Kaixin Jin, Xiaoling Gu, Zimeng Wang, Zhenzhong Kuang, Zizhao Wu, Min Tan, Jun Yu
{"title":"用于面部头像重建的语义感知超空间可变形神经辐射场","authors":"Kaixin Jin, Xiaoling Gu, Zimeng Wang, Zhenzhong Kuang, Zizhao Wu, Min Tan, Jun Yu","doi":"10.1016/j.patrec.2024.08.004","DOIUrl":null,"url":null,"abstract":"<div><p>High-fidelity facial avatar reconstruction from monocular videos is a prominent research problem in computer graphics and computer vision. Recent advancements in the Neural Radiance Field (NeRF) have demonstrated remarkable proficiency in rendering novel views and garnered attention for its potential in facial avatar reconstruction. However, previous methodologies have overlooked the complex motion dynamics present across the head, torso, and intricate facial features. Additionally, a deficiency exists in a generalized NeRF-based framework for facial avatar reconstruction adaptable to either 3DMM coefficients or audio input. To tackle these challenges, we propose an innovative framework that leverages semantic-aware hyper-space deformable NeRF, facilitating the reconstruction of high-fidelity facial avatars from either 3DMM coefficients or audio features. Our framework effectively addresses both localized facial movements and broader head and torso motions through semantic guidance and a unified hyper-space deformation module. Specifically, we adopt a dynamic weighted ray sampling strategy to allocate varying degrees of attention to distinct semantic regions, enhancing the deformable NeRF framework with semantic guidance to capture fine-grained details across diverse facial regions. Moreover, we introduce a hyper-space deformation module that enables the transformation of observation space coordinates into canonical hyper-space coordinates, allowing for the learning of natural facial deformation and head-torso movements. Extensive experiments validate the superiority of our framework over existing state-of-the-art methods, demonstrating its effectiveness in producing realistic and expressive facial avatars. Our code is available at <span><span>https://github.com/jematy/SAHS-Deformable-Nerf</span><svg><path></path></svg></span>.</p></div>","PeriodicalId":54638,"journal":{"name":"Pattern Recognition Letters","volume":"185 ","pages":"Pages 160-166"},"PeriodicalIF":3.3000,"publicationDate":"2024-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Semantic-aware hyper-space deformable neural radiance fields for facial avatar reconstruction\",\"authors\":\"Kaixin Jin, Xiaoling Gu, Zimeng Wang, Zhenzhong Kuang, Zizhao Wu, Min Tan, Jun Yu\",\"doi\":\"10.1016/j.patrec.2024.08.004\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>High-fidelity facial avatar reconstruction from monocular videos is a prominent research problem in computer graphics and computer vision. Recent advancements in the Neural Radiance Field (NeRF) have demonstrated remarkable proficiency in rendering novel views and garnered attention for its potential in facial avatar reconstruction. However, previous methodologies have overlooked the complex motion dynamics present across the head, torso, and intricate facial features. Additionally, a deficiency exists in a generalized NeRF-based framework for facial avatar reconstruction adaptable to either 3DMM coefficients or audio input. To tackle these challenges, we propose an innovative framework that leverages semantic-aware hyper-space deformable NeRF, facilitating the reconstruction of high-fidelity facial avatars from either 3DMM coefficients or audio features. Our framework effectively addresses both localized facial movements and broader head and torso motions through semantic guidance and a unified hyper-space deformation module. Specifically, we adopt a dynamic weighted ray sampling strategy to allocate varying degrees of attention to distinct semantic regions, enhancing the deformable NeRF framework with semantic guidance to capture fine-grained details across diverse facial regions. Moreover, we introduce a hyper-space deformation module that enables the transformation of observation space coordinates into canonical hyper-space coordinates, allowing for the learning of natural facial deformation and head-torso movements. Extensive experiments validate the superiority of our framework over existing state-of-the-art methods, demonstrating its effectiveness in producing realistic and expressive facial avatars. Our code is available at <span><span>https://github.com/jematy/SAHS-Deformable-Nerf</span><svg><path></path></svg></span>.</p></div>\",\"PeriodicalId\":54638,\"journal\":{\"name\":\"Pattern Recognition Letters\",\"volume\":\"185 \",\"pages\":\"Pages 160-166\"},\"PeriodicalIF\":3.3000,\"publicationDate\":\"2024-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Pattern Recognition Letters\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0167865524002368\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/8/10 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pattern Recognition Letters","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0167865524002368","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/10 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Semantic-aware hyper-space deformable neural radiance fields for facial avatar reconstruction
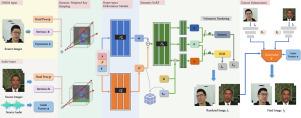
High-fidelity facial avatar reconstruction from monocular videos is a prominent research problem in computer graphics and computer vision. Recent advancements in the Neural Radiance Field (NeRF) have demonstrated remarkable proficiency in rendering novel views and garnered attention for its potential in facial avatar reconstruction. However, previous methodologies have overlooked the complex motion dynamics present across the head, torso, and intricate facial features. Additionally, a deficiency exists in a generalized NeRF-based framework for facial avatar reconstruction adaptable to either 3DMM coefficients or audio input. To tackle these challenges, we propose an innovative framework that leverages semantic-aware hyper-space deformable NeRF, facilitating the reconstruction of high-fidelity facial avatars from either 3DMM coefficients or audio features. Our framework effectively addresses both localized facial movements and broader head and torso motions through semantic guidance and a unified hyper-space deformation module. Specifically, we adopt a dynamic weighted ray sampling strategy to allocate varying degrees of attention to distinct semantic regions, enhancing the deformable NeRF framework with semantic guidance to capture fine-grained details across diverse facial regions. Moreover, we introduce a hyper-space deformation module that enables the transformation of observation space coordinates into canonical hyper-space coordinates, allowing for the learning of natural facial deformation and head-torso movements. Extensive experiments validate the superiority of our framework over existing state-of-the-art methods, demonstrating its effectiveness in producing realistic and expressive facial avatars. Our code is available at https://github.com/jematy/SAHS-Deformable-Nerf.
期刊介绍:
Pattern Recognition Letters aims at rapid publication of concise articles of a broad interest in pattern recognition.
Subject areas include all the current fields of interest represented by the Technical Committees of the International Association of Pattern Recognition, and other developing themes involving learning and recognition.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
