{"title":"通过路径调整提高对抗性示例的可移植性","authors":"Tianyu Li, Xiaoyu Li, Wuping Ke, Xuwei Tian, Desheng Zheng, Chao Lu","doi":"10.1007/s10489-024-05820-4","DOIUrl":null,"url":null,"abstract":"<p>Adversarial attacks pose a significant threat to real-world applications based on deep neural networks (DNNs), especially in security-critical applications. Research has shown that adversarial examples (AEs) generated on a surrogate model can also succeed on a target model, which is known as transferability. Feature-level transfer-based attacks improve the transferability of AEs by disrupting intermediate features. They target the intermediate layer of the model and use feature importance metrics to find these features. However, current methods overfit feature importance metrics to surrogate models, which results in poor sharing of the importance metrics across models and insufficient destruction of deep features. This work demonstrates the trade-off between feature importance metrics and feature corruption generalization, and categorizes feature destructive causes of misclassification. This work proposes a generative framework named PTNAA to guide the destruction of deep features across models, thus improving the transferability of AEs. Specifically, the method introduces path methods into integrated gradients. It selects path functions using only a priori knowledge and approximates neuron attribution using nonuniform sampling. In addition, it measures neurons based on the attribution results and performs feature-level attacks to remove inherent features of the image. Extensive experiments demonstrate the effectiveness of the proposed method. The code is available at https://github.com/lounwb/PTNAA.</p>","PeriodicalId":8041,"journal":{"name":"Applied Intelligence","volume":"54 23","pages":"12194 - 12214"},"PeriodicalIF":3.5000,"publicationDate":"2024-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Improving the transferability of adversarial examples with path tuning\",\"authors\":\"Tianyu Li, Xiaoyu Li, Wuping Ke, Xuwei Tian, Desheng Zheng, Chao Lu\",\"doi\":\"10.1007/s10489-024-05820-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Adversarial attacks pose a significant threat to real-world applications based on deep neural networks (DNNs), especially in security-critical applications. Research has shown that adversarial examples (AEs) generated on a surrogate model can also succeed on a target model, which is known as transferability. Feature-level transfer-based attacks improve the transferability of AEs by disrupting intermediate features. They target the intermediate layer of the model and use feature importance metrics to find these features. However, current methods overfit feature importance metrics to surrogate models, which results in poor sharing of the importance metrics across models and insufficient destruction of deep features. This work demonstrates the trade-off between feature importance metrics and feature corruption generalization, and categorizes feature destructive causes of misclassification. This work proposes a generative framework named PTNAA to guide the destruction of deep features across models, thus improving the transferability of AEs. Specifically, the method introduces path methods into integrated gradients. It selects path functions using only a priori knowledge and approximates neuron attribution using nonuniform sampling. In addition, it measures neurons based on the attribution results and performs feature-level attacks to remove inherent features of the image. Extensive experiments demonstrate the effectiveness of the proposed method. The code is available at https://github.com/lounwb/PTNAA.</p>\",\"PeriodicalId\":8041,\"journal\":{\"name\":\"Applied Intelligence\",\"volume\":\"54 23\",\"pages\":\"12194 - 12214\"},\"PeriodicalIF\":3.5000,\"publicationDate\":\"2024-09-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Applied Intelligence\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10489-024-05820-4\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applied Intelligence","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10489-024-05820-4","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Improving the transferability of adversarial examples with path tuning
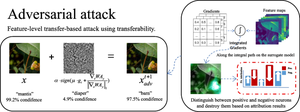
Adversarial attacks pose a significant threat to real-world applications based on deep neural networks (DNNs), especially in security-critical applications. Research has shown that adversarial examples (AEs) generated on a surrogate model can also succeed on a target model, which is known as transferability. Feature-level transfer-based attacks improve the transferability of AEs by disrupting intermediate features. They target the intermediate layer of the model and use feature importance metrics to find these features. However, current methods overfit feature importance metrics to surrogate models, which results in poor sharing of the importance metrics across models and insufficient destruction of deep features. This work demonstrates the trade-off between feature importance metrics and feature corruption generalization, and categorizes feature destructive causes of misclassification. This work proposes a generative framework named PTNAA to guide the destruction of deep features across models, thus improving the transferability of AEs. Specifically, the method introduces path methods into integrated gradients. It selects path functions using only a priori knowledge and approximates neuron attribution using nonuniform sampling. In addition, it measures neurons based on the attribution results and performs feature-level attacks to remove inherent features of the image. Extensive experiments demonstrate the effectiveness of the proposed method. The code is available at https://github.com/lounwb/PTNAA.
期刊介绍:
With a focus on research in artificial intelligence and neural networks, this journal addresses issues involving solutions of real-life manufacturing, defense, management, government and industrial problems which are too complex to be solved through conventional approaches and require the simulation of intelligent thought processes, heuristics, applications of knowledge, and distributed and parallel processing. The integration of these multiple approaches in solving complex problems is of particular importance.
The journal presents new and original research and technological developments, addressing real and complex issues applicable to difficult problems. It provides a medium for exchanging scientific research and technological achievements accomplished by the international community.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
