Isabella Catharina Wiest, Dyke Ferber, Jiefu Zhu, Marko van Treeck, Sonja K. Meyer, Radhika Juglan, Zunamys I. Carrero, Daniel Paech, Jens Kleesiek, Matthias P. Ebert, Daniel Truhn, Jakob Nikolas Kather
{"title":"用于结构化医疗信息检索的隐私保护大型语言模型。","authors":"Isabella Catharina Wiest, Dyke Ferber, Jiefu Zhu, Marko van Treeck, Sonja K. Meyer, Radhika Juglan, Zunamys I. Carrero, Daniel Paech, Jens Kleesiek, Matthias P. Ebert, Daniel Truhn, Jakob Nikolas Kather","doi":"10.1038/s41746-024-01233-2","DOIUrl":null,"url":null,"abstract":"Most clinical information is encoded as free text, not accessible for quantitative analysis. This study presents an open-source pipeline using the local large language model (LLM) “Llama 2” to extract quantitative information from clinical text and evaluates its performance in identifying features of decompensated liver cirrhosis. The LLM identified five key clinical features in a zero- and one-shot manner from 500 patient medical histories in the MIMIC IV dataset. We compared LLMs of three sizes and various prompt engineering approaches, with predictions compared against ground truth from three blinded medical experts. Our pipeline achieved high accuracy, detecting liver cirrhosis with 100% sensitivity and 96% specificity. High sensitivities and specificities were also yielded for detecting ascites (95%, 95%), confusion (76%, 94%), abdominal pain (84%, 97%), and shortness of breath (87%, 97%) using the 70 billion parameter model, which outperformed smaller versions. Our study successfully demonstrates the capability of locally deployed LLMs to extract clinical information from free text with low hardware requirements.","PeriodicalId":19349,"journal":{"name":"NPJ Digital Medicine","volume":" ","pages":"1-9"},"PeriodicalIF":15.1000,"publicationDate":"2024-09-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s41746-024-01233-2.pdf","citationCount":"0","resultStr":"{\"title\":\"Privacy-preserving large language models for structured medical information retrieval\",\"authors\":\"Isabella Catharina Wiest, Dyke Ferber, Jiefu Zhu, Marko van Treeck, Sonja K. Meyer, Radhika Juglan, Zunamys I. Carrero, Daniel Paech, Jens Kleesiek, Matthias P. Ebert, Daniel Truhn, Jakob Nikolas Kather\",\"doi\":\"10.1038/s41746-024-01233-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Most clinical information is encoded as free text, not accessible for quantitative analysis. This study presents an open-source pipeline using the local large language model (LLM) “Llama 2” to extract quantitative information from clinical text and evaluates its performance in identifying features of decompensated liver cirrhosis. The LLM identified five key clinical features in a zero- and one-shot manner from 500 patient medical histories in the MIMIC IV dataset. We compared LLMs of three sizes and various prompt engineering approaches, with predictions compared against ground truth from three blinded medical experts. Our pipeline achieved high accuracy, detecting liver cirrhosis with 100% sensitivity and 96% specificity. High sensitivities and specificities were also yielded for detecting ascites (95%, 95%), confusion (76%, 94%), abdominal pain (84%, 97%), and shortness of breath (87%, 97%) using the 70 billion parameter model, which outperformed smaller versions. Our study successfully demonstrates the capability of locally deployed LLMs to extract clinical information from free text with low hardware requirements.\",\"PeriodicalId\":19349,\"journal\":{\"name\":\"NPJ Digital Medicine\",\"volume\":\" \",\"pages\":\"1-9\"},\"PeriodicalIF\":15.1000,\"publicationDate\":\"2024-09-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.com/articles/s41746-024-01233-2.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"NPJ Digital Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.nature.com/articles/s41746-024-01233-2\",\"RegionNum\":1,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"NPJ Digital Medicine","FirstCategoryId":"3","ListUrlMain":"https://www.nature.com/articles/s41746-024-01233-2","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Privacy-preserving large language models for structured medical information retrieval
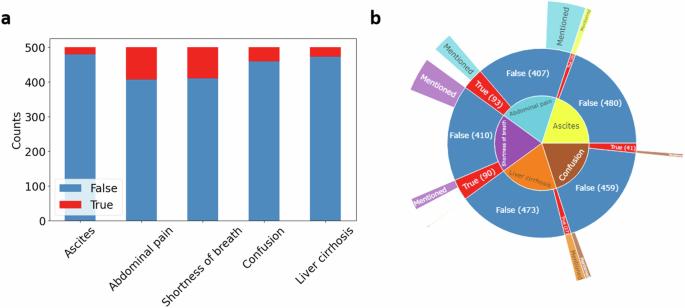
Most clinical information is encoded as free text, not accessible for quantitative analysis. This study presents an open-source pipeline using the local large language model (LLM) “Llama 2” to extract quantitative information from clinical text and evaluates its performance in identifying features of decompensated liver cirrhosis. The LLM identified five key clinical features in a zero- and one-shot manner from 500 patient medical histories in the MIMIC IV dataset. We compared LLMs of three sizes and various prompt engineering approaches, with predictions compared against ground truth from three blinded medical experts. Our pipeline achieved high accuracy, detecting liver cirrhosis with 100% sensitivity and 96% specificity. High sensitivities and specificities were also yielded for detecting ascites (95%, 95%), confusion (76%, 94%), abdominal pain (84%, 97%), and shortness of breath (87%, 97%) using the 70 billion parameter model, which outperformed smaller versions. Our study successfully demonstrates the capability of locally deployed LLMs to extract clinical information from free text with low hardware requirements.
期刊介绍:
npj Digital Medicine is an online open-access journal that focuses on publishing peer-reviewed research in the field of digital medicine. The journal covers various aspects of digital medicine, including the application and implementation of digital and mobile technologies in clinical settings, virtual healthcare, and the use of artificial intelligence and informatics.
The primary goal of the journal is to support innovation and the advancement of healthcare through the integration of new digital and mobile technologies. When determining if a manuscript is suitable for publication, the journal considers four important criteria: novelty, clinical relevance, scientific rigor, and digital innovation.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
