James McKevitt , Eduard I. Vorobyov , Igor Kulikov
{"title":"加速 Fortran 代码:将 Coarray Fortran 与 CUDA Fortran 和 OpenMP 集成的方法","authors":"James McKevitt , Eduard I. Vorobyov , Igor Kulikov","doi":"10.1016/j.jpdc.2024.104977","DOIUrl":null,"url":null,"abstract":"<div><p>Fortran's prominence in scientific computing requires strategies to ensure both that legacy codes are efficient on high-performance computing systems, and that the language remains attractive for the development of new high-performance codes. Coarray Fortran (CAF), part of the Fortran 2008 standard introduced for parallel programming, facilitates distributed memory parallelism with a syntax familiar to Fortran programmers, simplifying the transition from single-processor to multi-processor coding. This research focuses on innovating and refining a parallel programming methodology that fuses the strengths of Intel Coarray Fortran, Nvidia CUDA Fortran, and OpenMP for distributed memory parallelism, high-speed GPU acceleration and shared memory parallelism respectively. We consider the management of pageable and pinned memory, CPU-GPU affinity in NUMA multiprocessors, and robust compiler interfacing with speed optimisation. We demonstrate our method through its application to a parallelised Poisson solver and compare the methodology, implementation, and scaling performance to that of the Message Passing Interface (MPI), finding CAF offers similar speeds with easier implementation. For new codes, this approach offers a faster route to optimised parallel computing. For legacy codes, it eases the transition to parallel computing, allowing their transformation into scalable, high-performance computing applications without the need for extensive re-design or additional syntax.</p></div>","PeriodicalId":54775,"journal":{"name":"Journal of Parallel and Distributed Computing","volume":"195 ","pages":"Article 104977"},"PeriodicalIF":4.0000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0743731524001412/pdfft?md5=69e1ea2ba9c62d46ed1506e701029846&pid=1-s2.0-S0743731524001412-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Accelerating Fortran codes: A method for integrating Coarray Fortran with CUDA Fortran and OpenMP\",\"authors\":\"James McKevitt , Eduard I. Vorobyov , Igor Kulikov\",\"doi\":\"10.1016/j.jpdc.2024.104977\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Fortran's prominence in scientific computing requires strategies to ensure both that legacy codes are efficient on high-performance computing systems, and that the language remains attractive for the development of new high-performance codes. Coarray Fortran (CAF), part of the Fortran 2008 standard introduced for parallel programming, facilitates distributed memory parallelism with a syntax familiar to Fortran programmers, simplifying the transition from single-processor to multi-processor coding. This research focuses on innovating and refining a parallel programming methodology that fuses the strengths of Intel Coarray Fortran, Nvidia CUDA Fortran, and OpenMP for distributed memory parallelism, high-speed GPU acceleration and shared memory parallelism respectively. We consider the management of pageable and pinned memory, CPU-GPU affinity in NUMA multiprocessors, and robust compiler interfacing with speed optimisation. We demonstrate our method through its application to a parallelised Poisson solver and compare the methodology, implementation, and scaling performance to that of the Message Passing Interface (MPI), finding CAF offers similar speeds with easier implementation. For new codes, this approach offers a faster route to optimised parallel computing. For legacy codes, it eases the transition to parallel computing, allowing their transformation into scalable, high-performance computing applications without the need for extensive re-design or additional syntax.</p></div>\",\"PeriodicalId\":54775,\"journal\":{\"name\":\"Journal of Parallel and Distributed Computing\",\"volume\":\"195 \",\"pages\":\"Article 104977\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S0743731524001412/pdfft?md5=69e1ea2ba9c62d46ed1506e701029846&pid=1-s2.0-S0743731524001412-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Parallel and Distributed Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0743731524001412\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/9/6 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Parallel and Distributed Computing","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0743731524001412","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/6 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
Accelerating Fortran codes: A method for integrating Coarray Fortran with CUDA Fortran and OpenMP
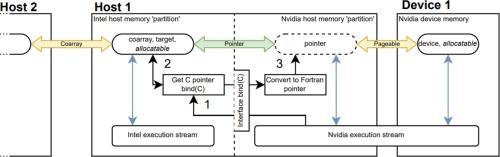
Fortran's prominence in scientific computing requires strategies to ensure both that legacy codes are efficient on high-performance computing systems, and that the language remains attractive for the development of new high-performance codes. Coarray Fortran (CAF), part of the Fortran 2008 standard introduced for parallel programming, facilitates distributed memory parallelism with a syntax familiar to Fortran programmers, simplifying the transition from single-processor to multi-processor coding. This research focuses on innovating and refining a parallel programming methodology that fuses the strengths of Intel Coarray Fortran, Nvidia CUDA Fortran, and OpenMP for distributed memory parallelism, high-speed GPU acceleration and shared memory parallelism respectively. We consider the management of pageable and pinned memory, CPU-GPU affinity in NUMA multiprocessors, and robust compiler interfacing with speed optimisation. We demonstrate our method through its application to a parallelised Poisson solver and compare the methodology, implementation, and scaling performance to that of the Message Passing Interface (MPI), finding CAF offers similar speeds with easier implementation. For new codes, this approach offers a faster route to optimised parallel computing. For legacy codes, it eases the transition to parallel computing, allowing their transformation into scalable, high-performance computing applications without the need for extensive re-design or additional syntax.
期刊介绍:
This international journal is directed to researchers, engineers, educators, managers, programmers, and users of computers who have particular interests in parallel processing and/or distributed computing.
The Journal of Parallel and Distributed Computing publishes original research papers and timely review articles on the theory, design, evaluation, and use of parallel and/or distributed computing systems. The journal also features special issues on these topics; again covering the full range from the design to the use of our targeted systems.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
