{"title":"用于无监督车辆再识别的 SAM 驱动 MAE 预训练和背景感知元学习","authors":"Dong Wang, Qi Wang, Weidong Min, Di Gai, Qing Han, Longfei Li, Yuhan Geng","doi":"10.1007/s41095-024-0424-2","DOIUrl":null,"url":null,"abstract":"<p>Distinguishing identity-unrelated background information from discriminative identity information poses a challenge in unsupervised vehicle re-identification (Re-ID). Re-ID models suffer from varying degrees of background interference caused by continuous scene variations. The recently proposed segment anything model (SAM) has demonstrated exceptional performance in zero-shot segmentation tasks. The combination of SAM and vehicle Re-ID models can achieve efficient separation of vehicle identity and background information. This paper proposes a method that combines SAM-driven mask autoencoder (MAE) pre-training and background-aware meta-learning for unsupervised vehicle Re-ID. The method consists of three sub-modules. First, the segmentation capacity of SAM is utilized to separate the vehicle identity region from the background. SAM cannot be robustly employed in exceptional situations, such as those with ambiguity or occlusion. Thus, in vehicle Re-ID downstream tasks, a spatially-constrained vehicle background segmentation method is presented to obtain accurate background segmentation results. Second, SAM-driven MAE pre-training utilizes the aforementioned segmentation results to select patches belonging to the vehicle and to mask other patches, allowing MAE to learn identity-sensitive features in a self-supervised manner. Finally, we present a background-aware meta-learning method to fit varying degrees of background interference in different scenarios by combining different background region ratios. Our experiments demonstrate that the proposed method has state-of-the-art performance in reducing background interference variations.\n</p>","PeriodicalId":37301,"journal":{"name":"Computational Visual Media","volume":"61 1","pages":""},"PeriodicalIF":18.3000,"publicationDate":"2024-08-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"SAM-driven MAE pre-training and background-aware meta-learning for unsupervised vehicle re-identification\",\"authors\":\"Dong Wang, Qi Wang, Weidong Min, Di Gai, Qing Han, Longfei Li, Yuhan Geng\",\"doi\":\"10.1007/s41095-024-0424-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Distinguishing identity-unrelated background information from discriminative identity information poses a challenge in unsupervised vehicle re-identification (Re-ID). Re-ID models suffer from varying degrees of background interference caused by continuous scene variations. The recently proposed segment anything model (SAM) has demonstrated exceptional performance in zero-shot segmentation tasks. The combination of SAM and vehicle Re-ID models can achieve efficient separation of vehicle identity and background information. This paper proposes a method that combines SAM-driven mask autoencoder (MAE) pre-training and background-aware meta-learning for unsupervised vehicle Re-ID. The method consists of three sub-modules. First, the segmentation capacity of SAM is utilized to separate the vehicle identity region from the background. SAM cannot be robustly employed in exceptional situations, such as those with ambiguity or occlusion. Thus, in vehicle Re-ID downstream tasks, a spatially-constrained vehicle background segmentation method is presented to obtain accurate background segmentation results. Second, SAM-driven MAE pre-training utilizes the aforementioned segmentation results to select patches belonging to the vehicle and to mask other patches, allowing MAE to learn identity-sensitive features in a self-supervised manner. Finally, we present a background-aware meta-learning method to fit varying degrees of background interference in different scenarios by combining different background region ratios. Our experiments demonstrate that the proposed method has state-of-the-art performance in reducing background interference variations.\\n</p>\",\"PeriodicalId\":37301,\"journal\":{\"name\":\"Computational Visual Media\",\"volume\":\"61 1\",\"pages\":\"\"},\"PeriodicalIF\":18.3000,\"publicationDate\":\"2024-08-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Visual Media\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s41095-024-0424-2\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Visual Media","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s41095-024-0424-2","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
摘要
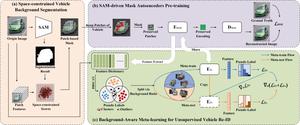
在无监督车辆再识别(Re-ID)中,如何区分与身份无关的背景信息和具有区分性的身份信息是一项挑战。再识别模型会受到连续场景变化造成的不同程度的背景干扰。最近提出的任何分割模型(SAM)在零镜头分割任务中表现出了卓越的性能。将 SAM 模型与车辆再识别模型相结合,可以实现车辆身份和背景信息的有效分离。本文提出了一种结合 SAM 驱动的掩码自动编码器(MAE)预训练和背景感知元学习的方法,用于无监督车辆再识别。该方法由三个子模块组成。首先,利用 SAM 的分割能力将车辆识别区域从背景中分离出来。在特殊情况下,例如模糊或遮挡的情况下,无法稳健地使用 SAM。因此,在车辆再识别下游任务中,提出了一种空间受限的车辆背景分割方法,以获得精确的背景分割结果。其次,SAM 驱动的 MAE 预训练利用上述分割结果选择属于车辆的斑块并屏蔽其他斑块,从而使 MAE 能够以自我监督的方式学习对身份敏感的特征。最后,我们提出了一种背景感知元学习方法,通过结合不同的背景区域比例来适应不同场景下不同程度的背景干扰。我们的实验证明,所提出的方法在减少背景干扰变化方面具有最先进的性能。
SAM-driven MAE pre-training and background-aware meta-learning for unsupervised vehicle re-identification
Distinguishing identity-unrelated background information from discriminative identity information poses a challenge in unsupervised vehicle re-identification (Re-ID). Re-ID models suffer from varying degrees of background interference caused by continuous scene variations. The recently proposed segment anything model (SAM) has demonstrated exceptional performance in zero-shot segmentation tasks. The combination of SAM and vehicle Re-ID models can achieve efficient separation of vehicle identity and background information. This paper proposes a method that combines SAM-driven mask autoencoder (MAE) pre-training and background-aware meta-learning for unsupervised vehicle Re-ID. The method consists of three sub-modules. First, the segmentation capacity of SAM is utilized to separate the vehicle identity region from the background. SAM cannot be robustly employed in exceptional situations, such as those with ambiguity or occlusion. Thus, in vehicle Re-ID downstream tasks, a spatially-constrained vehicle background segmentation method is presented to obtain accurate background segmentation results. Second, SAM-driven MAE pre-training utilizes the aforementioned segmentation results to select patches belonging to the vehicle and to mask other patches, allowing MAE to learn identity-sensitive features in a self-supervised manner. Finally, we present a background-aware meta-learning method to fit varying degrees of background interference in different scenarios by combining different background region ratios. Our experiments demonstrate that the proposed method has state-of-the-art performance in reducing background interference variations.
期刊介绍:
Computational Visual Media is a peer-reviewed open access journal. It publishes original high-quality research papers and significant review articles on novel ideas, methods, and systems relevant to visual media.
Computational Visual Media publishes articles that focus on, but are not limited to, the following areas:
• Editing and composition of visual media
• Geometric computing for images and video
• Geometry modeling and processing
• Machine learning for visual media
• Physically based animation
• Realistic rendering
• Recognition and understanding of visual media
• Visual computing for robotics
• Visualization and visual analytics
Other interdisciplinary research into visual media that combines aspects of computer graphics, computer vision, image and video processing, geometric computing, and machine learning is also within the journal''s scope.
This is an open access journal, published quarterly by Tsinghua University Press and Springer. The open access fees (article-processing charges) are fully sponsored by Tsinghua University, China. Authors can publish in the journal without any additional charges.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
