Rachid Riad, Martin Denais, Marc de Gennes, Adrien Lesage, Vincent Oustric, Xuan Nga Cao, Stéphane Mouchabac, Alexis Bourla
{"title":"用于抑郁、焦虑、失眠和疲劳风险检测的自动语音分析:算法开发与验证研究。","authors":"Rachid Riad, Martin Denais, Marc de Gennes, Adrien Lesage, Vincent Oustric, Xuan Nga Cao, Stéphane Mouchabac, Alexis Bourla","doi":"10.2196/58572","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>While speech analysis holds promise for mental health assessment, research often focuses on single symptoms, despite symptom co-occurrences and interactions. In addition, predictive models in mental health do not properly assess the limitations of speech-based systems, such as uncertainty, or fairness for a safe clinical deployment.</p><p><strong>Objective: </strong>We investigated the predictive potential of mobile-collected speech data for detecting and estimating depression, anxiety, fatigue, and insomnia, focusing on other factors than mere accuracy, in the general population.</p><p><strong>Methods: </strong>We included 865 healthy adults and recorded their answers regarding their perceived mental and sleep states. We asked how they felt and if they had slept well lately. Clinically validated questionnaires measuring depression, anxiety, insomnia, and fatigue severity were also used. We developed a novel speech and machine learning pipeline involving voice activity detection, feature extraction, and model training. We automatically modeled speech with pretrained deep learning models that were pretrained on a large, open, and free database, and we selected the best one on the validation set. Based on the best speech modeling approach, clinical threshold detection, individual score prediction, model uncertainty estimation, and performance fairness across demographics (age, sex, and education) were evaluated. We used a train-validation-test split for all evaluations: to develop our models, select the best ones, and assess the generalizability of held-out data.</p><p><strong>Results: </strong>The best model was Whisper M with a max pooling and oversampling method. Our methods achieved good detection performance for all symptoms, depression (Patient Health Questionnaire-9: area under the curve [AUC]=0.76; F<sub>1</sub>-score=0.49 and Beck Depression Inventory: AUC=0.78; F<sub>1</sub>-score=0.65), anxiety (Generalized Anxiety Disorder 7-item scale: AUC=0.77; F<sub>1</sub>-score=0.50), insomnia (Athens Insomnia Scale: AUC=0.73; F<sub>1</sub>-score=0.62), and fatigue (Multidimensional Fatigue Inventory total score: AUC=0.68; F<sub>1</sub>-score=0.88). The system performed well when it needed to abstain from making predictions, as demonstrated by low abstention rates in depression detection with the Beck Depression Inventory and fatigue, with risk-coverage AUCs below 0.4. Individual symptom scores were accurately predicted (correlations were all significant with Pearson strengths between 0.31 and 0.49). Fairness analysis revealed that models were consistent for sex (average disparity ratio [DR] 0.86, SD 0.13), to a lesser extent for education level (average DR 0.47, SD 0.30), and worse for age groups (average DR 0.33, SD 0.30).</p><p><strong>Conclusions: </strong>This study demonstrates the potential of speech-based systems for multifaceted mental health assessment in the general population, not only for detecting clinical thresholds but also for estimating their severity. Addressing fairness and incorporating uncertainty estimation with selective classification are key contributions that can enhance the clinical utility and responsible implementation of such systems.</p>","PeriodicalId":16337,"journal":{"name":"Journal of Medical Internet Research","volume":" ","pages":"e58572"},"PeriodicalIF":6.0000,"publicationDate":"2024-10-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11565087/pdf/","citationCount":"0","resultStr":"{\"title\":\"Automated Speech Analysis for Risk Detection of Depression, Anxiety, Insomnia, and Fatigue: Algorithm Development and Validation Study.\",\"authors\":\"Rachid Riad, Martin Denais, Marc de Gennes, Adrien Lesage, Vincent Oustric, Xuan Nga Cao, Stéphane Mouchabac, Alexis Bourla\",\"doi\":\"10.2196/58572\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>While speech analysis holds promise for mental health assessment, research often focuses on single symptoms, despite symptom co-occurrences and interactions. In addition, predictive models in mental health do not properly assess the limitations of speech-based systems, such as uncertainty, or fairness for a safe clinical deployment.</p><p><strong>Objective: </strong>We investigated the predictive potential of mobile-collected speech data for detecting and estimating depression, anxiety, fatigue, and insomnia, focusing on other factors than mere accuracy, in the general population.</p><p><strong>Methods: </strong>We included 865 healthy adults and recorded their answers regarding their perceived mental and sleep states. We asked how they felt and if they had slept well lately. Clinically validated questionnaires measuring depression, anxiety, insomnia, and fatigue severity were also used. We developed a novel speech and machine learning pipeline involving voice activity detection, feature extraction, and model training. We automatically modeled speech with pretrained deep learning models that were pretrained on a large, open, and free database, and we selected the best one on the validation set. Based on the best speech modeling approach, clinical threshold detection, individual score prediction, model uncertainty estimation, and performance fairness across demographics (age, sex, and education) were evaluated. We used a train-validation-test split for all evaluations: to develop our models, select the best ones, and assess the generalizability of held-out data.</p><p><strong>Results: </strong>The best model was Whisper M with a max pooling and oversampling method. Our methods achieved good detection performance for all symptoms, depression (Patient Health Questionnaire-9: area under the curve [AUC]=0.76; F<sub>1</sub>-score=0.49 and Beck Depression Inventory: AUC=0.78; F<sub>1</sub>-score=0.65), anxiety (Generalized Anxiety Disorder 7-item scale: AUC=0.77; F<sub>1</sub>-score=0.50), insomnia (Athens Insomnia Scale: AUC=0.73; F<sub>1</sub>-score=0.62), and fatigue (Multidimensional Fatigue Inventory total score: AUC=0.68; F<sub>1</sub>-score=0.88). The system performed well when it needed to abstain from making predictions, as demonstrated by low abstention rates in depression detection with the Beck Depression Inventory and fatigue, with risk-coverage AUCs below 0.4. Individual symptom scores were accurately predicted (correlations were all significant with Pearson strengths between 0.31 and 0.49). Fairness analysis revealed that models were consistent for sex (average disparity ratio [DR] 0.86, SD 0.13), to a lesser extent for education level (average DR 0.47, SD 0.30), and worse for age groups (average DR 0.33, SD 0.30).</p><p><strong>Conclusions: </strong>This study demonstrates the potential of speech-based systems for multifaceted mental health assessment in the general population, not only for detecting clinical thresholds but also for estimating their severity. Addressing fairness and incorporating uncertainty estimation with selective classification are key contributions that can enhance the clinical utility and responsible implementation of such systems.</p>\",\"PeriodicalId\":16337,\"journal\":{\"name\":\"Journal of Medical Internet Research\",\"volume\":\" \",\"pages\":\"e58572\"},\"PeriodicalIF\":6.0000,\"publicationDate\":\"2024-10-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11565087/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Medical Internet Research\",\"FirstCategoryId\":\"88\",\"ListUrlMain\":\"https://doi.org/10.2196/58572\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Medical Internet Research","FirstCategoryId":"88","ListUrlMain":"https://doi.org/10.2196/58572","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Automated Speech Analysis for Risk Detection of Depression, Anxiety, Insomnia, and Fatigue: Algorithm Development and Validation Study.
Background: While speech analysis holds promise for mental health assessment, research often focuses on single symptoms, despite symptom co-occurrences and interactions. In addition, predictive models in mental health do not properly assess the limitations of speech-based systems, such as uncertainty, or fairness for a safe clinical deployment.
Objective: We investigated the predictive potential of mobile-collected speech data for detecting and estimating depression, anxiety, fatigue, and insomnia, focusing on other factors than mere accuracy, in the general population.
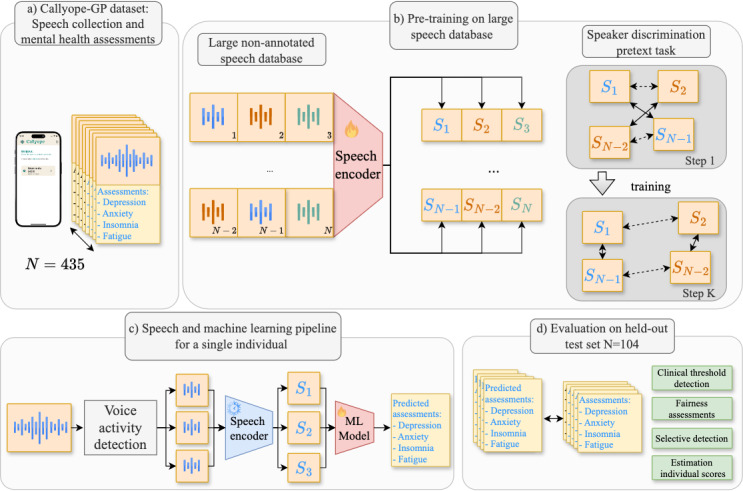
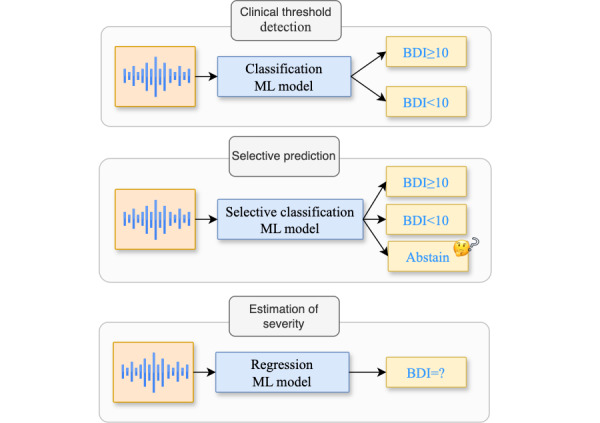
Methods: We included 865 healthy adults and recorded their answers regarding their perceived mental and sleep states. We asked how they felt and if they had slept well lately. Clinically validated questionnaires measuring depression, anxiety, insomnia, and fatigue severity were also used. We developed a novel speech and machine learning pipeline involving voice activity detection, feature extraction, and model training. We automatically modeled speech with pretrained deep learning models that were pretrained on a large, open, and free database, and we selected the best one on the validation set. Based on the best speech modeling approach, clinical threshold detection, individual score prediction, model uncertainty estimation, and performance fairness across demographics (age, sex, and education) were evaluated. We used a train-validation-test split for all evaluations: to develop our models, select the best ones, and assess the generalizability of held-out data.
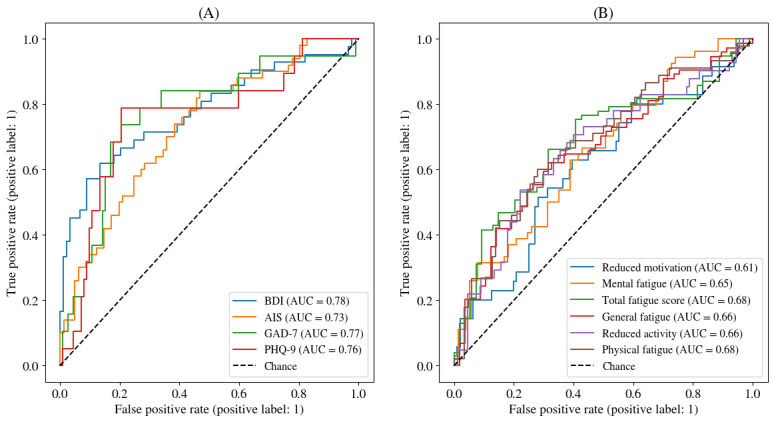
Results: The best model was Whisper M with a max pooling and oversampling method. Our methods achieved good detection performance for all symptoms, depression (Patient Health Questionnaire-9: area under the curve [AUC]=0.76; F1-score=0.49 and Beck Depression Inventory: AUC=0.78; F1-score=0.65), anxiety (Generalized Anxiety Disorder 7-item scale: AUC=0.77; F1-score=0.50), insomnia (Athens Insomnia Scale: AUC=0.73; F1-score=0.62), and fatigue (Multidimensional Fatigue Inventory total score: AUC=0.68; F1-score=0.88). The system performed well when it needed to abstain from making predictions, as demonstrated by low abstention rates in depression detection with the Beck Depression Inventory and fatigue, with risk-coverage AUCs below 0.4. Individual symptom scores were accurately predicted (correlations were all significant with Pearson strengths between 0.31 and 0.49). Fairness analysis revealed that models were consistent for sex (average disparity ratio [DR] 0.86, SD 0.13), to a lesser extent for education level (average DR 0.47, SD 0.30), and worse for age groups (average DR 0.33, SD 0.30).
Conclusions: This study demonstrates the potential of speech-based systems for multifaceted mental health assessment in the general population, not only for detecting clinical thresholds but also for estimating their severity. Addressing fairness and incorporating uncertainty estimation with selective classification are key contributions that can enhance the clinical utility and responsible implementation of such systems.
期刊介绍:
The Journal of Medical Internet Research (JMIR) is a highly respected publication in the field of health informatics and health services. With a founding date in 1999, JMIR has been a pioneer in the field for over two decades.
As a leader in the industry, the journal focuses on digital health, data science, health informatics, and emerging technologies for health, medicine, and biomedical research. It is recognized as a top publication in these disciplines, ranking in the first quartile (Q1) by Impact Factor.
Notably, JMIR holds the prestigious position of being ranked #1 on Google Scholar within the "Medical Informatics" discipline.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
