Matthew Azzopardi, Benjamin Ng, Abison Logeswaran, Constantinos Loizou, Ryan Chin Taw Cheong, Prasanth Gireesh, Darren Shu Jeng Ting, Yu Jeat Chong
{"title":"人工智能聊天机器人作为白内障手术患者教育材料的来源:ChatGPT-4 与 Google Bard 的对比。","authors":"Matthew Azzopardi, Benjamin Ng, Abison Logeswaran, Constantinos Loizou, Ryan Chin Taw Cheong, Prasanth Gireesh, Darren Shu Jeng Ting, Yu Jeat Chong","doi":"10.1136/bmjophth-2024-001824","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To conduct a head-to-head comparative analysis of cataract surgery patient education material generated by Chat Generative Pre-trained Transformer (ChatGPT-4) and Google Bard.</p><p><strong>Methods and analysis: </strong>98 frequently asked questions on cataract surgery in English were taken in November 2023 from 5 trustworthy online patient information resources. 59 of these were curated (20 augmented for clarity and 39 duplicates excluded) and categorised into 3 domains: condition (n=15), preparation for surgery (n=21) and recovery after surgery (n=23). They were formulated into input prompts with 'prompt engineering'. Using the Patient Education Materials Assessment Tool-Printable (PEMAT-P) Auto-Scoring Form, four ophthalmologists independently graded ChatGPT-4 and Google Bard responses. The readability of responses was evaluated using a Flesch-Kincaid calculator. Responses were also subjectively examined for any inaccurate or harmful information.</p><p><strong>Results: </strong>Google Bard had a higher mean overall Flesch-Kincaid Level (8.02) compared with ChatGPT-4 (5.75) (p<0.001), also noted across all three domains. ChatGPT-4 had a higher overall PEMAT-P understandability score (85.8%) in comparison to Google Bard (80.9%) (p<0.001), which was also noted in the 'preparation for cataract surgery' (85.2% vs 75.7%; p<0.001) and 'recovery after cataract surgery' (86.5% vs 82.3%; p=0.004) domains. There was no statistically significant difference in overall (42.5% vs 44.2%; p=0.344) or individual domain actionability scores (p>0.10). None of the generated material contained dangerous information.</p><p><strong>Conclusion: </strong>In comparison to Google Bard, ChatGPT-4 fared better overall, scoring higher on the PEMAT-P understandability scale and exhibiting more faithfulness to the prompt engineering instruction. Since input prompts might vary from real-world patient searches, follow-up studies with patient participation are required.</p>","PeriodicalId":9286,"journal":{"name":"BMJ Open Ophthalmology","volume":"9 1","pages":""},"PeriodicalIF":2.7000,"publicationDate":"2024-10-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11487885/pdf/","citationCount":"0","resultStr":"{\"title\":\"Artificial intelligence chatbots as sources of patient education material for cataract surgery: ChatGPT-4 versus Google Bard.\",\"authors\":\"Matthew Azzopardi, Benjamin Ng, Abison Logeswaran, Constantinos Loizou, Ryan Chin Taw Cheong, Prasanth Gireesh, Darren Shu Jeng Ting, Yu Jeat Chong\",\"doi\":\"10.1136/bmjophth-2024-001824\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>To conduct a head-to-head comparative analysis of cataract surgery patient education material generated by Chat Generative Pre-trained Transformer (ChatGPT-4) and Google Bard.</p><p><strong>Methods and analysis: </strong>98 frequently asked questions on cataract surgery in English were taken in November 2023 from 5 trustworthy online patient information resources. 59 of these were curated (20 augmented for clarity and 39 duplicates excluded) and categorised into 3 domains: condition (n=15), preparation for surgery (n=21) and recovery after surgery (n=23). They were formulated into input prompts with 'prompt engineering'. Using the Patient Education Materials Assessment Tool-Printable (PEMAT-P) Auto-Scoring Form, four ophthalmologists independently graded ChatGPT-4 and Google Bard responses. The readability of responses was evaluated using a Flesch-Kincaid calculator. Responses were also subjectively examined for any inaccurate or harmful information.</p><p><strong>Results: </strong>Google Bard had a higher mean overall Flesch-Kincaid Level (8.02) compared with ChatGPT-4 (5.75) (p<0.001), also noted across all three domains. ChatGPT-4 had a higher overall PEMAT-P understandability score (85.8%) in comparison to Google Bard (80.9%) (p<0.001), which was also noted in the 'preparation for cataract surgery' (85.2% vs 75.7%; p<0.001) and 'recovery after cataract surgery' (86.5% vs 82.3%; p=0.004) domains. There was no statistically significant difference in overall (42.5% vs 44.2%; p=0.344) or individual domain actionability scores (p>0.10). None of the generated material contained dangerous information.</p><p><strong>Conclusion: </strong>In comparison to Google Bard, ChatGPT-4 fared better overall, scoring higher on the PEMAT-P understandability scale and exhibiting more faithfulness to the prompt engineering instruction. Since input prompts might vary from real-world patient searches, follow-up studies with patient participation are required.</p>\",\"PeriodicalId\":9286,\"journal\":{\"name\":\"BMJ Open Ophthalmology\",\"volume\":\"9 1\",\"pages\":\"\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2024-10-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11487885/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMJ Open Ophthalmology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1136/bmjophth-2024-001824\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"OPHTHALMOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Open Ophthalmology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjophth-2024-001824","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
Artificial intelligence chatbots as sources of patient education material for cataract surgery: ChatGPT-4 versus Google Bard.
Objective: To conduct a head-to-head comparative analysis of cataract surgery patient education material generated by Chat Generative Pre-trained Transformer (ChatGPT-4) and Google Bard.
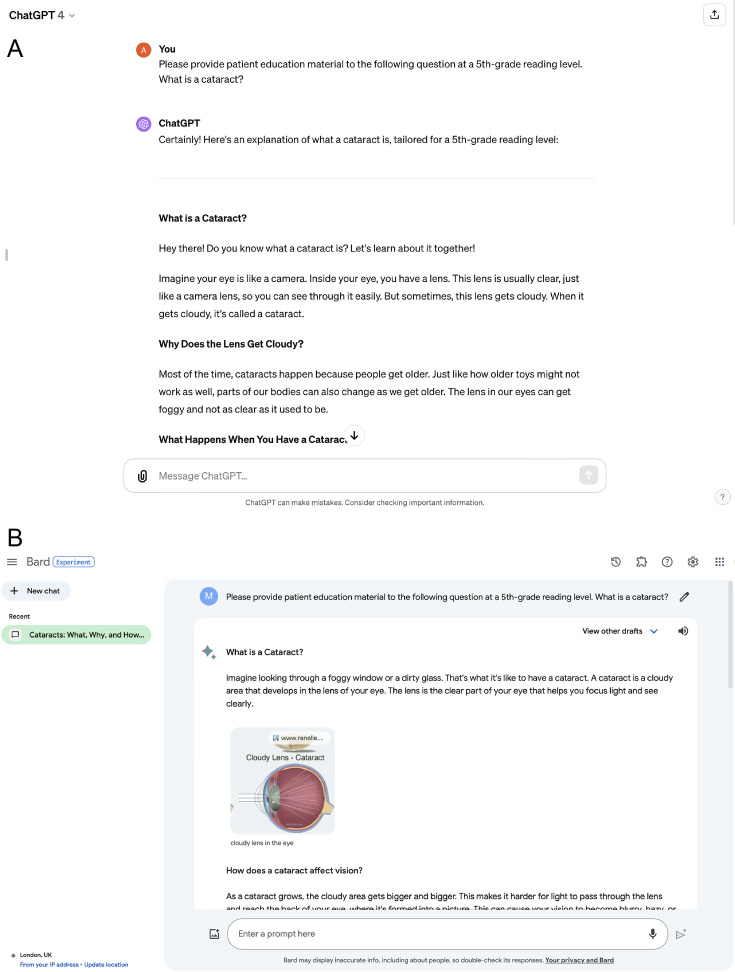
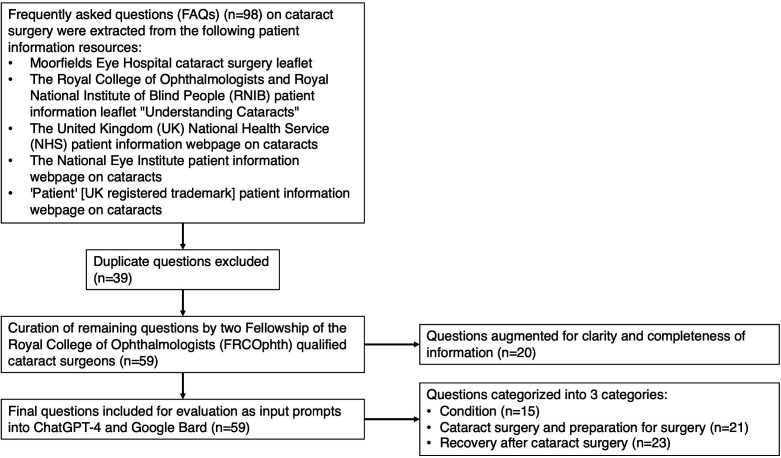
Methods and analysis: 98 frequently asked questions on cataract surgery in English were taken in November 2023 from 5 trustworthy online patient information resources. 59 of these were curated (20 augmented for clarity and 39 duplicates excluded) and categorised into 3 domains: condition (n=15), preparation for surgery (n=21) and recovery after surgery (n=23). They were formulated into input prompts with 'prompt engineering'. Using the Patient Education Materials Assessment Tool-Printable (PEMAT-P) Auto-Scoring Form, four ophthalmologists independently graded ChatGPT-4 and Google Bard responses. The readability of responses was evaluated using a Flesch-Kincaid calculator. Responses were also subjectively examined for any inaccurate or harmful information.
Results: Google Bard had a higher mean overall Flesch-Kincaid Level (8.02) compared with ChatGPT-4 (5.75) (p<0.001), also noted across all three domains. ChatGPT-4 had a higher overall PEMAT-P understandability score (85.8%) in comparison to Google Bard (80.9%) (p<0.001), which was also noted in the 'preparation for cataract surgery' (85.2% vs 75.7%; p<0.001) and 'recovery after cataract surgery' (86.5% vs 82.3%; p=0.004) domains. There was no statistically significant difference in overall (42.5% vs 44.2%; p=0.344) or individual domain actionability scores (p>0.10). None of the generated material contained dangerous information.
Conclusion: In comparison to Google Bard, ChatGPT-4 fared better overall, scoring higher on the PEMAT-P understandability scale and exhibiting more faithfulness to the prompt engineering instruction. Since input prompts might vary from real-world patient searches, follow-up studies with patient participation are required.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
