Wei Zhou , Qian Wang , Weiwei Jin , Xinzhe Shi , Ying He
{"title":"用于三维点云分类和语义分割的图形变换器","authors":"Wei Zhou , Qian Wang , Weiwei Jin , Xinzhe Shi , Ying He","doi":"10.1016/j.cag.2024.104050","DOIUrl":null,"url":null,"abstract":"<div><p>Recently, graph-based and Transformer-based deep learning have demonstrated excellent performances on various point cloud tasks. Most of the existing graph-based methods rely on static graph, which take a fixed input to establish graph relations. Moreover, many graph-based methods apply maximizing and averaging to aggregate neighboring features, so that only a single neighboring point affects the feature of centroid or different neighboring points own the same influence on the centroid’s feature, which ignoring the correlation and difference between points. Most Transformer-based approaches extract point cloud features based on global attention and lack the feature learning on local neighbors. To solve the above issues of graph-based and Transformer-based models, we propose a new feature extraction block named Graph Transformer and construct a 3D point cloud learning network called GTNet to learn features of point clouds on local and global patterns. Graph Transformer integrates the advantages of graph-based and Transformer-based methods, and consists of Local Transformer that use intra-domain cross-attention and Global Transformer that use global self-attention. Finally, we use GTNet for shape classification, part segmentation and semantic segmentation tasks in this paper. The experimental results show that our model achieves good learning and prediction ability on most tasks. The source code and pre-trained model of GTNet will be released on <span><span>https://github.com/NWUzhouwei/GTNet</span><svg><path></path></svg></span>.</p></div>","PeriodicalId":50628,"journal":{"name":"Computers & Graphics-Uk","volume":"124 ","pages":"Article 104050"},"PeriodicalIF":2.8000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Graph Transformer for 3D point clouds classification and semantic segmentation\",\"authors\":\"Wei Zhou , Qian Wang , Weiwei Jin , Xinzhe Shi , Ying He\",\"doi\":\"10.1016/j.cag.2024.104050\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Recently, graph-based and Transformer-based deep learning have demonstrated excellent performances on various point cloud tasks. Most of the existing graph-based methods rely on static graph, which take a fixed input to establish graph relations. Moreover, many graph-based methods apply maximizing and averaging to aggregate neighboring features, so that only a single neighboring point affects the feature of centroid or different neighboring points own the same influence on the centroid’s feature, which ignoring the correlation and difference between points. Most Transformer-based approaches extract point cloud features based on global attention and lack the feature learning on local neighbors. To solve the above issues of graph-based and Transformer-based models, we propose a new feature extraction block named Graph Transformer and construct a 3D point cloud learning network called GTNet to learn features of point clouds on local and global patterns. Graph Transformer integrates the advantages of graph-based and Transformer-based methods, and consists of Local Transformer that use intra-domain cross-attention and Global Transformer that use global self-attention. Finally, we use GTNet for shape classification, part segmentation and semantic segmentation tasks in this paper. The experimental results show that our model achieves good learning and prediction ability on most tasks. The source code and pre-trained model of GTNet will be released on <span><span>https://github.com/NWUzhouwei/GTNet</span><svg><path></path></svg></span>.</p></div>\",\"PeriodicalId\":50628,\"journal\":{\"name\":\"Computers & Graphics-Uk\",\"volume\":\"124 \",\"pages\":\"Article 104050\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-11-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computers & Graphics-Uk\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0097849324001857\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/8/22 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Graphics-Uk","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0097849324001857","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/22 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Graph Transformer for 3D point clouds classification and semantic segmentation
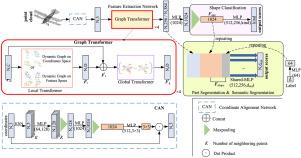
Recently, graph-based and Transformer-based deep learning have demonstrated excellent performances on various point cloud tasks. Most of the existing graph-based methods rely on static graph, which take a fixed input to establish graph relations. Moreover, many graph-based methods apply maximizing and averaging to aggregate neighboring features, so that only a single neighboring point affects the feature of centroid or different neighboring points own the same influence on the centroid’s feature, which ignoring the correlation and difference between points. Most Transformer-based approaches extract point cloud features based on global attention and lack the feature learning on local neighbors. To solve the above issues of graph-based and Transformer-based models, we propose a new feature extraction block named Graph Transformer and construct a 3D point cloud learning network called GTNet to learn features of point clouds on local and global patterns. Graph Transformer integrates the advantages of graph-based and Transformer-based methods, and consists of Local Transformer that use intra-domain cross-attention and Global Transformer that use global self-attention. Finally, we use GTNet for shape classification, part segmentation and semantic segmentation tasks in this paper. The experimental results show that our model achieves good learning and prediction ability on most tasks. The source code and pre-trained model of GTNet will be released on https://github.com/NWUzhouwei/GTNet.
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
