Rafael V. Azevedo , Thiago M. Coutinho , João P. Ferreira , Thiago L. Gomes , Erickson R. Nascimento
{"title":"增强手语交流能力:整合情感和语义进行面部表情合成","authors":"Rafael V. Azevedo , Thiago M. Coutinho , João P. Ferreira , Thiago L. Gomes , Erickson R. Nascimento","doi":"10.1016/j.cag.2024.104065","DOIUrl":null,"url":null,"abstract":"<div><p>Translating written sentences from oral languages to a sequence of manual and non-manual gestures plays a crucial role in building a more inclusive society for deaf and hard-of-hearing people. Facial expressions (non-manual), in particular, are responsible for encoding the grammar of the sentence to be spoken, applying punctuation, pronouns, or emphasizing signs. These non-manual gestures are closely related to the semantics of the sentence being spoken and also to the utterance of the speaker’s emotions. However, most Sign Language Production (SLP) approaches are centered on synthesizing manual gestures and do not focus on modeling the speaker’s expression. This paper introduces a new method focused in synthesizing facial expressions for sign language. Our goal is to improve sign language production by integrating sentiment information in facial expression generation. The approach leverages a sentence’s sentiment and semantic features to sample from a meaningful representation space, integrating the bias of the non-manual components into the sign language production process. To evaluate our method, we extend the Fréchet gesture distance (FGD) and propose a new metric called Fréchet Expression Distance (FED) and apply an extensive set of metrics to assess the quality of specific regions of the face. The experimental results showed that our method achieved state of the art, being superior to the competitors on How2Sign and PHOENIX14T datasets. Moreover, our architecture is based on a carefully designed graph pyramid that makes it simpler, easier to train, and capable of leveraging emotions to produce facial expressions. Our code and pretrained models will be available at: <span><span>https://github.com/verlab/empowering-sign-language</span><svg><path></path></svg></span>.</p></div>","PeriodicalId":50628,"journal":{"name":"Computers & Graphics-Uk","volume":"124 ","pages":"Article 104065"},"PeriodicalIF":2.8000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Empowering sign language communication: Integrating sentiment and semantics for facial expression synthesis\",\"authors\":\"Rafael V. Azevedo , Thiago M. Coutinho , João P. Ferreira , Thiago L. Gomes , Erickson R. Nascimento\",\"doi\":\"10.1016/j.cag.2024.104065\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Translating written sentences from oral languages to a sequence of manual and non-manual gestures plays a crucial role in building a more inclusive society for deaf and hard-of-hearing people. Facial expressions (non-manual), in particular, are responsible for encoding the grammar of the sentence to be spoken, applying punctuation, pronouns, or emphasizing signs. These non-manual gestures are closely related to the semantics of the sentence being spoken and also to the utterance of the speaker’s emotions. However, most Sign Language Production (SLP) approaches are centered on synthesizing manual gestures and do not focus on modeling the speaker’s expression. This paper introduces a new method focused in synthesizing facial expressions for sign language. Our goal is to improve sign language production by integrating sentiment information in facial expression generation. The approach leverages a sentence’s sentiment and semantic features to sample from a meaningful representation space, integrating the bias of the non-manual components into the sign language production process. To evaluate our method, we extend the Fréchet gesture distance (FGD) and propose a new metric called Fréchet Expression Distance (FED) and apply an extensive set of metrics to assess the quality of specific regions of the face. The experimental results showed that our method achieved state of the art, being superior to the competitors on How2Sign and PHOENIX14T datasets. Moreover, our architecture is based on a carefully designed graph pyramid that makes it simpler, easier to train, and capable of leveraging emotions to produce facial expressions. Our code and pretrained models will be available at: <span><span>https://github.com/verlab/empowering-sign-language</span><svg><path></path></svg></span>.</p></div>\",\"PeriodicalId\":50628,\"journal\":{\"name\":\"Computers & Graphics-Uk\",\"volume\":\"124 \",\"pages\":\"Article 104065\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-11-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computers & Graphics-Uk\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0097849324002000\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/9/3 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers & Graphics-Uk","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0097849324002000","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/3 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
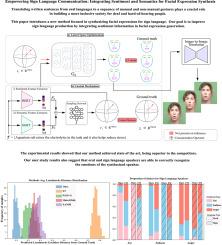
Empowering sign language communication: Integrating sentiment and semantics for facial expression synthesis
Translating written sentences from oral languages to a sequence of manual and non-manual gestures plays a crucial role in building a more inclusive society for deaf and hard-of-hearing people. Facial expressions (non-manual), in particular, are responsible for encoding the grammar of the sentence to be spoken, applying punctuation, pronouns, or emphasizing signs. These non-manual gestures are closely related to the semantics of the sentence being spoken and also to the utterance of the speaker’s emotions. However, most Sign Language Production (SLP) approaches are centered on synthesizing manual gestures and do not focus on modeling the speaker’s expression. This paper introduces a new method focused in synthesizing facial expressions for sign language. Our goal is to improve sign language production by integrating sentiment information in facial expression generation. The approach leverages a sentence’s sentiment and semantic features to sample from a meaningful representation space, integrating the bias of the non-manual components into the sign language production process. To evaluate our method, we extend the Fréchet gesture distance (FGD) and propose a new metric called Fréchet Expression Distance (FED) and apply an extensive set of metrics to assess the quality of specific regions of the face. The experimental results showed that our method achieved state of the art, being superior to the competitors on How2Sign and PHOENIX14T datasets. Moreover, our architecture is based on a carefully designed graph pyramid that makes it simpler, easier to train, and capable of leveraging emotions to produce facial expressions. Our code and pretrained models will be available at: https://github.com/verlab/empowering-sign-language.
期刊介绍:
Computers & Graphics is dedicated to disseminate information on research and applications of computer graphics (CG) techniques. The journal encourages articles on:
1. Research and applications of interactive computer graphics. We are particularly interested in novel interaction techniques and applications of CG to problem domains.
2. State-of-the-art papers on late-breaking, cutting-edge research on CG.
3. Information on innovative uses of graphics principles and technologies.
4. Tutorial papers on both teaching CG principles and innovative uses of CG in education.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
