChatGPT-4o correctly answered 75.2% of the 1395 questions, outperforming Gemini 1.5, which answered 64.9% correctly (p < 0.001). After training with PDF files, ChatGPT-4o's accuracy increased to 77.8%, while Gemini 1.5 improved significantly to 84.7% (p < 0.001). Training with TXT files showed similar results, with ChatGPT-4o maintaining 77.8% accuracy and Gemini 1.5 further improving to 87.6% (p < 0.001).</p><p><strong>Conclusions: </strong>The study highlights that while ChatGPT-4o has strong baseline performance, specific training does not significantly enhance its accuracy. Conversely, Gemini 1.5, despite its lower initial performance, shows substantial improvement with training, particularly with TXT files. These findings suggest Gemini 1.5's superior ability to store and retrieve information, making it potentially more effective in clinical applications, albeit with a dependency on additional data for optimal performance.</p>\",\"PeriodicalId\":19735,\"journal\":{\"name\":\"Pediatric Nephrology\",\"volume\":\" \",\"pages\":\"151-157\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11584465/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Pediatric Nephrology\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1007/s00467-024-06486-3\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/8/16 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"PEDIATRICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pediatric Nephrology","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1007/s00467-024-06486-3","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/16 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"PEDIATRICS","Score":null,"Total":0}
Basal knowledge in the field of pediatric nephrology and its enhancement following specific training of ChatGPT-4 "omni" and Gemini 1.5 Flash.
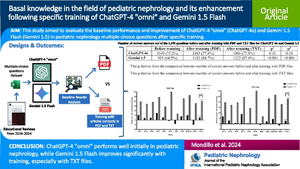
Background: We aimed to evaluate the baseline performance and improvement of ChatGPT-4 "omni" (ChatGPT-4o) and Gemini 1.5 Flash (Gemini 1.5) in answering multiple-choice questions related to pediatric nephrology after specific training.
Methods: Using questions from the "Educational Review" articles published by Pediatric Nephrology between January 2014 and April 2024, the models were tested both before and after specific training with Portable Data Format (PDF) and text (TXT) file formats of the Educational Review articles removing the last page containing the correct answers using a Python script. The number of correct answers was recorded.
Results: Before training, ChatGPT-4o correctly answered 75.2% of the 1395 questions, outperforming Gemini 1.5, which answered 64.9% correctly (p < 0.001). After training with PDF files, ChatGPT-4o's accuracy increased to 77.8%, while Gemini 1.5 improved significantly to 84.7% (p < 0.001). Training with TXT files showed similar results, with ChatGPT-4o maintaining 77.8% accuracy and Gemini 1.5 further improving to 87.6% (p < 0.001).
Conclusions: The study highlights that while ChatGPT-4o has strong baseline performance, specific training does not significantly enhance its accuracy. Conversely, Gemini 1.5, despite its lower initial performance, shows substantial improvement with training, particularly with TXT files. These findings suggest Gemini 1.5's superior ability to store and retrieve information, making it potentially more effective in clinical applications, albeit with a dependency on additional data for optimal performance.
期刊介绍:
International Pediatric Nephrology Association
Pediatric Nephrology publishes original clinical research related to acute and chronic diseases that affect renal function, blood pressure, and fluid and electrolyte disorders in children. Studies may involve medical, surgical, nutritional, physiologic, biochemical, genetic, pathologic or immunologic aspects of disease, imaging techniques or consequences of acute or chronic kidney disease. There are 12 issues per year that contain Editorial Commentaries, Reviews, Educational Reviews, Original Articles, Brief Reports, Rapid Communications, Clinical Quizzes, and Letters to the Editors.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
