Dirk H. M. Pelt, Philippe C. Habets, Christiaan H. Vinkers, Lannie Ligthart, Catharina E. M. van Beijsterveldt, René Pool, Meike Bartels
{"title":"利用人群队列中来自暴露组和基因组的预测因子,建立幸福感机器学习预测模型","authors":"Dirk H. M. Pelt, Philippe C. Habets, Christiaan H. Vinkers, Lannie Ligthart, Catharina E. M. van Beijsterveldt, René Pool, Meike Bartels","doi":"10.1038/s44220-024-00294-2","DOIUrl":null,"url":null,"abstract":"Effective personalized well-being interventions require the ability to predict who will thrive or not, and the understanding of underlying mechanisms. Here, using longitudinal data of a large population cohort (the Netherlands Twin Register, collected 1991–2022), we aim to build machine learning prediction models for adult well-being from the exposome and genome, and identify the most predictive factors (N between 702 and 5874). The specific exposome was captured by parent and self-reports of psychosocial factors from childhood to adulthood, the genome was described by polygenic scores, and the general exposome was captured by linkage of participants’ postal codes to objective, registry-based exposures. Not the genome (R2 = −0.007 [−0.026–0.010]), but the general exposome (R2 = 0.047 [0.015–0.076]) and especially the specific exposome (R2 = 0.702 [0.637–0.753]) were predictive of well-being in an independent test set. Adding the genome (P = 0.334) and general exposome (P = 0.695) independently or jointly (P = 0.029) beyond the specific exposome did not improve prediction. Risk/protective factors such as optimism, personality, social support and neighborhood housing characteristics were most predictive. Our findings highlight the importance of longitudinal monitoring and promises of different data modalities for well-being prediction. Machine learning prediction models for adult well-being were built on longitudinal data from the Netherlands Twin Register population cohort. The exposome, but not the genome, predicted well-being in adulthood, with key factors including optimism, personality, social support and neighborhood housing characteristics.","PeriodicalId":74247,"journal":{"name":"Nature mental health","volume":"2 10","pages":"1217-1230"},"PeriodicalIF":8.7000,"publicationDate":"2024-08-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Building machine learning prediction models for well-being using predictors from the exposome and genome in a population cohort\",\"authors\":\"Dirk H. M. Pelt, Philippe C. Habets, Christiaan H. Vinkers, Lannie Ligthart, Catharina E. M. van Beijsterveldt, René Pool, Meike Bartels\",\"doi\":\"10.1038/s44220-024-00294-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Effective personalized well-being interventions require the ability to predict who will thrive or not, and the understanding of underlying mechanisms. Here, using longitudinal data of a large population cohort (the Netherlands Twin Register, collected 1991–2022), we aim to build machine learning prediction models for adult well-being from the exposome and genome, and identify the most predictive factors (N between 702 and 5874). The specific exposome was captured by parent and self-reports of psychosocial factors from childhood to adulthood, the genome was described by polygenic scores, and the general exposome was captured by linkage of participants’ postal codes to objective, registry-based exposures. Not the genome (R2 = −0.007 [−0.026–0.010]), but the general exposome (R2 = 0.047 [0.015–0.076]) and especially the specific exposome (R2 = 0.702 [0.637–0.753]) were predictive of well-being in an independent test set. Adding the genome (P = 0.334) and general exposome (P = 0.695) independently or jointly (P = 0.029) beyond the specific exposome did not improve prediction. Risk/protective factors such as optimism, personality, social support and neighborhood housing characteristics were most predictive. Our findings highlight the importance of longitudinal monitoring and promises of different data modalities for well-being prediction. Machine learning prediction models for adult well-being were built on longitudinal data from the Netherlands Twin Register population cohort. The exposome, but not the genome, predicted well-being in adulthood, with key factors including optimism, personality, social support and neighborhood housing characteristics.\",\"PeriodicalId\":74247,\"journal\":{\"name\":\"Nature mental health\",\"volume\":\"2 10\",\"pages\":\"1217-1230\"},\"PeriodicalIF\":8.7000,\"publicationDate\":\"2024-08-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature mental health\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.nature.com/articles/s44220-024-00294-2\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature mental health","FirstCategoryId":"1085","ListUrlMain":"https://www.nature.com/articles/s44220-024-00294-2","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Building machine learning prediction models for well-being using predictors from the exposome and genome in a population cohort
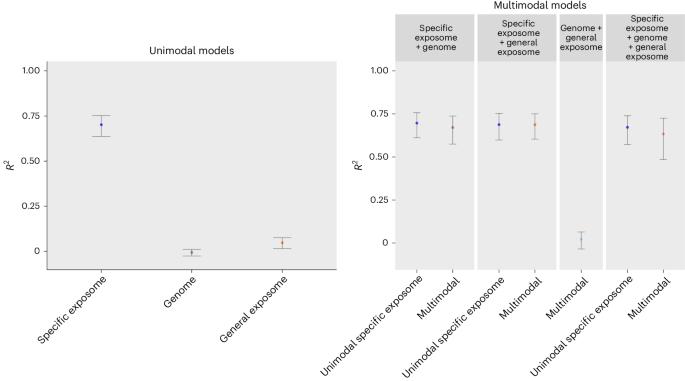
Effective personalized well-being interventions require the ability to predict who will thrive or not, and the understanding of underlying mechanisms. Here, using longitudinal data of a large population cohort (the Netherlands Twin Register, collected 1991–2022), we aim to build machine learning prediction models for adult well-being from the exposome and genome, and identify the most predictive factors (N between 702 and 5874). The specific exposome was captured by parent and self-reports of psychosocial factors from childhood to adulthood, the genome was described by polygenic scores, and the general exposome was captured by linkage of participants’ postal codes to objective, registry-based exposures. Not the genome (R2 = −0.007 [−0.026–0.010]), but the general exposome (R2 = 0.047 [0.015–0.076]) and especially the specific exposome (R2 = 0.702 [0.637–0.753]) were predictive of well-being in an independent test set. Adding the genome (P = 0.334) and general exposome (P = 0.695) independently or jointly (P = 0.029) beyond the specific exposome did not improve prediction. Risk/protective factors such as optimism, personality, social support and neighborhood housing characteristics were most predictive. Our findings highlight the importance of longitudinal monitoring and promises of different data modalities for well-being prediction. Machine learning prediction models for adult well-being were built on longitudinal data from the Netherlands Twin Register population cohort. The exposome, but not the genome, predicted well-being in adulthood, with key factors including optimism, personality, social support and neighborhood housing characteristics.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
