Dongjin Huang , Nan Wang , Xinghan Huang , Jiantao Qu , Shiyu Zhang
{"title":"网格可控的多级细节文本三维生成技术","authors":"Dongjin Huang , Nan Wang , Xinghan Huang , Jiantao Qu , Shiyu Zhang","doi":"10.1016/j.cag.2024.104039","DOIUrl":null,"url":null,"abstract":"<div><p>Text-to-3D generation is a challenging but significant task and has gained widespread attention. Its capability to rapidly generate 3D digital assets holds huge potential application value in fields such as film, video games, and virtual reality. However, current methods often face several drawbacks, including long generation times, difficulties with the multi-face Janus problem, and issues like chaotic topology and redundant structures during mesh extraction. Additionally, the lack of control over the generated results limits their utility in downstream applications. To address these problems, we propose a novel text-to-3D framework capable of generating meshes with high fidelity and controllability. Our approach can efficiently produce meshes and textures that match the text description and the desired level of detail (LOD) by specifying input text and LOD preferences. This framework consists of two stages. In the coarse stage, 3D Gaussians are employed to accelerate generation speed, and weighted positive and negative prompts from various observation perspectives are used to address the multi-face Janus problem in the generated results. In the refinement stage, mesh vertices and faces are iteratively refined to enhance surface quality and output meshes and textures that meet specified LOD requirements. Compared to the state-of-the-art text-to-3D methods, extensive experiments demonstrate that the proposed method performs better in solving the multi-face Janus problem, enabling the rapid generation of 3D meshes with enhanced prompt adherence. Furthermore, the proposed framework can generate meshes with enhanced topology, offering controllable vertices and faces with textures featuring UV adaptation to achieve multi-level-of-detail(LODs) outputs. Specifically, the proposed method can preserve the output’s relevance to input texts during simplification, making it better suited for mesh editing and rendering efficiency. User studies also indicate that our framework receives higher evaluations compared to other methods.</p></div>","PeriodicalId":50628,"journal":{"name":"Computers & Graphics-Uk","volume":"123 ","pages":"Article 104039"},"PeriodicalIF":2.8000,"publicationDate":"2024-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Mesh-controllable multi-level-of-detail text-to-3D generation\",\"authors\":\"Dongjin Huang , Nan Wang , Xinghan Huang , Jiantao Qu , Shiyu Zhang\",\"doi\":\"10.1016/j.cag.2024.104039\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Text-to-3D generation is a challenging but significant task and has gained widespread attention. Its capability to rapidly generate 3D digital assets holds huge potential application value in fields such as film, video games, and virtual reality. However, current methods often face several drawbacks, including long generation times, difficulties with the multi-face Janus problem, and issues like chaotic topology and redundant structures during mesh extraction. Additionally, the lack of control over the generated results limits their utility in downstream applications. To address these problems, we propose a novel text-to-3D framework capable of generating meshes with high fidelity and controllability. Our approach can efficiently produce meshes and textures that match the text description and the desired level of detail (LOD) by specifying input text and LOD preferences. This framework consists of two stages. In the coarse stage, 3D Gaussians are employed to accelerate generation speed, and weighted positive and negative prompts from various observation perspectives are used to address the multi-face Janus problem in the generated results. In the refinement stage, mesh vertices and faces are iteratively refined to enhance surface quality and output meshes and textures that meet specified LOD requirements. Compared to the state-of-the-art text-to-3D methods, extensive experiments demonstrate that the proposed method performs better in solving the multi-face Janus problem, enabling the rapid generation of 3D meshes with enhanced prompt adherence. Furthermore, the proposed framework can generate meshes with enhanced topology, offering controllable vertices and faces with textures featuring UV adaptation to achieve multi-level-of-detail(LODs) outputs. Specifically, the proposed method can preserve the output’s relevance to input texts during simplification, making it better suited for mesh editing and rendering efficiency. User studies also indicate that our framework receives higher evaluations compared to other methods.</p></div>\",\"PeriodicalId\":50628,\"journal\":{\"name\":\"Computers & Graphics-Uk\",\"volume\":\"123 \",\"pages\":\"Article 104039\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computers & Graphics-Uk\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0097849324001742\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/8/10 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Graphics-Uk","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0097849324001742","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/10 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
摘要
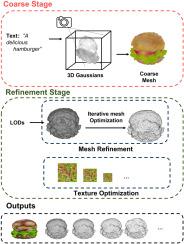
文本到 3D 的生成是一项具有挑战性但意义重大的任务,已受到广泛关注。它能够快速生成三维数字资产,在电影、视频游戏和虚拟现实等领域具有巨大的潜在应用价值。然而,当前的方法往往面临一些缺陷,包括生成时间长、难以解决多面杰纳斯问题,以及网格提取过程中的拓扑结构混乱和冗余结构等问题。此外,对生成结果缺乏控制也限制了其在下游应用中的实用性。为了解决这些问题,我们提出了一种新颖的文本到三维框架,能够生成高保真和可控的网格。通过指定输入文本和 LOD 偏好,我们的方法可以高效生成符合文本描述和所需细节级别(LOD)的网格和纹理。该框架由两个阶段组成。在粗化阶段,使用三维高斯来加快生成速度,并使用来自不同观察视角的加权正负提示来解决生成结果中的多面简纳斯问题。在细化阶段,对网格顶点和面进行迭代细化,以提高表面质量,并输出符合指定 LOD 要求的网格和纹理。与最先进的文本到三维方法相比,大量实验证明,所提出的方法在解决多面简努斯问题方面表现更佳,能够快速生成三维网格,并增强了及时性。此外,所提出的框架还能生成具有增强拓扑结构的网格,提供可控顶点和具有 UV 自适应纹理的面,从而实现多级细节(LOD)输出。具体来说,建议的方法可以在简化过程中保持输出与输入文本的相关性,使其更适合网格编辑和提高渲染效率。用户研究还表明,与其他方法相比,我们的框架获得了更高的评价。
Text-to-3D generation is a challenging but significant task and has gained widespread attention. Its capability to rapidly generate 3D digital assets holds huge potential application value in fields such as film, video games, and virtual reality. However, current methods often face several drawbacks, including long generation times, difficulties with the multi-face Janus problem, and issues like chaotic topology and redundant structures during mesh extraction. Additionally, the lack of control over the generated results limits their utility in downstream applications. To address these problems, we propose a novel text-to-3D framework capable of generating meshes with high fidelity and controllability. Our approach can efficiently produce meshes and textures that match the text description and the desired level of detail (LOD) by specifying input text and LOD preferences. This framework consists of two stages. In the coarse stage, 3D Gaussians are employed to accelerate generation speed, and weighted positive and negative prompts from various observation perspectives are used to address the multi-face Janus problem in the generated results. In the refinement stage, mesh vertices and faces are iteratively refined to enhance surface quality and output meshes and textures that meet specified LOD requirements. Compared to the state-of-the-art text-to-3D methods, extensive experiments demonstrate that the proposed method performs better in solving the multi-face Janus problem, enabling the rapid generation of 3D meshes with enhanced prompt adherence. Furthermore, the proposed framework can generate meshes with enhanced topology, offering controllable vertices and faces with textures featuring UV adaptation to achieve multi-level-of-detail(LODs) outputs. Specifically, the proposed method can preserve the output’s relevance to input texts during simplification, making it better suited for mesh editing and rendering efficiency. User studies also indicate that our framework receives higher evaluations compared to other methods.
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
