Florinel-Alin Croitoru , Vlad Hondru , Radu Tudor Ionescu , Mubarak Shah
{"title":"反向稳定扩散:生成这张图片时使用了什么提示?","authors":"Florinel-Alin Croitoru , Vlad Hondru , Radu Tudor Ionescu , Mubarak Shah","doi":"10.1016/j.cviu.2024.104210","DOIUrl":null,"url":null,"abstract":"<div><div>Text-to-image diffusion models have recently attracted the interest of many researchers, and inverting the diffusion process can play an important role in better understanding the generative process and how to engineer prompts in order to obtain the desired images. To this end, we study the task of predicting the prompt embedding given an image generated by a generative diffusion model. We consider a series of white-box and black-box models (with and without access to the weights of the diffusion network) to deal with the proposed task. We propose a novel learning framework comprising a joint prompt regression and multi-label vocabulary classification objective that generates improved prompts. To further improve our method, we employ a curriculum learning procedure that promotes the learning of image-prompt pairs with lower labeling noise (<em>i</em>.<em>e</em>. that are better aligned). We conduct experiments on the DiffusionDB data set, predicting text prompts from images generated by Stable Diffusion. In addition, we make an interesting discovery: training a diffusion model on the prompt generation task can make the model generate images that are much better aligned with the input prompts, when the model is directly reused for text-to-image generation. Our code is publicly available for download at <span><span>https://github.com/CroitoruAlin/Reverse-Stable-Diffusion</span><svg><path></path></svg></span>.</div></div>","PeriodicalId":50633,"journal":{"name":"Computer Vision and Image Understanding","volume":"249 ","pages":"Article 104210"},"PeriodicalIF":3.5000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Reverse Stable Diffusion: What prompt was used to generate this image?\",\"authors\":\"Florinel-Alin Croitoru , Vlad Hondru , Radu Tudor Ionescu , Mubarak Shah\",\"doi\":\"10.1016/j.cviu.2024.104210\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Text-to-image diffusion models have recently attracted the interest of many researchers, and inverting the diffusion process can play an important role in better understanding the generative process and how to engineer prompts in order to obtain the desired images. To this end, we study the task of predicting the prompt embedding given an image generated by a generative diffusion model. We consider a series of white-box and black-box models (with and without access to the weights of the diffusion network) to deal with the proposed task. We propose a novel learning framework comprising a joint prompt regression and multi-label vocabulary classification objective that generates improved prompts. To further improve our method, we employ a curriculum learning procedure that promotes the learning of image-prompt pairs with lower labeling noise (<em>i</em>.<em>e</em>. that are better aligned). We conduct experiments on the DiffusionDB data set, predicting text prompts from images generated by Stable Diffusion. In addition, we make an interesting discovery: training a diffusion model on the prompt generation task can make the model generate images that are much better aligned with the input prompts, when the model is directly reused for text-to-image generation. Our code is publicly available for download at <span><span>https://github.com/CroitoruAlin/Reverse-Stable-Diffusion</span><svg><path></path></svg></span>.</div></div>\",\"PeriodicalId\":50633,\"journal\":{\"name\":\"Computer Vision and Image Understanding\",\"volume\":\"249 \",\"pages\":\"Article 104210\"},\"PeriodicalIF\":3.5000,\"publicationDate\":\"2024-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer Vision and Image Understanding\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1077314224002911\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/19 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Vision and Image Understanding","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1077314224002911","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/19 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Reverse Stable Diffusion: What prompt was used to generate this image?
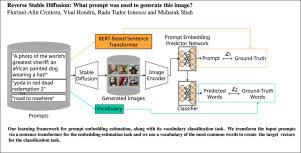
Text-to-image diffusion models have recently attracted the interest of many researchers, and inverting the diffusion process can play an important role in better understanding the generative process and how to engineer prompts in order to obtain the desired images. To this end, we study the task of predicting the prompt embedding given an image generated by a generative diffusion model. We consider a series of white-box and black-box models (with and without access to the weights of the diffusion network) to deal with the proposed task. We propose a novel learning framework comprising a joint prompt regression and multi-label vocabulary classification objective that generates improved prompts. To further improve our method, we employ a curriculum learning procedure that promotes the learning of image-prompt pairs with lower labeling noise (i.e. that are better aligned). We conduct experiments on the DiffusionDB data set, predicting text prompts from images generated by Stable Diffusion. In addition, we make an interesting discovery: training a diffusion model on the prompt generation task can make the model generate images that are much better aligned with the input prompts, when the model is directly reused for text-to-image generation. Our code is publicly available for download at https://github.com/CroitoruAlin/Reverse-Stable-Diffusion.
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
