{"title":"用于儿科胸部 X 光图像分类的噪声诱导模式特定借口学习。","authors":"Sivaramakrishnan Rajaraman, Zhaohui Liang, Zhiyun Xue, Sameer Antani","doi":"10.3389/frai.2024.1419638","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Deep learning (DL) has significantly advanced medical image classification. However, it often relies on transfer learning (TL) from models pretrained on large, generic non-medical image datasets like ImageNet. Conversely, medical images possess unique visual characteristics that such general models may not adequately capture.</p><p><strong>Methods: </strong>This study examines the effectiveness of modality-specific pretext learning strengthened by image denoising and deblurring in enhancing the classification of pediatric chest X-ray (CXR) images into those exhibiting no findings, i.e., normal lungs, or with cardiopulmonary disease manifestations. Specifically, we use a <i>VGG-16-Sharp-U-Net</i> architecture and leverage its encoder in conjunction with a classification head to distinguish normal from abnormal pediatric CXR findings. We benchmark this performance against the traditional TL approach, <i>viz.</i>, the VGG-16 model pretrained only on ImageNet. Measures used for performance evaluation are balanced accuracy, sensitivity, specificity, F-score, Matthew's Correlation Coefficient (MCC), Kappa statistic, and Youden's index.</p><p><strong>Results: </strong>Our findings reveal that models developed from CXR modality-specific pretext encoders substantially outperform the ImageNet-only pretrained model, <i>viz.</i>, Baseline, and achieve significantly higher sensitivity (<i>p</i> < 0.05) with marked improvements in balanced accuracy, F-score, MCC, Kappa statistic, and Youden's index. A novel attention-based fuzzy ensemble of the pretext-learned models further improves performance across these metrics (Balanced accuracy: 0.6376; Sensitivity: 0.4991; F-score: 0.5102; MCC: 0.2783; Kappa: 0.2782, and Youden's index:0.2751), compared to Baseline (Balanced accuracy: 0.5654; Sensitivity: 0.1983; F-score: 0.2977; MCC: 0.1998; Kappa: 0.1599, and Youden's index:0.1327).</p><p><strong>Discussion: </strong>The superior results of CXR modality-specific pretext learning and their ensemble underscore its potential as a viable alternative to conventional ImageNet pretraining for medical image classification. Results from this study promote further exploration of medical modality-specific TL techniques in the development of DL models for various medical imaging applications.</p>","PeriodicalId":33315,"journal":{"name":"Frontiers in Artificial Intelligence","volume":"7 ","pages":"1419638"},"PeriodicalIF":4.7000,"publicationDate":"2024-09-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11410760/pdf/","citationCount":"0","resultStr":"{\"title\":\"Noise-induced modality-specific pretext learning for pediatric chest X-ray image classification.\",\"authors\":\"Sivaramakrishnan Rajaraman, Zhaohui Liang, Zhiyun Xue, Sameer Antani\",\"doi\":\"10.3389/frai.2024.1419638\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Deep learning (DL) has significantly advanced medical image classification. However, it often relies on transfer learning (TL) from models pretrained on large, generic non-medical image datasets like ImageNet. Conversely, medical images possess unique visual characteristics that such general models may not adequately capture.</p><p><strong>Methods: </strong>This study examines the effectiveness of modality-specific pretext learning strengthened by image denoising and deblurring in enhancing the classification of pediatric chest X-ray (CXR) images into those exhibiting no findings, i.e., normal lungs, or with cardiopulmonary disease manifestations. Specifically, we use a <i>VGG-16-Sharp-U-Net</i> architecture and leverage its encoder in conjunction with a classification head to distinguish normal from abnormal pediatric CXR findings. We benchmark this performance against the traditional TL approach, <i>viz.</i>, the VGG-16 model pretrained only on ImageNet. Measures used for performance evaluation are balanced accuracy, sensitivity, specificity, F-score, Matthew's Correlation Coefficient (MCC), Kappa statistic, and Youden's index.</p><p><strong>Results: </strong>Our findings reveal that models developed from CXR modality-specific pretext encoders substantially outperform the ImageNet-only pretrained model, <i>viz.</i>, Baseline, and achieve significantly higher sensitivity (<i>p</i> < 0.05) with marked improvements in balanced accuracy, F-score, MCC, Kappa statistic, and Youden's index. A novel attention-based fuzzy ensemble of the pretext-learned models further improves performance across these metrics (Balanced accuracy: 0.6376; Sensitivity: 0.4991; F-score: 0.5102; MCC: 0.2783; Kappa: 0.2782, and Youden's index:0.2751), compared to Baseline (Balanced accuracy: 0.5654; Sensitivity: 0.1983; F-score: 0.2977; MCC: 0.1998; Kappa: 0.1599, and Youden's index:0.1327).</p><p><strong>Discussion: </strong>The superior results of CXR modality-specific pretext learning and their ensemble underscore its potential as a viable alternative to conventional ImageNet pretraining for medical image classification. Results from this study promote further exploration of medical modality-specific TL techniques in the development of DL models for various medical imaging applications.</p>\",\"PeriodicalId\":33315,\"journal\":{\"name\":\"Frontiers in Artificial Intelligence\",\"volume\":\"7 \",\"pages\":\"1419638\"},\"PeriodicalIF\":4.7000,\"publicationDate\":\"2024-09-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11410760/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Artificial Intelligence\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/frai.2024.1419638\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Artificial Intelligence","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/frai.2024.1419638","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Noise-induced modality-specific pretext learning for pediatric chest X-ray image classification.
Introduction: Deep learning (DL) has significantly advanced medical image classification. However, it often relies on transfer learning (TL) from models pretrained on large, generic non-medical image datasets like ImageNet. Conversely, medical images possess unique visual characteristics that such general models may not adequately capture.
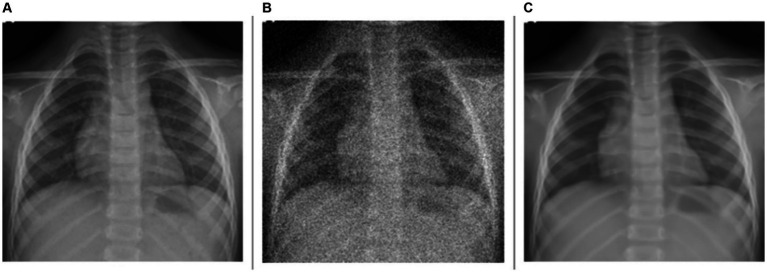
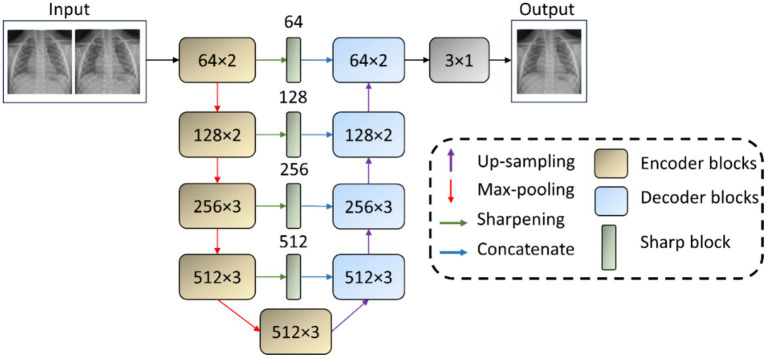
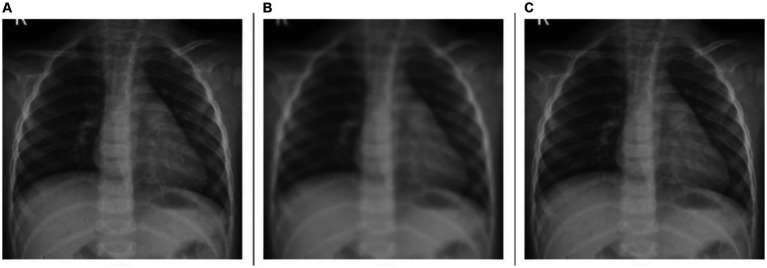
Methods: This study examines the effectiveness of modality-specific pretext learning strengthened by image denoising and deblurring in enhancing the classification of pediatric chest X-ray (CXR) images into those exhibiting no findings, i.e., normal lungs, or with cardiopulmonary disease manifestations. Specifically, we use a VGG-16-Sharp-U-Net architecture and leverage its encoder in conjunction with a classification head to distinguish normal from abnormal pediatric CXR findings. We benchmark this performance against the traditional TL approach, viz., the VGG-16 model pretrained only on ImageNet. Measures used for performance evaluation are balanced accuracy, sensitivity, specificity, F-score, Matthew's Correlation Coefficient (MCC), Kappa statistic, and Youden's index.
Results: Our findings reveal that models developed from CXR modality-specific pretext encoders substantially outperform the ImageNet-only pretrained model, viz., Baseline, and achieve significantly higher sensitivity (p < 0.05) with marked improvements in balanced accuracy, F-score, MCC, Kappa statistic, and Youden's index. A novel attention-based fuzzy ensemble of the pretext-learned models further improves performance across these metrics (Balanced accuracy: 0.6376; Sensitivity: 0.4991; F-score: 0.5102; MCC: 0.2783; Kappa: 0.2782, and Youden's index:0.2751), compared to Baseline (Balanced accuracy: 0.5654; Sensitivity: 0.1983; F-score: 0.2977; MCC: 0.1998; Kappa: 0.1599, and Youden's index:0.1327).
Discussion: The superior results of CXR modality-specific pretext learning and their ensemble underscore its potential as a viable alternative to conventional ImageNet pretraining for medical image classification. Results from this study promote further exploration of medical modality-specific TL techniques in the development of DL models for various medical imaging applications.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
