Yu-Chen Liu , Yi-Jing Lin , Yan-Yun Chang , Cheng-Che Chuang , Yu-Yen Ou
{"title":"破译蛋白质-DNA相互作用的语言:结合上下文嵌入和多尺度序列建模的深度学习方法","authors":"Yu-Chen Liu , Yi-Jing Lin , Yan-Yun Chang , Cheng-Che Chuang , Yu-Yen Ou","doi":"10.1016/j.jmb.2024.168769","DOIUrl":null,"url":null,"abstract":"<div><p>Deciphering the mechanisms governing protein-DNA interactions is crucial for understanding key cellular processes and disease pathways. In this work, we present a powerful deep learning approach that significantly advances the computational prediction of DNA-interacting residues from protein sequences.</p><p>Our method leverages the rich contextual representations learned by pre-trained protein language models, such as ProtTrans, to capture intrinsic biochemical properties and sequence motifs indicative of DNA binding sites. We then integrate these contextual embeddings with a multi-window convolutional neural network architecture, which scans across the sequence at varying window sizes to effectively identify both local and global binding patterns.</p><p>Comprehensive evaluation on curated benchmark datasets demonstrates the remarkable performance of our approach, achieving an area under the ROC curve (AUC) of 0.89 – a substantial improvement over previous state-of-the-art sequence-based predictors. This showcases the immense potential of pairing advanced representation learning and deep neural network designs for uncovering the complex syntax governing protein-DNA interactions directly from primary sequences.</p><p>Our work not only provides a robust computational tool for characterizing DNA-binding mechanisms, but also highlights the transformative opportunities at the intersection of language modeling, deep learning, and protein sequence analysis. The publicly available code and data further facilitate broader adoption and continued development of these techniques for accelerating mechanistic insights into vital biological processes and disease pathways.</p><p>In addition, the code and data for this work are available at <span><span>https://github.com/B1607/DIRP</span><svg><path></path></svg></span>.</p></div>","PeriodicalId":369,"journal":{"name":"Journal of Molecular Biology","volume":"436 22","pages":"Article 168769"},"PeriodicalIF":4.7000,"publicationDate":"2024-08-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0022283624003899/pdfft?md5=48e8a1f78b82ff4e5d3d37956f6b0f26&pid=1-s2.0-S0022283624003899-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Deciphering the Language of Protein-DNA Interactions: A Deep Learning Approach Combining Contextual Embeddings and Multi-Scale Sequence Modeling\",\"authors\":\"Yu-Chen Liu , Yi-Jing Lin , Yan-Yun Chang , Cheng-Che Chuang , Yu-Yen Ou\",\"doi\":\"10.1016/j.jmb.2024.168769\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Deciphering the mechanisms governing protein-DNA interactions is crucial for understanding key cellular processes and disease pathways. In this work, we present a powerful deep learning approach that significantly advances the computational prediction of DNA-interacting residues from protein sequences.</p><p>Our method leverages the rich contextual representations learned by pre-trained protein language models, such as ProtTrans, to capture intrinsic biochemical properties and sequence motifs indicative of DNA binding sites. We then integrate these contextual embeddings with a multi-window convolutional neural network architecture, which scans across the sequence at varying window sizes to effectively identify both local and global binding patterns.</p><p>Comprehensive evaluation on curated benchmark datasets demonstrates the remarkable performance of our approach, achieving an area under the ROC curve (AUC) of 0.89 – a substantial improvement over previous state-of-the-art sequence-based predictors. This showcases the immense potential of pairing advanced representation learning and deep neural network designs for uncovering the complex syntax governing protein-DNA interactions directly from primary sequences.</p><p>Our work not only provides a robust computational tool for characterizing DNA-binding mechanisms, but also highlights the transformative opportunities at the intersection of language modeling, deep learning, and protein sequence analysis. The publicly available code and data further facilitate broader adoption and continued development of these techniques for accelerating mechanistic insights into vital biological processes and disease pathways.</p><p>In addition, the code and data for this work are available at <span><span>https://github.com/B1607/DIRP</span><svg><path></path></svg></span>.</p></div>\",\"PeriodicalId\":369,\"journal\":{\"name\":\"Journal of Molecular Biology\",\"volume\":\"436 22\",\"pages\":\"Article 168769\"},\"PeriodicalIF\":4.7000,\"publicationDate\":\"2024-08-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S0022283624003899/pdfft?md5=48e8a1f78b82ff4e5d3d37956f6b0f26&pid=1-s2.0-S0022283624003899-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Molecular Biology\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0022283624003899\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMISTRY & MOLECULAR BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Molecular Biology","FirstCategoryId":"99","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0022283624003899","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
破译蛋白质与 DNA 的相互作用机制对于理解关键的细胞过程和疾病途径至关重要。在这项工作中,我们提出了一种强大的深度学习方法,大大推进了对蛋白质序列中 DNA 相互作用残基的计算预测。我们的方法利用了预先训练的蛋白质语言模型(如 ProtTrans)所学习到的丰富上下文表征,以捕捉表明 DNA 结合位点的内在生化特性和序列图案。然后,我们将这些上下文嵌入与多窗口卷积神经网络架构相结合,该架构以不同的窗口大小扫描整个序列,从而有效识别局部和全局结合模式。在经过策划的基准数据集上进行的综合评估表明,我们的方法性能卓越,ROC 曲线下面积(AUC)达到了 0.89,比以前最先进的基于序列的预测方法有了大幅提高。这展示了先进的表示学习和深度神经网络设计在直接从主序列揭示支配蛋白质-DNA 相互作用的复杂语法方面的巨大潜力。我们的工作不仅为表征 DNA 结合机制提供了强大的计算工具,还凸显了语言建模、深度学习和蛋白质序列分析交叉领域的变革机遇。公开的代码和数据进一步促进了这些技术的广泛应用和持续发展,加快了对重要生物过程和疾病途径的机理认识。此外,这项工作的代码和数据可在 https://github.com/B1607/DIRP 上获取。
Deciphering the Language of Protein-DNA Interactions: A Deep Learning Approach Combining Contextual Embeddings and Multi-Scale Sequence Modeling
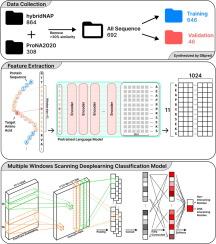
Deciphering the mechanisms governing protein-DNA interactions is crucial for understanding key cellular processes and disease pathways. In this work, we present a powerful deep learning approach that significantly advances the computational prediction of DNA-interacting residues from protein sequences.
Our method leverages the rich contextual representations learned by pre-trained protein language models, such as ProtTrans, to capture intrinsic biochemical properties and sequence motifs indicative of DNA binding sites. We then integrate these contextual embeddings with a multi-window convolutional neural network architecture, which scans across the sequence at varying window sizes to effectively identify both local and global binding patterns.
Comprehensive evaluation on curated benchmark datasets demonstrates the remarkable performance of our approach, achieving an area under the ROC curve (AUC) of 0.89 – a substantial improvement over previous state-of-the-art sequence-based predictors. This showcases the immense potential of pairing advanced representation learning and deep neural network designs for uncovering the complex syntax governing protein-DNA interactions directly from primary sequences.
Our work not only provides a robust computational tool for characterizing DNA-binding mechanisms, but also highlights the transformative opportunities at the intersection of language modeling, deep learning, and protein sequence analysis. The publicly available code and data further facilitate broader adoption and continued development of these techniques for accelerating mechanistic insights into vital biological processes and disease pathways.
In addition, the code and data for this work are available at https://github.com/B1607/DIRP.
期刊介绍:
Journal of Molecular Biology (JMB) provides high quality, comprehensive and broad coverage in all areas of molecular biology. The journal publishes original scientific research papers that provide mechanistic and functional insights and report a significant advance to the field. The journal encourages the submission of multidisciplinary studies that use complementary experimental and computational approaches to address challenging biological questions.
Research areas include but are not limited to: Biomolecular interactions, signaling networks, systems biology; Cell cycle, cell growth, cell differentiation; Cell death, autophagy; Cell signaling and regulation; Chemical biology; Computational biology, in combination with experimental studies; DNA replication, repair, and recombination; Development, regenerative biology, mechanistic and functional studies of stem cells; Epigenetics, chromatin structure and function; Gene expression; Membrane processes, cell surface proteins and cell-cell interactions; Methodological advances, both experimental and theoretical, including databases; Microbiology, virology, and interactions with the host or environment; Microbiota mechanistic and functional studies; Nuclear organization; Post-translational modifications, proteomics; Processing and function of biologically important macromolecules and complexes; Molecular basis of disease; RNA processing, structure and functions of non-coding RNAs, transcription; Sorting, spatiotemporal organization, trafficking; Structural biology; Synthetic biology; Translation, protein folding, chaperones, protein degradation and quality control.


 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
